




 本文探讨了机器学习中数据生成、预处理的重要性及集成算法的运用,涵盖数据集创建、标准化、归一化、编码缺失值处理,以及投票、袋装、提升和梯度提升算法的实践案例。
本文探讨了机器学习中数据生成、预处理的重要性及集成算法的运用,涵盖数据集创建、标准化、归一化、编码缺失值处理,以及投票、袋装、提升和梯度提升算法的实践案例。
 PPT页15
PPT页15
旁白:对于机器学习而言合适的数据一直都是稀缺资源,尤其是对于初学者根本无法找到适合自己模型算法的数据,所幸sklearn提供了制造训练数据的方法,请试着创造出样本数为10000特征数为3,共分4个类别的数据集,并显示出来。
安逸提交的代码:
| import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
plt.figure(figsize=(8, 8)) plt.title("Datasets")
# X为样本特征,Y为样本类别输出, 共10000个样本,每个样本3个特征,输出有4个类别,没有冗余特征,每个类别一个簇 X, Y = make_classification(n_samples=10000, n_features=3, n_redundant=0, n_clusters_per_class=1, n_classes=4) plt.scatter(X[:, 0], X[:, 1] ,marker='o', c=Y, s=25, edgecolor='k') plt.show() |
系统运行结果如图3.4.1.1,可以看到明显四个分类。
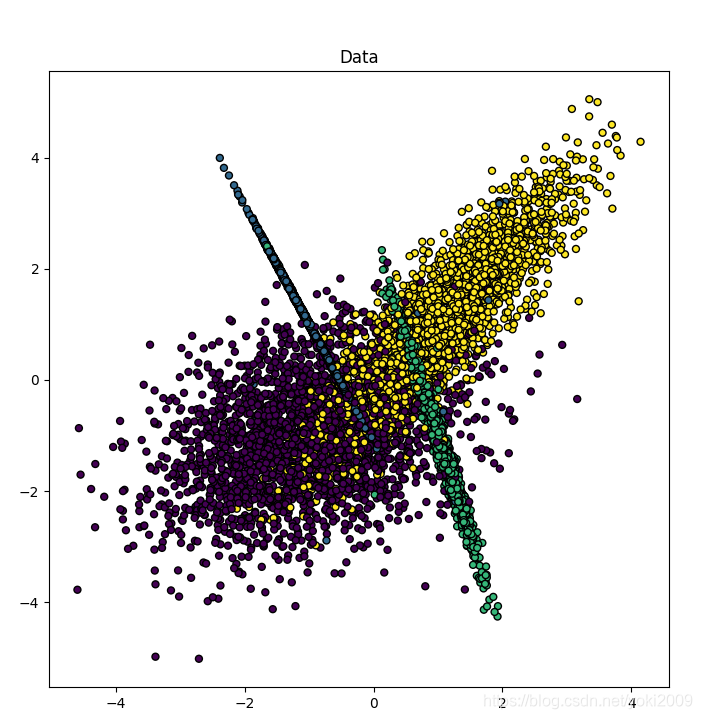
图3.4.1.1
旁白:尝试多运行几次,你会发现每次产生的数据都不一样,充满了随机性,这样非常不利于进行算法模拟,故我们需要将产生的数据进行持久化存储,sklearn也提供了存储与引导数据的方法,该方法不仅可以存储数据还可以存储算法模型,用法参考PPT页16,将数据存储后每次运行时就可以使用相同的数据进行算法验证了。

3.4.2 数据预处理

PPT页17
旁白:数据集的标准化是最常见的要求。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









