




 本文介绍了一个使用Python爬取猫眼电影榜单的实例,包括网页请求、正则表达式解析、多进程爬取等内容,并解决了爬虫过程中常见的问题。
本文介绍了一个使用Python爬取猫眼电影榜单的实例,包括网页请求、正则表达式解析、多进程爬取等内容,并解决了爬虫过程中常见的问题。
1.代码如下
# -*- coding:utf-8 -*-
import requests
import re
from requests.exceptions import RequestException
import json
from multiprocessing import Pool
def get_one_page(url):
try:
reponse = requests.get(url)
# 200表示请求成功,HTTP状态码,表
# 示网络请求成功的意思
# ,返回这个状态表示已经获取到数据了
if reponse.status_code == 200:
return reponse.text
return None
except RequestException:
return None
def parse_one_page(html):
# pattern = re.compile('<img.*?src="(.*?)".*?alt="(.*?)".*?/>',re.S)
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S)
items = re.findall(pattern,html)
for item in items:
yield{
'index':item[0],
'image':item[1],
'title':item[2],
'actor':item[3].strip()[3:],
'date':item[4].strip()[5:],
'score':item[5]+item[6]
}
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False) + '\n')
f.close()
def main(offset):
url = "https://maoyan.com/board/4?offset="+str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
write_to_file(item)
# print(html)
if __name__ == '__main__':
# for i in range(10):
# main(i*10)
pool = Pool()
pool.map(main,[i*10 for i in range(10)])
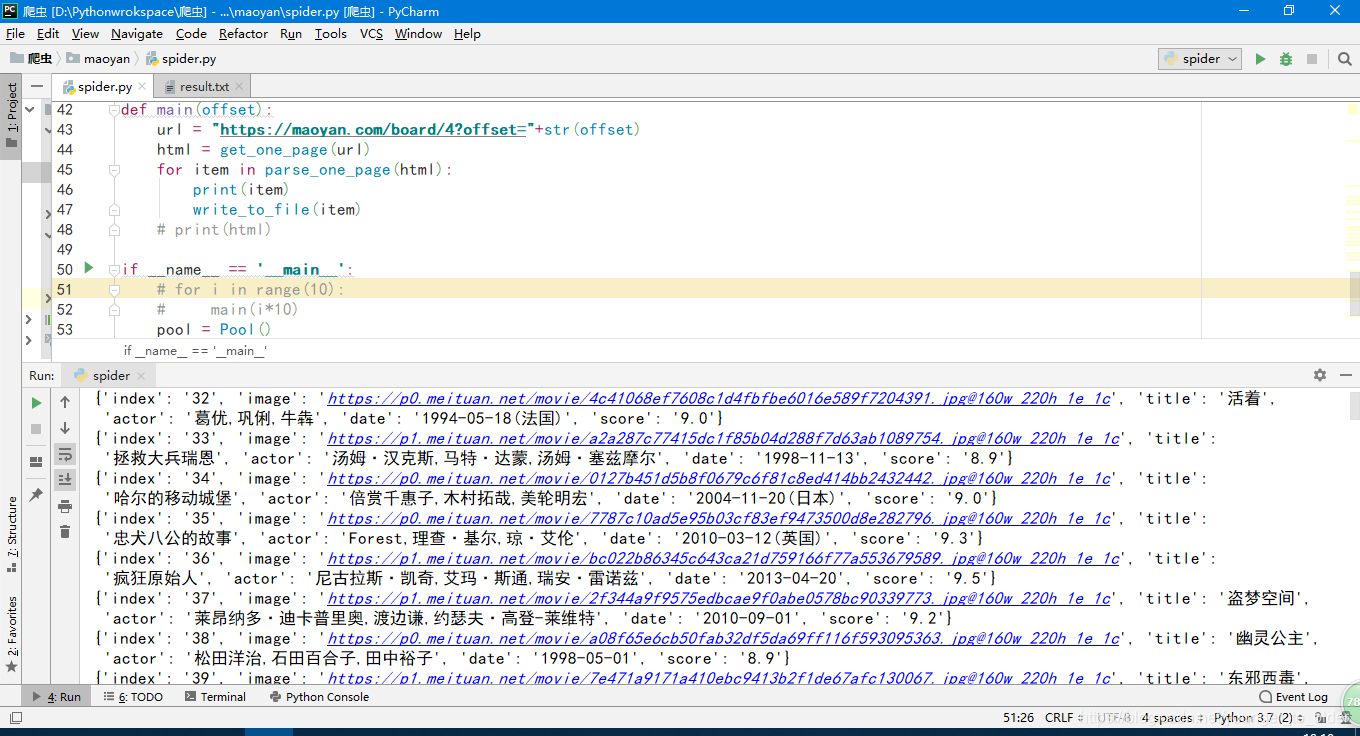
2.解释
pattern = re.compile('。。。。。。',re.S)文本中有换行要加re.S,不加会导致不能换行而爬虫失败
将爬取的内容写入到 .py文件的当前目录。
通过json.dumps () 将之前以字典形式获取的数据转化为字符串,然后写入文件,但是此时字符串是以ascii形式存储的
def write_to_file(content):
with open('result.txt','a',) as f:
f.write(json.dumps(content) + '\n')
f.close()
解决方法,如下:
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False) + '\n')
f.close()
启动线程池,通过map方法将函数中的每一个元素当做map()的参数,然后创建一个个进程放到线程池中,从而创建多个线程进行爬虫
。
线程池提供指定数量的进程,如果池没满的话就会创建进程,当进程池满时的就会等待
pool = Pool()
pool.map(main,[i*10 for i in range(10)])
3.中途遇到的错有有如下:

在正则表达式中要注意几点
(1)每个链接都是用 “” 围起来的,所以再爬取链接的时候注意带上分号,如:
<img data-src="https://p1.meituan.net/movie/2c0a5fedf4b43d142121b91c6ccabe1b59051.jpg@160w_220h_1e_1c" alt="一一" class="board-img" />
那么爬取这部分的链接的正则为(忘记规则的话,看一下另一篇博客)
*?data-src="(.*?)".*
(2)正则表达式中如果各部分的逻辑的语法没错,但是还是没有结果,那么应该看一下表达式中的符号是否写错或写漏,如(\d+)可能粗心写成(/d+),然后就是“”
(3)爬取有结果但是字典中的值为空,则表示正则表达式中在某个错误的前面的表达式是正确的,在错误的后面表达式是错误的,所以会出现匹配到结果但是值为空
1)看
2)删除片段试

















 3909
3909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









