







1. 底层数据结构, 与Redis Value Type之间的关系
对于Redis的使用者来说, Redis作为Key-Value型的内存数据库, 其Value有多种类型.
- String
- Hash
- List
- Set
- ZSet
这些Value的类型, 只是"Redis的用户认为的, Value存储数据的方式". 而在具体实现上, 各个Type的Value到底如何存储, 这对于Redis的使用者来说是不公开的.
举个粟子: 使用下面的命令创建一个Key-Value
SET "Hello" "World"
对于Redis的使用者来说, Hello这个Key, 对应的Value是String类型, 其值为五个ASCII字符组成的二进制数据. 但具体在底层实现上, 这五个字节是如何存储的, 是不对用户公开的. 即, Value的Type, 只是表象, 具体数据在内存中以何种数据结构存放, 这对于用户来说是不必要了解的.
Redis对使用者暴露了五种Value Type, 其底层实现的数据结构有8种, 分别是:
- SDS - simple dynamic string - 支持自动动态扩容的字节数组
- list - 平平无奇的链表
- dict - 使用双哈希表实现的, 支持平滑扩容的字典
- zskiplist - 附加了后向指针的跳跃表
- intset - 用于存储整数数值集合的自有结构
- ziplist - 一种实现上类似于TLV, 但比TLV复杂的, 用于存储任意数据的有序序列的数据结构
- quicklist - 一种以ziplist作为结点的双链表结构, 实现的非常苟
- zipmap - 一种用于在小规模场合使用的轻量级字典结构
而衔接"底层数据结构"与"Value Type"的桥梁的, 则是Redis实现的另外一种数据结构: redisObject. Redis中的Key与Value在表层都是一个redisObject实例, 故该结构有所谓的"类型", 即是ValueType. 对于每一种Value Type类型的redisObject, 其底层至少支持两种不同的底层数据结构来实现. 以应对在不同的应用场景中, Redis的运行效率, 或内存占用.
2. 底层数据结构
2.1 SDS - simple dynamic string
这是一种用于存储二进制数据的一种结构, 具有动态扩容的特点. 其实现位于src/sds.h与src/sds.c中, 其关键定义如下:
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
SDS的总体概览如下图:

其中sdshdr是头部, buf是真实存储用户数据的地方. 另外注意, 从命名上能看出来, 这个数据结构除了能存储二进制数据, 显然是用于设计作为字符串使用的, 所以在buf中, 用户数据后总跟着一个\0. 即图中 “数据” + “\0” 是为所谓的buf
SDS有五种不同的头部. 其中sdshdr5实际并未使用到. 所以实际上有四种不同的头部, 分别如下:
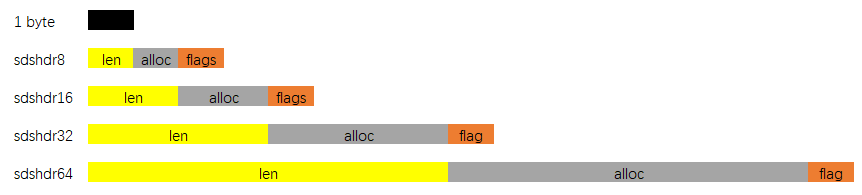
- len分别以uint8, uint16, uint32, uint64表示用户数据的长度(不包括末尾的\0)
- alloc分别以uint8, uint16, uint32, uint64表示整个SDS, 除过头部与末尾的\0, 剩余的字节数.
- flag始终为一字节, 以低三位标示着头部的类型, 高5位未使用.
当在程序中持有一个SDS实例时, 直接持有的是数据区的头指针, 这样做的用意是: 通过这个指针, 向前偏一个字节, 就能取到flag, 通过判断flag低三位的值, 能迅速判断: 头部的类型, 已用字节数, 总字节数, 剩余字节数. 这也是为什么sds类型即是char *指针类型别名的原因.
创建一个SDS实例有三个接口, 分别是:
// 创建一个不含数据的sds:
// 头部 3字节 sdshdr8
// 数据区 0字节
// 末尾 \0 占一字节
sds sdsempty(void);
// 带数据创建一个sds:
// 头部 按initlen的值, 选择最小的头部类型
// 数据区 从入参指针init处开始, 拷贝initlen个字节
// 末尾 \0 占一字节
sds sdsnewlen(const void *init, size_t initlen);
// 带数据创建一个sds:
// 头部 按strlen(init)的值, 选择最小的头部类型
// 数据区 入参指向的字符串中的所有字符, 不包括末尾 \0
// 末尾 \0 占一字节
sds sdsnew(const char *init);
- 所有创建sds实例的接口, 都不会额外分配预留内存空间
sdsnewlen用于带二进制数据创建sds实例, sdsnew用于带字符串创建sds实例. 接口返回的sds可以直接传入libc中的字符串输出函数中进行操作, 由于无论其中存储的是用户的二进制数据, 还是字符串, 其末尾都带一个\0, 所以至少调用libc中的字符串输出函数是安全的.
