







 本文通过一个Java中split()函数的实例引出正则表达式,介绍了正则表达式的三大基本符号:+ * . ?,并讲解了Java中处理正则的Pattern和Matcher类。同时,详细阐述了特殊字符如\d、\D、\s等的含义,并给出取出字符串中数字的案例。最后,提供了一个自定义邮箱正则表达式的例子。
本文通过一个Java中split()函数的实例引出正则表达式,介绍了正则表达式的三大基本符号:+ * . ?,并讲解了Java中处理正则的Pattern和Matcher类。同时,详细阐述了特殊字符如\d、\D、\s等的含义,并给出取出字符串中数字的案例。最后,提供了一个自定义邮箱正则表达式的例子。
文章目录
一、问题引入:
学过Java字符串的小伙伴一定知道split()这个函数,
它的功能是可以把字符串进行切分,然后存放到数组中,
就像下面这个例子的用法,
但是,这次的结果好像出了一点问题……:
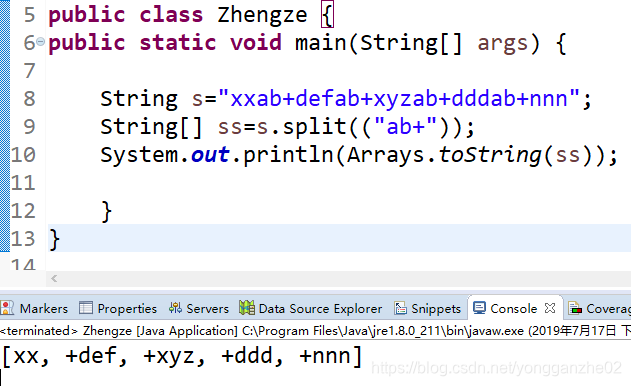
先来一句一句解释一下上面的例子,
String变量s是一个长长的字符串,
现在,我用split()函数将s进行分割,
然后把各部分,
放入名为ss的字符串数组,
这里选取分隔符“ab+”。
但是,结果并不是
[xx,def,xyz,ddd,nnn]
而是
[xx,+def,+xyz,+ddd,+nnn]
多出来的+号是怎么一回事呢?
答案揭晓:
原来是误打误撞到了Java的正则表达式,
那么现在,就让我们一起来学习一下吧。
二、你身边的正则表达式例子:
创建一个Oracle账户,鼠标刚离开,电脑怎么就知道邮箱无效?

准备手机登录,刚点击获取验证码,电脑怎么就知道号码格式错误?
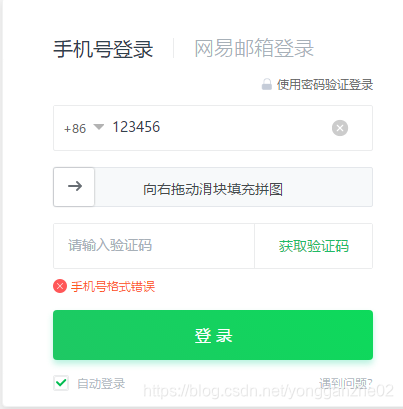
三、正则表达式针对字符串:
从上边两个例子,可以看出,
判断都是针对你输入的 字符串 :
你给电脑输入一个 字符串 ,
电脑分析一下,
之后告诉你,格式对不对。
电脑分析 字符串 的这种 方法 ,用的就是 正则表达式 。
四、用Java来学正则表达式:
上面说到,
电脑分析 字符串 的这种 方法 ,用的是 正则表达式 ,
那 正则表达式 又是什么呢?
正则表达式 也是 字符串,
特别的是,它是用一些 特殊 意义的字符组成的 字符串。
打个比方:正则表达式就像是一本法典,
电脑用它去检查你输入的字符串是否合法合规。
Java、Javascript、PHP、Python语言中都有正则表达式这一功能,只有稍许区别。
这里,我们就用Java来介绍总结一下吧。
1.三大符号:+ * . ?
