



前言
本文为深度学习和YOLO系列的初学者提供了一份关于YOLOv11中最基础、最核心的Conv/CBS模块的详细解析。Conv/CBS模块是YOLOv11网络的“基础积木”,由Conv2d(卷积层)、BatchNorm2d(批量归一化层)和SiLU(激活函数) 三部分组成。文章从模块的源码结构入手,逐步深入讲解了8个初始化参数的详细含义、各组成部分(卷积、BN、SiLU)的工作原理与数学公式,并通过前向传播流程分析和维度计算示例,帮助读者直观理解数据在模块中的变化过程。此外,文中还提供了手动实现BN和SiLU的代码,并包含常见问题解答,旨在帮助读者从根本上理解这一核心模块,为系统学习YOLOv11架构打下坚实基础
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
说明
本文基于版本:tag = 8.3.0,最早版本的YOLOv11代码,可能新版本有区别。但基本没啥影响。
什么是Conv/CBS模块?
Conv模块是YOLO11中最基础、最核心的卷积单元,也是大家常说的「CBS模块」—— 名字来源于它的三个核心组成:Conv2d + BatchNorm2d + SiLU。
你可以把它理解为YOLO11的「基础积木」:
- 🧱 Conv2d(卷积层):负责提取图像的局部特征(比如边缘、纹理、形状);
- 🧱 BatchNorm2d(批量归一化层):让训练过程更稳定、更快,避免模型“学偏”;
- 🧱 SiLU(激活函数):给特征添加“非线性”,让模型能学复杂规律,避免“神经元躺平”。
这个模块几乎出现在YOLO11的骨干网络、颈部网络、检测头中,是理解YOLO架构的第一步!
Conv模块源码与核心结构
先看YOLO11源码中Conv模块的定义,位置在 ultralytics/nn/modules/conv.py,代码不长但全是关键:
源码展示
class Conv(nn.Module):
# 默认激活函数:SiLU
default_act = nn.SiLU()
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
# 卷积层:bias=False(BN会吸收偏置,留着没用)
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
# 批量归一化层
self.bn = nn.BatchNorm2d(c2)
# 激活函数:True用默认SiLU,传自定义模块则用自定义,False/None则无激活
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
# 正常前向传播(训练/推理)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
# 推理加速版(BN融合到卷积后)
def forward_fuse(self, x):
return self.act(self.conv(x))
结构图解(初学者一看就懂)
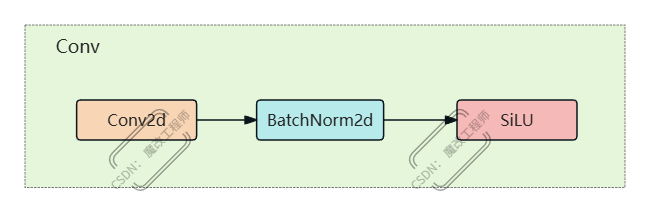
输入特征图 (通道数c1)
↓ 第一步:Conv2d卷积(提取局部特征)
↓ 第二步:BatchNorm2d归一化(稳定训练)
↓ 第三步:SiLU激活(添加非线性)
输出特征图 (通道数c2)
Conv模块参数全解析
Conv模块初始化有8个参数,其中2个必填,6个有默认值,下面用「人话」解释每个参数的作用:
| 参数 | 是否必填 | 默认值 | 通俗解释 |
|---|---|---|---|
c1 | ✅ 是 | - | 输入特征图的通道数(比如输入RGB图像时c1=3) |
c2 | ✅ 是 | - | 输出特征图的通道数(想让卷积输出多少个特征) |
k | ❌ 否 | 1 | 卷积核大小(比如k=3就是3×3的卷积核,越大看的区域越广) |
s | ❌ 否 | 1 | 卷积步长(s=1不缩小特征图,s=2特征图宽高减半) |
p | ❌ 否 | None | 填充值(默认自动填充autopad,保证特征图尺寸不变) |
g | ❌ 否 | 1 | 卷积分组数(g=1是普通卷积,g=c1是深度卷积,减少参数量) |
d | ❌ 否 | 1 | 膨胀系数(d>1是膨胀卷积,不用增大核也能扩大感受野) |
act | ❌ 否 | True | 激活函数:True=SiLU,传nn.ReLU()则用ReLU,False=无激活 |
