 区块链扩容:Layer1、Layer2 与测试链解析
区块链扩容:Layer1、Layer2 与测试链解析





引言
在区块链世界中,性能与成本一直是制约大规模应用落地的关键瓶颈。Layer1 作为底层公链,负责提供最核心的安全性与去中心化,但随着用户和应用数量的增加,交易速度慢、手续费高等问题日益凸显。为了解决这一挑战,出现了 Layer2 等扩展网络,它们通过将大量交易迁移到更高效的网络上执行,再将结果提交回 Layer1,从而实现性能和成本的双重优化。
理解 Layer1 与 Layer2 的关系、常见公链与扩展网络的生态,以及测试网的作用,将帮助我们更好地把握区块链技术发展的脉络,也为 DApp 开发和链上应用创新打下坚实基础。
一、Layer1 & Layer2 基础概念
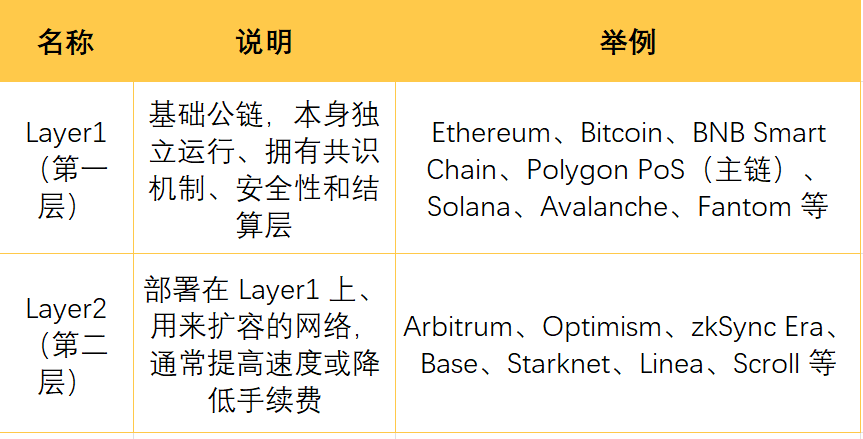
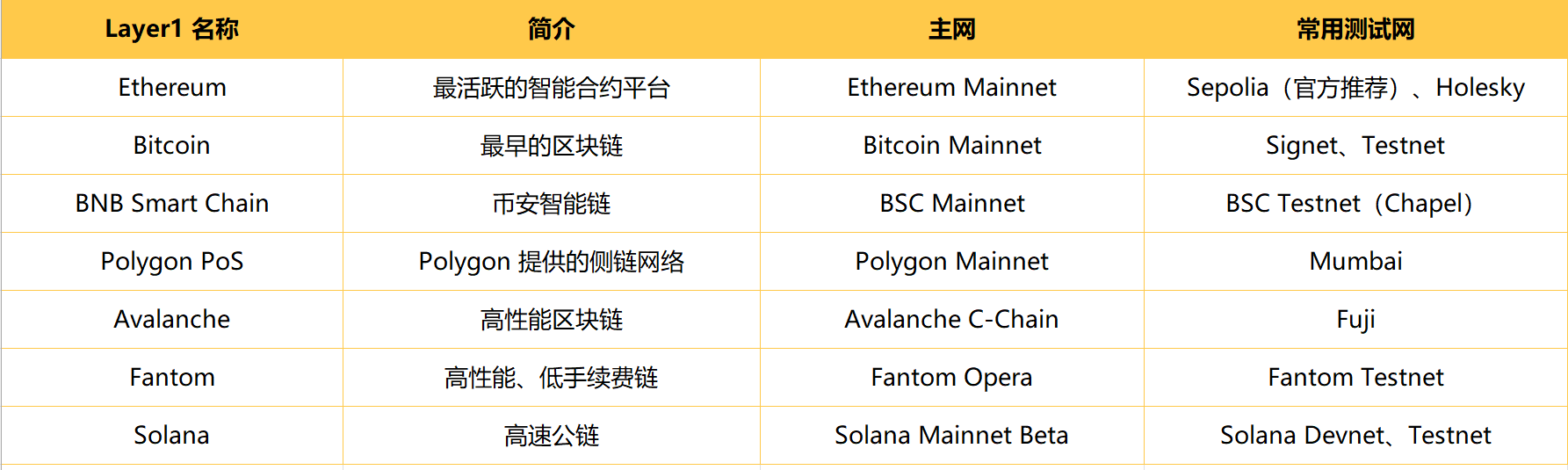
二、常见 Layer1 和 Layer2 以及分别属于哪条链
Layer1 公链(有自己主链和生态)
Layer2(大部分属于以太坊生态)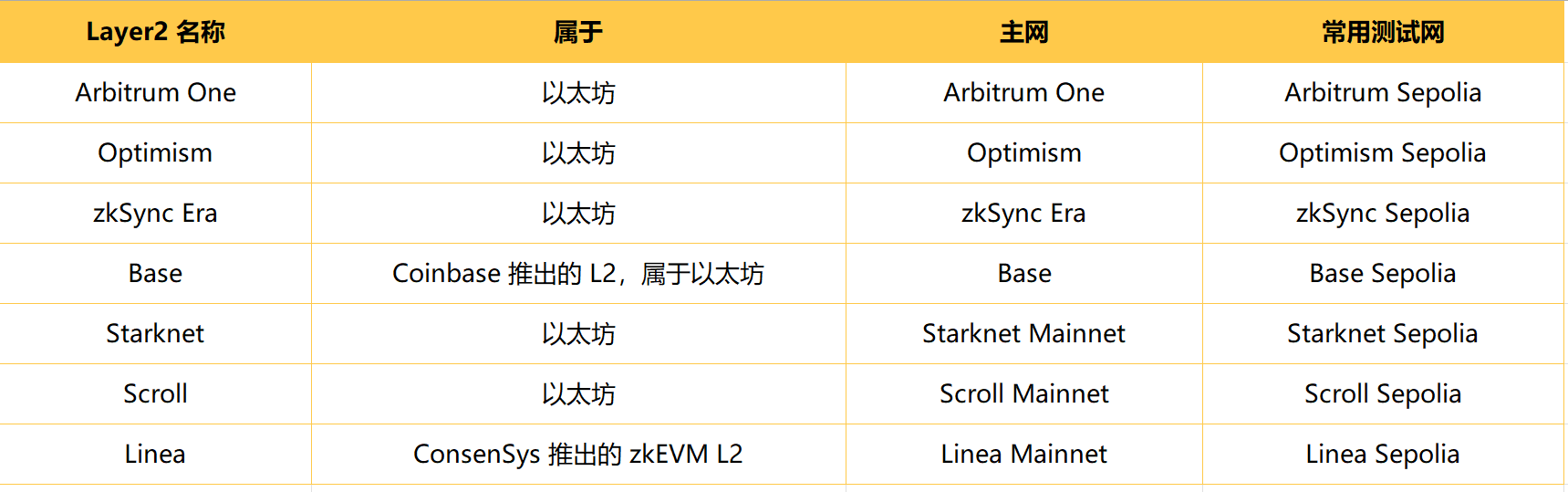
三、测试链 & 测试网 是什么关系?
其实是同一个概念:
测试链(Test Chain)就是运行在测试环境的区块链网络,用来开发、测试,而不消耗真实资产。测试网(Testnet)是对用户侧的说法:我们把测试链叫做“测
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










