




 本文详细解释了Shapefile中字符编码的复杂性,包括LDID和CPG文件的作用,ArcGIS的优先级,以及解决乱码问题的方法,如创建CPG文件和修改注册表中的dbfDefault设置。同时提到了字符截断问题和工作绕行解决方案。
本文详细解释了Shapefile中字符编码的复杂性,包括LDID和CPG文件的作用,ArcGIS的优先级,以及解决乱码问题的方法,如创建CPG文件和修改注册表中的dbfDefault设置。同时提到了字符截断问题和工作绕行解决方案。
关于乱码
乱码主要出现在 SHP 格式中,这种文件格式比较古早,字段名长度最多只能有 10 个字节,字节≠字数,这涉及编码问题,我们常用的编码有两种:UTF-8 和 GBK
UTF-8:一个英文字母占 1 字节,一个汉字占 3 字节,这意味着该编码下的字段名最多 3 个汉字。
GBK(CP936):英文字母占 1 字节,汉字占 2 字节,这就可以让字段名支持最多 5 个汉字。
看起来是 GBK 更有优势,但实际上 UTF8 有更好的兼容性,几乎不会出现乱码,如果对字段名中文长度没有特别要求,建议采取 UTF8 编码 ,这也是导出SHP的默认设置。
如果 GBK 导出的 SHP 加载到 ArcGIS 中出现乱码,这可能并不是数据有问题,而是软件原因,ArcGIS 10.2 及以上的版本中汉字经常乱码,可尝试按照下面的方式处理(以 ArcGIS 10.2.1 为例):
1.下载官方补丁并安装: ArcGIS-1021-DT-SSDCP-Patch.mspopen in new window;https://downloads.esri.com/Support/downloads/other_/ArcGIS-1021-DT-SSDCP-Patch.msp
2.新建一个 bat 文件,如:ChangeCodePage.bat,粘贴下面的代码并保存;
@ECHO OFF
IF "%1"=="" GOTO :EOF
reg add HKEY_CURRENT_USER\Software\ESRI\Desktop10.2\Common\CodePage /v dbfDefault /t REG_SZ /d 936 /f
3.以管理员权限执行上面的文件。
4.注意,针对不同版本的ArcGIS ,需要修改 ..\Desktop10.2 到你的版本(比如你的版本是10.7,那么10.2就需要改为10.7)。
或者下面的方案:
shp数据格式与其他数据格式转换过程中会遇到乱码等问题,原因如下:
在Shapefile头文件(dBase Header)中,一般会包含字符编码信息,这个信息称为 LDID ( Language Driver ID)。在使用arcgis 打开Shapefile时,会读取LDID 存储的字符编码信息,再打开 shapefile。
在Shapefile子文件中,有时我们还会发现同名 *.CPG 文件,该文件中也存储了字符编码信息,用记事本打开该文件,可以看到 UTF-8或者OEM字样。
二者被ArcGIS 识别的优先顺序是:LDID 优先于 CPG文件。也就是说,如果在Shapefile头文件中没有约定字符编码方式时,那么ArcGIS会使用.CPG设置的字符编码方式打开shapefile。