以下一个符号代表前面的字符重复的次数:
+ ----> 出现1次或多次
* ----> 出现0次1次或多次
? ---->出现0次或1次
解释:
a+ 表示a出现一次或多次,可以是a,也可以是aaaaa
bc? 表示b出现一次,c出现0次或1次,可以是b,也可以是bc
d*e 表示d出现0次1次或多次,e出现1次,可以是e,也可以是de。也可以是ddde
光看概念可能有点模糊,我们来看引言中的例子:
引言中的例子就是因为
+号被赋予了上面的含义(代表+之前的字符出现1次或多次)。
本例中,我就是想仅仅输出+号本身,
怎么办呢?
各个语言中直接输出需用到转移字符,
转移字符也就是反斜线(\)
所以+就需要写成 \+
但要注意的是,\ 本身也需要转移,
所以 \ 就需要写成 \\
本例中最终要写成 \\+
修改代码如下:
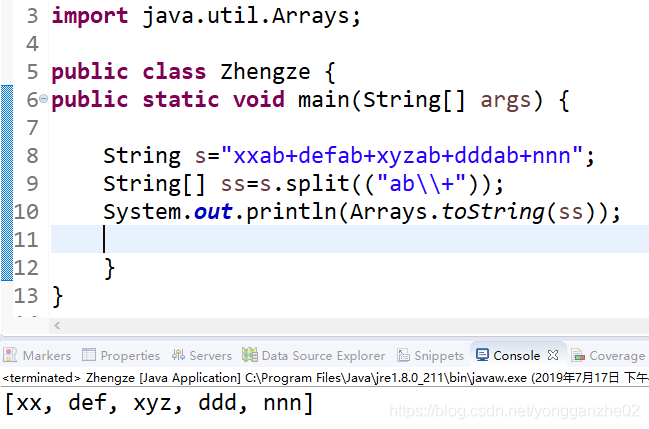
结果达到了我们的预期。
2.Java中关于正则表达式的类:
学完了三大符号,接下来看Java为正则表达式提供的类,
这里主要讲两个Java常用的正则表达式的类,