💡 小提示:BN层的默认超参(
eps=1e-3、momentum=0.03)会在YOLO11初始化时全局设置,不用手动改~
核心组成层拆解
Conv模块的3个核心层各有作用,下面逐个拆解,从原理到实战,初学者也能懂:
4.1 Conv2d层(特征提取核心)
Conv2d是「特征提取器」,核心作用是从图像中抠出边缘、纹理、形状等基础特征。
4.1.1 输入输出尺寸计算
输入特征图形状:(N, c1, H_in, W_in)(N=批量数,c1=通道数,H/W=高/宽)
输出特征图尺寸公式(带地板函数,更精准):
H
o
u
t
=
⌊
H
i
n
+
2
×
p
[
0
]
−
d
[
0
]
×
(
k
[
0
]
−
1
)
−
1
s
[
0
]
+
1
⌋
H_{out} = \left\lfloor \frac{H_{in} + 2 \times p[0] - d[0] \times (k[0] - 1) - 1}{s[0]} + 1 \right\rfloor
Hout=⌊s[0]Hin+2×p[0]−d[0]×(k[0]−1)−1+1⌋
W
o
u
t
=
⌊
W
i
n
+
2
×
p
[
1
]
−
d
[
1
]
×
(
k
[
1
]
−
1
)
−
1
s
[
1
]
+
1
⌋
W_{out} = \left\lfloor \frac{W_{in} + 2 \times p[1] - d[1] \times (k[1] - 1) - 1}{s[1]} + 1 \right\rfloor
Wout=⌊s[1]Win+2×p[1]−d[1]×(k[1]−1)−1+1⌋
- 「⌊ ⌋」表示向下取整;
- 若k/p/d/s是数字(不是列表),说明横、纵方向参数相同(比如k=3就是3×3卷积);
- 示例:输入H_in=64,k=3,s=1,p=1,d=1 → H_out=64(尺寸不变);s=2则H_out=32(尺寸减半)。
4.1.2 分组卷积(减少参数量)
分组卷积是把输入/输出通道分成g组,每组独立卷积,能大幅减少参数量:
标准卷积的参数量为:
C
i
n
×
C
o
u
t
×
k
×
k
C_{in} \times C_{out} \times k \times k
Cin×Cout×k×k
分组卷积的参数量为:
(
C
i
n
g
)
×
(
C
o
u
t
g
)
×
g
×
k
×
k
=
C
i
n
×
C
o
u
t
g
×
k
×
k
=
C
i
n
×
C
o
u
t
×
k
×
k
g
\left( \frac{C_{in}}{g} \right) \times \left( \frac{C_{out}}{g} \right) \times g \times k \times k = \frac{C_{in} \times C_{out}}{g} \times k \times k = \frac{C_{in} \times C_{out} \times k \times k}{g}
(gCin)×(gCout)×g×k×k=gCin×Cout×k×k=gCin×Cout×k×k
结论:分组卷积的总参数量是标准卷积的 1 g \frac{1}{g} g1(比如g=c1时就是「深度卷积」,参数量仅为普通卷积的1/c1)。
4.1.3 膨胀卷积(扩大感受野)
膨胀卷积(也叫空洞卷积)是在卷积核的元素之间插“0”,不用增大卷积核就能扩大「感受野」(模型能看到的图像区域大小):
-
标准卷积感受野公式:
R l = R l − 1 + ( k l − 1 ) × S l − 1 R_l = R_{l-1} + (k_l - 1) \times S_{l-1} Rl=Rl−1+(kl−1)×Sl−1
( R l − 1 R_{l-1} Rl−1=上一层感受野, S l − 1 S_{l-1} Sl−1=上一层步长, k l k_l kl=当前层卷积核大小) -
连续膨胀卷积的感受野公式:
R l = R l − 1 + ( k l − 1 ) × S l − 1 × d l R_l = R_{l-1} + (k_l - 1) \times S_{l-1} \times d_l Rl=Rl−1+(kl−1)×Sl−1×dl
( d l d_l dl=当前层膨胀系数) -
例子:k=3、d=2的膨胀卷积,感受野相当于5×5的普通卷积,但参数量还是3×3的!