如果shapefile文件缺失 LDID 或者.CPG 文件,那么编码类型就会使用OEM编码类型,也就是操作系统默认编码类型(操作系统默认编码是个很神奇的编码,变数很多,比如:ANSI、mul-Language多国语言版,还有不同操作系统、同一操作系统不同编码类型的区别)。换句话说,此时操作系统使用什么样的编码方式,那么Shapefile也会使用相同的编码方式。如果Shapefile使用的编码方式与操作系统默认编码方式不一致,那么就会出现乱码。
一般而言, shapefiles 和 dBASE 文件都会存储字符编码信息, 但有些程序 OEM 文件没有包含字符编码页信息(例如: Microsoft Access 2000 and Excel 2000),程序会给没有编码页信息的文件设置为操作系统默认OEM 编码,字符就会出现乱码。
在 ArcGIS Desktop (ArcMap, ArcCatalog, and ArcToolbox) 中,利用编码页转换功能可以读写多种字符编码的 shapefile 和 dBASE 表。在系统注册表中,编码页转换功能命名为 'dbfDefault',可以修改这个值。
dbfDefault。
写
在注册表中设置 ‘dbfDefault’ ,可以决定导出的 shapefile 和 dBASE 的编码类型。例如,把 ‘dbfDefault’ 设置为 OEM ,那么用 ArcMap, ArcCatalog, ArcToolbox 生成出来的 shapefile 和 dBASE 文件就是以 OEM编码的,设置成 ANSI ,那 shapefile 和 dBASE 文件就是 ANSI 编码的。
读
读 shapefile 和 dBASE 文件的逻辑与写是相同的,如果缺失编码信息,ArcGIS 读取文件的编码类型由 dbfDefault决定。
我们知道 shapefile 是个开放格式,只要你了解了数据规范,完全可以脱离ArcGIS自己生产出来。在Windows中文语言设置下,假设你自己写代码或者使用第三方的程序生产了shapefile,例如MapGIS,默认使用 CP936(GBK)编码存储,但是无论粗心大意还是有意为之没有在数据头文件中约定“我用了936!”。如果是 ArcGIS 10.2 和之前的版本,那么没问题,ArcGIS 默认就是以这种方式识别,没有乱码。可是拿到 ArcGIS 10.2.1 ,ArcGIS 10.2.2,ArcGIS 10.3.x 这几个版本中发现乱!码!了!在缺失 LDID 和 CPG时,这几个版本默认使用 UTF-8 来读取 shapefile,这样必然乱码。
解决方法

在shapefile子文件旁边创建个记事本,修改为同名的CPG文件,文本内容oem、936或者UTF-8。
再次打开,没有乱码。
假定你的shapefile编码方式是UTF-8的,而LDID 和 CPG编码信息有是丢失的,那么还是按照上面的步骤,创建一个同名的CPG文件,写入UTF-8,保存。
二、字符截断问题
ArcGIS 10.2 以及更早的版本,ArcGIS写shapefile的时候,遇到中文默认使用Windows当前语言 字符集编码(也称 代码页/CodePage/OEM CodePage),例如中文一般使用的是 CodePage 936(GBK)。
ArcGIS 10.2.1 以及之后的版本,ArcGIS写shapefile的时候,默认使用的是 UTF-8 编码类型。