它们是:
java.util.regex.Pattern 和 java.util.regex.Matcher类
regex 的中文意思就是正则表达式,
可以看出,它是java.util包下的一个类,
而今天要讲的 Pattern 和 Matcher 都是regex的子类,
它们的作用是:
对给定的字符串进行正则判断。
从jdk8的 api 可以看到对他们的介绍:
api链接:https://pan.baidu.com/s/1vrHT1DYeb6RRrj4WgB4hvA
提取码:aosa
java.util.regex.Pattern如下:
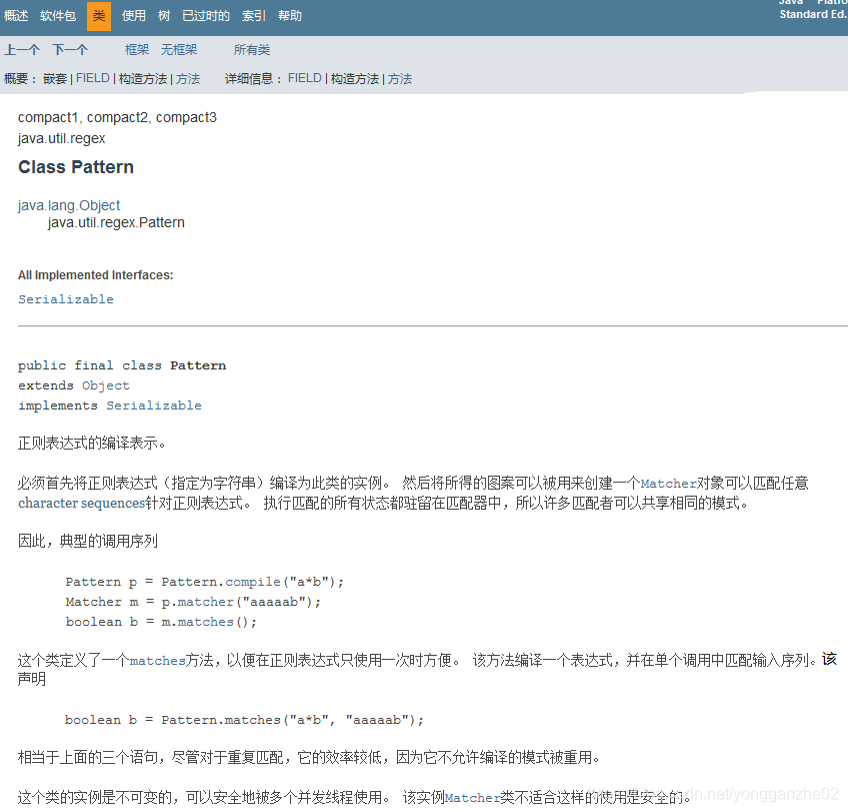
java.util.regex.Matcher如下:
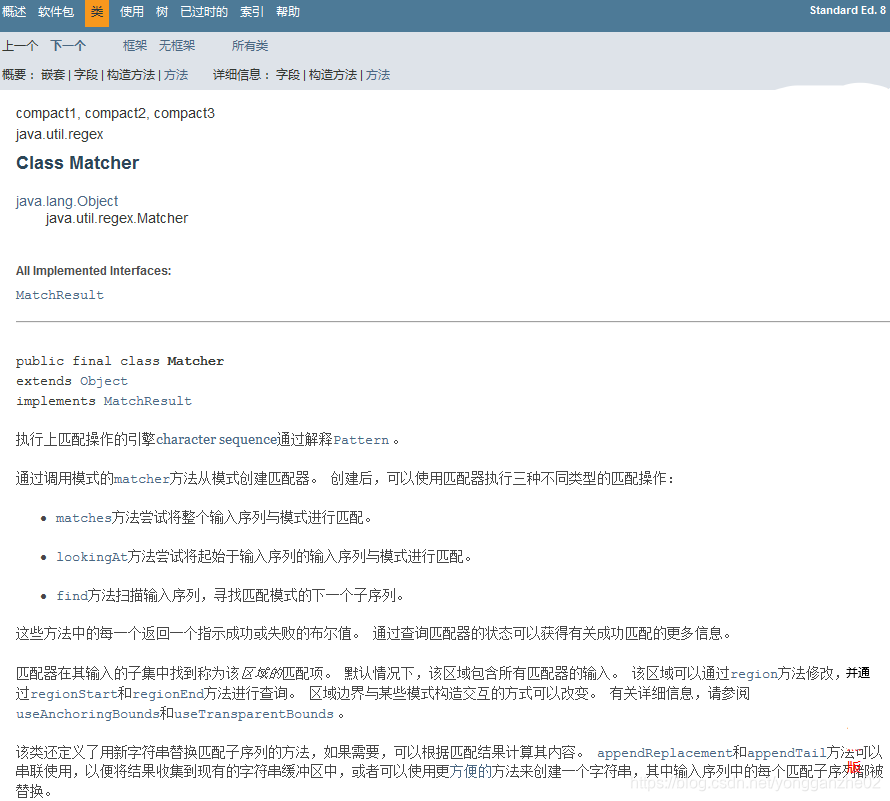
文档中给出了它们最基本的调用形式,
我们照猫画虎编写代码,
就可以对某字符串进行正则判断了。
①使用案例一:
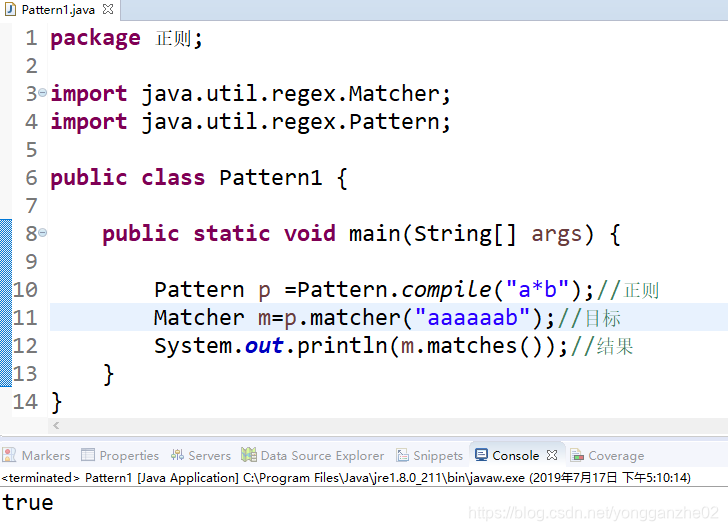