在对SDS中的数据进行修改时, 若剩余空间不足, 会调用sdsMakeRoomFor函数用于扩容空间, 这是一个很低级的API, 通常情况下不应当由SDS的使用者直接调用. 其实现中核心的几行如下:
sds sdsMakeRoomFor(sds s, size_t addlen) {
...
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
...
}
可以看到, 在扩充空间时
- 先保证至少有addlen可用
- 然后再进一步扩充, 在总体占用空间不超过阈值
SDS_MAC_PREALLOC时, 申请空间再翻一倍. 若总体空间已经超过了阈值, 则步进增长SDS_MAC_PREALLOC. 这个阈值的默认值为1024 * 1024
SDS也提供了接口用于移除所有未使用的内存空间. sdsRemoveFreeSpace, 该接口没有间接的被任何SDS其它接口调用, 即默认情况下, SDS不会自动回收预留空间. 在SDS的使用者需要节省内存时, 由使用者自行调用:
sds sdsRemoveFreeSpace(sds s);
总结:
- SDS除了是某些Value Type的底层实现, 也被大量使用在Redis内部, 用于替代C-Style字符串. 所以默认的创建SDS实例接口, 不分配额外的预留空间. 因为多数字符串在程序运行期间是不变的. 而对于变更数据区的API, 其内部则是调用了 sdsMakeRoomFor, 每一次扩充空间, 都会预留大量的空间. 这样做的考量是: 如果一个SDS实例中的数据被变更了, 那么很有可能会在后续发生多次变更.
- SDS的API内部不负责清除未使用的闲置内存空间, 因为内部API无法判断这样做的合适时机. 即便是在操作数据区的时候导致数据区占用内存减少时, 内部API也不会清除闲置内在空间. 清除闲置内存空间责任应当由SDS的使用者自行担当.
- 用SDS替代C-Style字符串时, 由于其头部额外存储了数据区的长度信息, 所以字符串的求长操作时间复杂度为O(1)
2.2 list
这是普通的链表实现, 链表结点不直接持有数据, 而是通过void *指针来间接的指向数据. 其实现位于 src/adlist.h与src/adlist.c中, 关键定义如下:
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
其内存布局如下图所示:
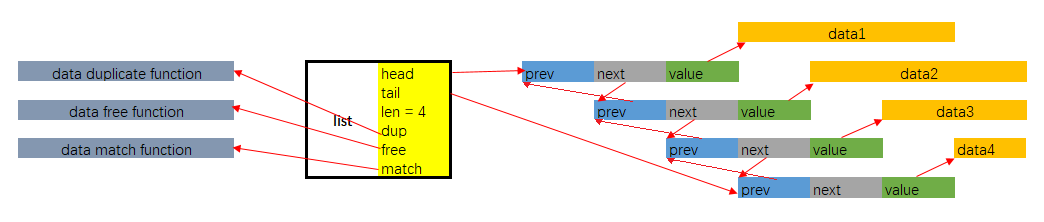
这是一个平平无奇的链表的实现. list在Redis除了作为一些Value Type的底层实现外, 还广泛用于Redis的其它功能实现中, 作为一种数据结构工具使用. 在list的实现中, 除了基本的链表定义外, 还额外增加了:
- 迭代器
listIter的定义, 与相关接口的实现. - 由于list中的链表结点本身并不直接持有数据, 而是通过value字段, 以void *指针的形式间接持有, 所以数据的生命周期并不完全与链表及其结点一致. 这给了list的使用者相当大的灵活性. 比如可以多个结点持有同一份数据的地址. 但与此同时, 在对链表进行销毁, 结点复制以及查找匹配时, 就需要list的使用者将相关的函数指针赋值于list.dup, list.free, list.match字段.
2.3 dict
dict是Redis底层数据结构中实现最为复杂的一个数据结构, 其功能类似于C++标准库中的std::unordered_map, 其实现位于 src/dict.h 与 src/dict.c中, 其关键定义如下:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemas 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6821
6821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