4.2 BatchNorm2d层(训练稳定器)
BatchNorm2d(简称BN)是「训练加速器+稳定器」,解决“内部协变量偏移”问题(每层输入分布变来变去,模型学不快)。
4.2.1 BN的核心原理(对应公式)
BN的实现分3步:
a. 计算批次均值和方差
对于小批量数据
B
=
{
x
1
,
x
2
,
.
.
.
,
x
m
}
B = \{x_1, x_2, ..., x_m\}
B={x1,x2,...,xm},计算:
μ
B
=
1
m
∑
i
=
1
m
x
i
\mu_B = \frac{1}{m} \sum_{i=1}^{m} x_i
μB=m1i=1∑mxi
σ
B
2
=
1
m
∑
i
=
1
m
(
x
i
−
μ
B
)
2
\sigma_B^2 = \frac{1}{m} \sum_{i=1}^{m} (x_i - \mu_B)^2
σB2=m1i=1∑m(xi−μB)2
b. 标准化
使用批次均值和方差标准化每个数据点
x
i
x_i
xi:
x
^
i
=
x
i
−
μ
B
σ
B
2
+
ϵ
\hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}
x^i=σB2+ϵxi−μB
其中
ϵ
\epsilon
ϵ 是很小的常数(通常取
1
e
−
5
1e-5
1e−5),防止分母为零。
c. 尺度变换和位移
对标准化后的数据进行尺度变换和位移,恢复模型表达能力:
y
i
=
γ
×
x
^
i
+
β
y_i = \gamma \times \hat{x}_i + \beta
yi=γ×x^i+β
其中
γ
\gamma
γ(尺度)和
β
\beta
β(位移)是可学习的参数。
💡 关键:训练时用「批次均值/方差」,推理时用训练累积的「运行均值/方差」,保证训练和推理一致。
4.2.2 BN的作用
- 加速训练:允许用更大的学习率,不用慢慢调;
- 减少初始化依赖:随便初始化权重也能训好;
- 轻微正则化:避免模型过拟合。
4.3 SiLU层(非线性激活)
SiLU(也叫Swish)是YOLO11默认的激活函数,其完整表达式为:
silu
(
x
)
=
x
×
sigmoid
(
x
)
=
x
×
1
1
+
e
−
x
\text{silu}(x) = x \times \text{sigmoid}(x) = x \times \frac{1}{1 + e^{-x}}
silu(x)=x×sigmoid(x)=x×1+e−x1
4.3.1 SiLU的优势(对比ReLU)
- 解决「死亡ReLU」问题:ReLU输入为负时输出0,神经元会“躺平”;SiLU是平滑曲线,不会完全归零;
- 自稳定性:导数在-1.28附近为0,防止权重过大;
- 适配BN:和BatchNorm2d搭配使用效果更好。
4.3.2 输入输出特点
输入任意形状的张量,输出形状和输入完全一致,仅改变数值(给特征添加非线性,让模型学复杂规律)。
前向传播流程与维度计算
5.1 完整前向流程
Conv模块的正常前向传播(forward方法)分3步,一步都不能少:
输入x → Conv2d卷积(c1→c2通道) → BatchNorm2d归一化 → SiLU激活 → 输出
推理时会用forward_fuse方法:把BN层融合到Conv2d中(减少计算步骤),流程简化为:
输入x → 融合后的Conv2d → SiLU激活 → 输出
5.2 维度计算示例(初学者必看)
假设输入:(N=2, c1=3, H=64, W=64)(2张RGB图像,64×64分辨率)
Conv参数:c1=3, c2=16, k=3, s=2, p=1, g=1, d=1, act=True
计算输出尺寸:
H_out = (64 + 2×1 - 1×(3-1) - 1) / 2 + 1 = (64+2-2-1)/2 +1 = 63/2 +1 = 31 +1 = 32
W_out = 32(和H_out一致)
最终输出形状:(2, 16, 32, 32)(2个样本,16个通道,32×32分辨率)。
手动实现BN/SiLU(加深理解)
光看原理不够,手动实现一遍BN和SiLU,能彻底搞懂底层逻辑(代码可直接运行):
6.1 手动实现BatchNorm2d
import torch
import torch.nn as nn
class MyBatchNorm2d(nn.Module):
def __init__(self, num_features, eps=1e-5, momentum=0.1):
super().__init__()
self.eps = eps
self.momentum = momentum
# 可学习的缩放/位移参数
self.gamma = nn.Parameter(torch.ones(num_features))
self.beta = nn.Parameter(torch.zeros(num_features))