Pattern p =Pattern.compile("a*b");
这句话创建了p1对象但是没有new构造函数,
翻了翻Pattern文档发现,Pattern类并没有构造函数,
但compile是静态方法,我们可以通过类名直接调用。
这句话给定了正则表达式的模板。
Matcher m=p1.matcher("aaaaaab");
这句话创建了Matcher的对象,
同样调用了Pattern的matvher静态方法,
作用是输入需要进行检查的字符串对象。
System.out.println(m.matches());
这句话输出比较的结果。
②使用案例二:
我们还可以在一个长字符串中,找出符合正则的子串,如下:
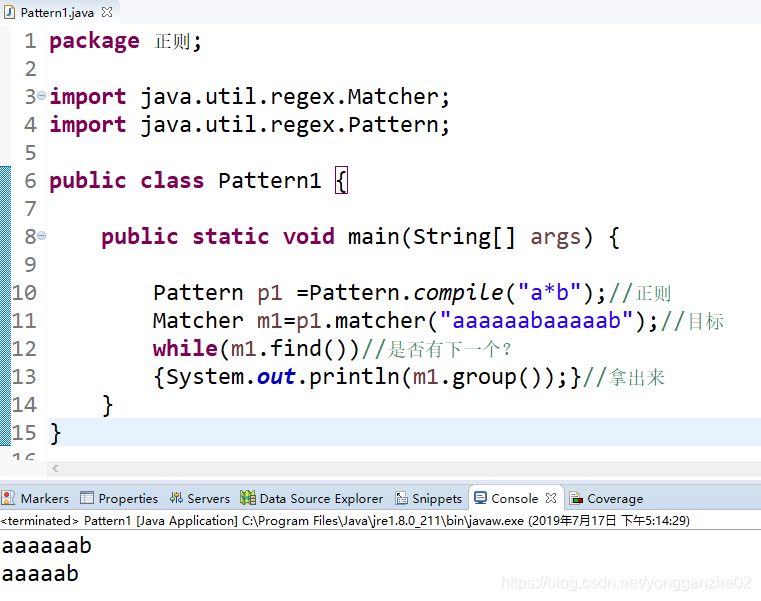
while(m1.find())
从前往后寻找,能否找到下一个匹配的字串,直到退出循环。
System.out.println(m1.group());
拿出这个子串。
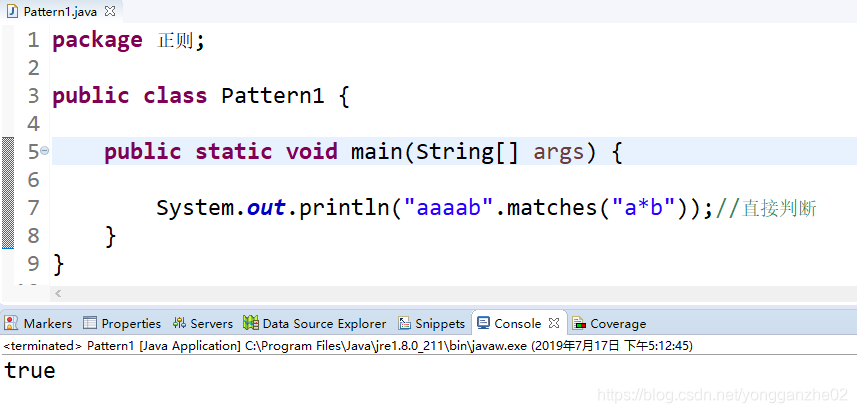