这两种编码类型存储汉字所使用的字节数是不相同的。其中,shapefile自身的限制是字段为9个字节,CP936编码下汉字通常为双字节存储,因此可以存储 9/2=4 个汉字;UTF-8 编码下汉字至少需要3个字节存储,因此最多只能存储 9/3=3 个汉字了。
解决方法
使用地理数据库,放弃shapefile,避免各种截断问题,这也是存储地理数据的康庄大道。
但是,shapefile的拥趸说“我的需求是恢复以前存储4个汉字的shapefile,我不想用地理数据库,我希望得到老版本的shapefile的结果,我不在乎shapefile的编码类型是什么 ……bla bla……”好吧,方法还是有的。
Workaround
这里还有个注意事项:
如果你用的刚好是 10.2.1 和10.2.2 这两个版本,那么要打补丁后以下设置才生效。以前写过另外一篇,详情点 这里。
如果你用的是 10.3.x ,那么直接向下进行。
打开注册表,定位到 ‘My Computer\HKEY_CURRENT_USER\Software\ESRI\Desktop 10.x‘
创建项 ‘Common‘, 接着在其下创建 ‘CodePage‘ 项, 添加 ‘字符串’,名称: dbfDefault,健值:oem(或者 936)。
这样ArcGIS Desktop 读、写 shapefile的默认方式就将是Windows当前语言 OEM CodePage 936。
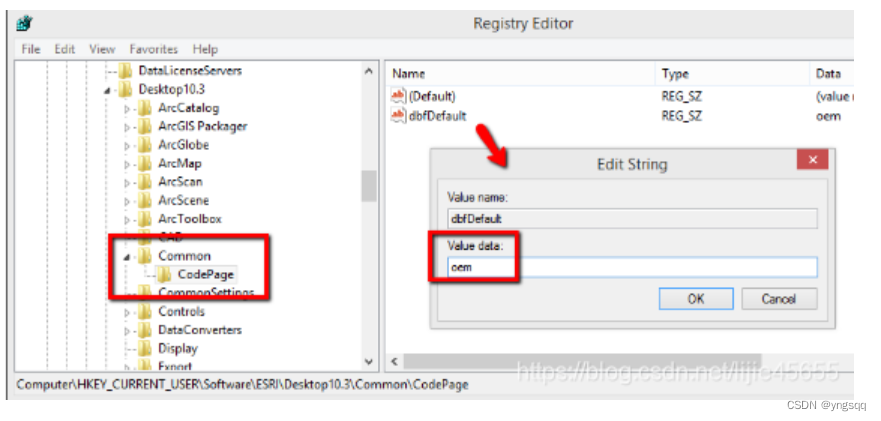
当然这种方法,也可以解决第一个问题,并且不需要为缺失oem编码信息的数据增加cpg文件了。两种方法,任君选择。
‘dbfDefault’ 设置方法
开始 – 运行,输入”Regedit“,打开 注册表。
如是用的是 10.x 版本 ArcGIS Desktop,定位到 My Computer\HKEY_CURRENT_USER\Software\ESRI\Desktop 10.x. 如果是9.3.1之前的版本,定位到 'My Computer\HKEY_CURRENT_USER\Software\ESRI'。
创建项 Common, 接着在其下创建 CodePage 项, 添加 字符串 ,名称: dbfDefault ,健值: oem (或者936)。
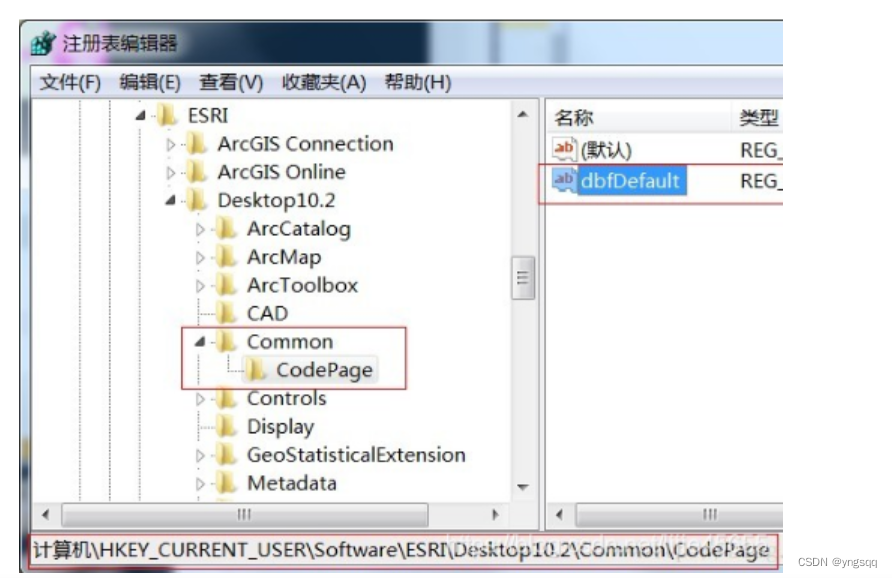
以下dbfDefault支持的字符编码值:
OEM Code Page Values:
OEM, 437, 708, 720, 737, 775, 850, 852, 855, 857, 860, 861, 862, 863, 864, 865, 866, 869, 932, 936, 950
ANSI Code Page Values:
ANSI, 1250, 1251, 1252, 1253, 1254, 1255, 1256, 1257, 1258, Big5, SJIS
ISO Code Page Values:
ISO, 88591, 88592, 88593, 88594, 88595, 88596, 88597, 88598, 88599, 885910, 885913, 885915, EUC
Unicode Values:
UTF-8
版权归原作者所有



















 3885
3885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