# 训练累积的运行均值/方差(不参与训练)
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
def forward(self, x):
if self.training:
# 训练模式:用当前批次的均值/方差
batch_mean = x.mean([0, 2, 3]) # 按通道算均值(N/H/W维度求平均)
batch_var = x.var([0, 2, 3], unbiased=False) # 按通道算方差
# 更新运行均值/方差
self.running_mean = self.momentum * batch_mean + (1 - self.momentum) * self.running_mean
self.running_var = self.momentum * batch_var + (1 - self.momentum) * self.running_var
# 标准化
x_norm = (x - batch_mean[None, :, None, None]) / torch.sqrt(batch_var[None, :, None, None] + self.eps)
else:
# 推理模式:用累积的运行均值/方差
x_norm = (x - self.running_mean[None, :, None, None]) / torch.sqrt(self.running_var[None, :, None, None] + self.eps)
# 缩放+位移
return self.gamma[None, :, None, None] * x_norm + self.beta[None, :, None, None]
# 测试
if __name__ == "__main__":
bn = MyBatchNorm2d(num_features=3)
x = torch.randn(2, 3, 64, 64) # 2张图,3通道,64×64
bn.train()
out = bn(x)
print("BN输出形状:", out.shape) # 输出(2,3,64,64)
6.2 手动实现SiLU
import torch
import torch.nn as nn
class MySiLU(nn.Module):
def forward(self, x):
# SiLU = x × sigmoid(x)
sigmoid_x = torch.sigmoid(x)
return x * sigmoid_x
# 测试
if __name__ == "__main__":
silu = MySiLU()
x = torch.randn(2, 16, 32, 32) # Conv输出的特征图
out = silu(x)
print("SiLU输出形状:", out.shape) # 输出(2,16,32,32)
常见问题解答
Q1:为什么Conv2d的bias=False?
A1:因为后面的BN层会计算y = γ×x̂ + β(β是位移参数),相当于BN已经包含了“偏置”的作用,留着Conv2d的bias只会多占参数,完全没用。
Q2:怎么把激活函数换成ReLU?
A2:初始化Conv时指定act=nn.ReLU()即可:
conv = Conv(c1=3, c2=16, k=3, act=nn.ReLU())
如果想关闭激活,传act=False。
Q3:分组卷积和深度卷积有啥区别?
A3:深度卷积是分组卷积的特例——当g=c1=c2时,就是深度卷积(每个输入通道对应一个卷积核,仅提取该通道的特征)。
Q4:forward和forward_fuse有啥区别?
A4:forward是训练时用的(包含Conv+BN+act);forward_fuse是推理加速用的(BN层被融合到Conv权重中,少一层计算,速度更快)。
Q5:自动填充autopad是啥意思?
A5:autopad会根据k、d自动计算填充值,保证卷积后特征图尺寸不变(比如k=3、d=1时,p=1;k=5、d=2时,p=4),不用手动算p值。
相关文件位置
- Conv模块定义:
ultralytics/nn/modules/conv.py - BN超参初始化:
ultralytics/utils/torch_utils.py(initialize_weights函数) - BN融合工具:
ultralytics/utils/torch_utils.py(fuse_conv_and_bn函数) - YOLO11配置文件(用Conv的例子):
ultralytics/cfg/models/11/yolo11.yaml



















 172万+
172万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