③使用案例三:
当然也可以简单点,直接判断:
3.wsd和自定义:
前面我们学习了三大符号,还学习了调用类来进行判断的方法,
接下来,我们还有最后一部分符号的知识点:
以下一个符号代表一个字符:
\\d ---->数字0-9
\\D ----> 非数字
\\s ----> 空白
\\S ----> 非空白
\\w ----> 字母数字下划线
\\W ----> 非字母数字下划线
\\. ---->除了换行符\n之外的任意一个字符
{} ---->表示出现的次数
{m} ---->出现m次
{m,n} ---->出现m到n次,包含m和n
{m,} ---->最少出现m次,到无限多次
自定义:
[5-8] ---->数字5-8
[a-z5-8] ---->小写字母a-z和数字5-8
[^a-zA-z0-9]不是大写字母,不是小写字母,也不是零到九
解释:
\\d代表一位数字,相当于[0-9]
\\D代表一位非数字,相当于[^0-9]
\\s代表\n 或\r或 \t或 \f
\\S代表非上述空白
\\w代表[a-zA-Z0-9]
\\W代表[^a-zA-Z0-9]
案例:取出字符串中夹杂的数字

① 同学一的解答:
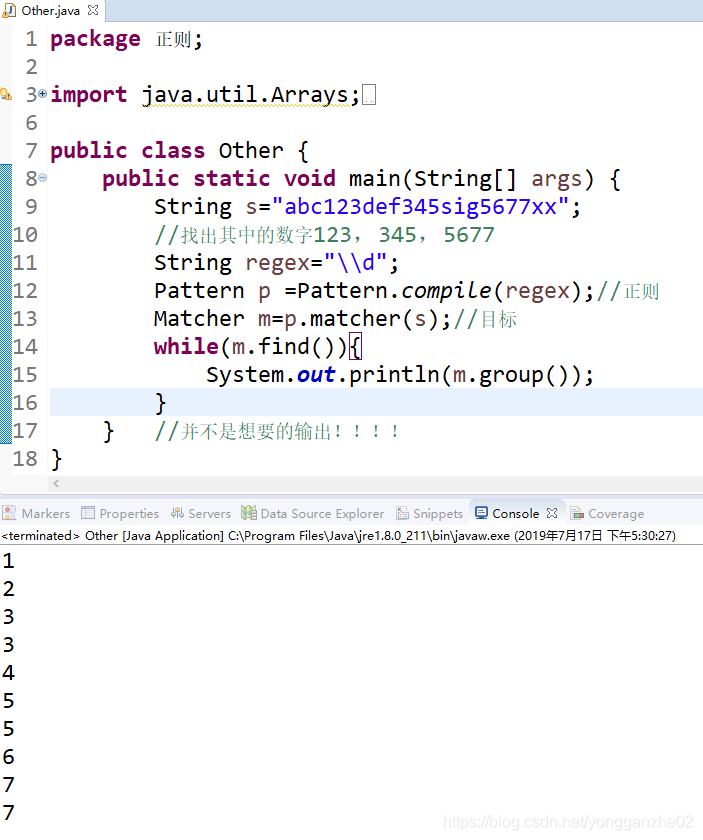
点评:同学一的解答拆开了单独数字,但并不是我们想要得到的数字。
② 同学二的解答:
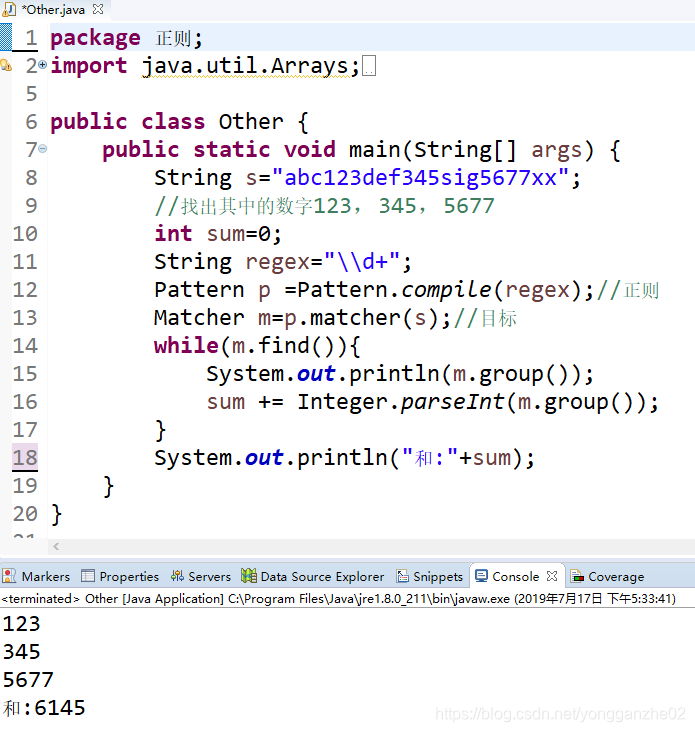
\d+ 遇到多个数字,提取子串
③ 同学三的解答:
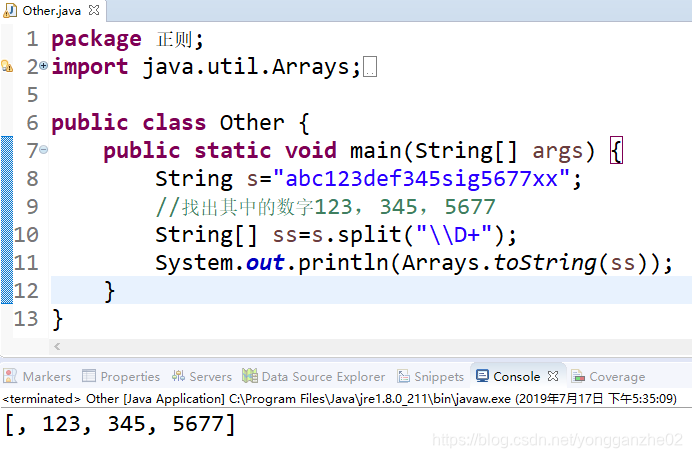
\\d+ 用非数字进行分割,把切片的数字放入数组
④ 同学四的解答:
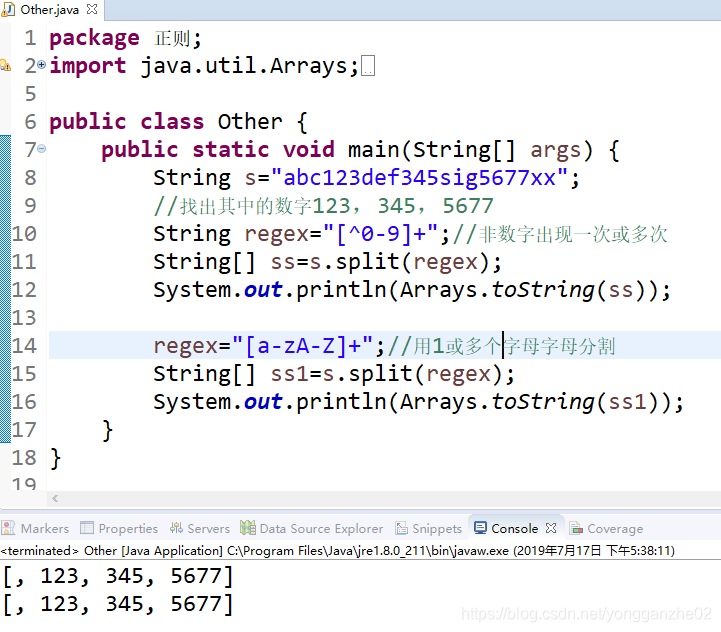
[^0-9]+ 用非数字进行分割,把切片的数字放入数组
[a-zA-Z]+ 用字母进行分割,把切片的数字放入数组
五、亲手试一试:
补充一个小知识点:
^ ---->必须以什么什么开头
$ ---->必须以什么什么结尾
| ---->表示或的关系
案例:自定义邮箱正则
某邮箱规则如下:
字母数字下划线开头,
之后跟数字字母下划线若干,
跟@,跟数字字母若干
跟.
跟字母若干
例如:
_zzj@2019.com
2019@ABC.com.cn
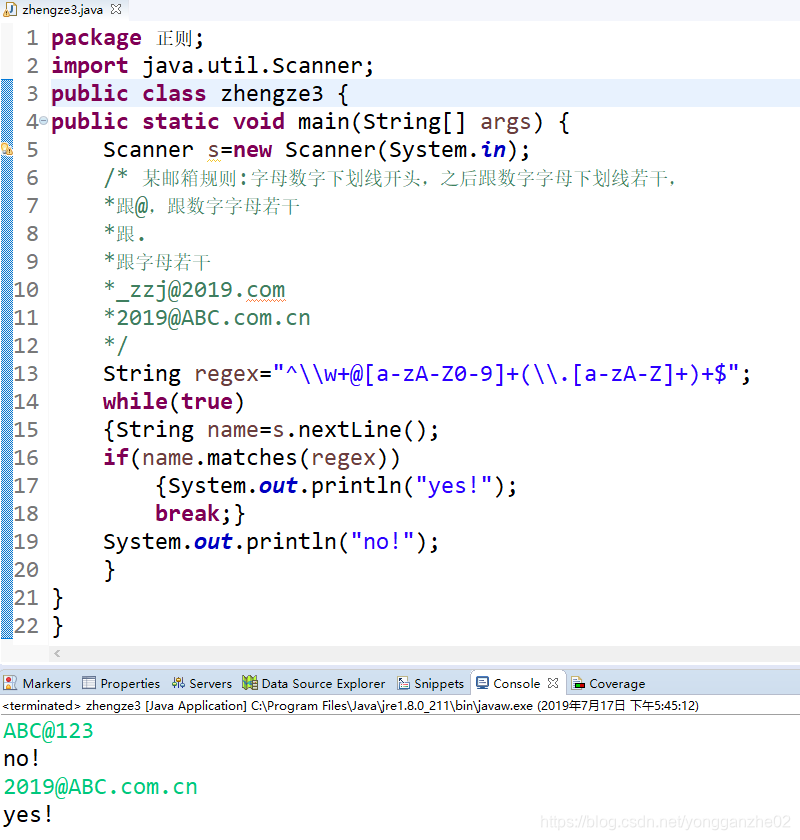
解析:
最后()中扩的是.字母,
使用()+表示.字母 这个整体出现一次或多次
注:此例子只做练习使用,在实际项目中,
如果要验证邮箱是否合法,
可以在网上寻找现成的正则表达式。
六、总结:(查找点这里)
+ ----> 出现1次或多次
* ----> 出现0次1次或多次
? ---->出现0次或1次\\d ---->数字0-9
\\D ----> 非数字
\\s ----> 空白
\\S ----> 非空白
\\w ----> 字母数字下划线
\\W ----> 非字母数字下划线
自定义:
[5-8] ---->数字5-8
[a-z5-8] ---->小写字母a-z和数字5-8
[^a-zA-z0-9]不是大写字母,不是小写字母,也不是零到九^ ---->必须以什么什么开头
$ ---->必须以什么什么结尾
| ---->表示或的关系

















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









