







 本文详细介绍了JVM内存的五大区域:方法区、堆、虚拟机栈、本地方法栈和程序计数器,包括它们的作用、特点以及在不同JVM版本中的实现变化。方法区存储类信息、静态变量等,Java8中由元空间替代永久代。堆内存分为年轻代和老年代,用于对象存储。虚拟机栈和本地方法栈分别管理Java方法和本地方法的调用。程序计数器则记录线程执行的字节码指令位置。
本文详细介绍了JVM内存的五大区域:方法区、堆、虚拟机栈、本地方法栈和程序计数器,包括它们的作用、特点以及在不同JVM版本中的实现变化。方法区存储类信息、静态变量等,Java8中由元空间替代永久代。堆内存分为年轻代和老年代,用于对象存储。虚拟机栈和本地方法栈分别管理Java方法和本地方法的调用。程序计数器则记录线程执行的字节码指令位置。
一、前言
根据 JVM 规范,JVM 内存共分为虚拟机栈VM stack、堆heap、方法区Method Area、程序计数器Program Counter Register、本地方法栈Native Method Stack五个部分。如下图,咋们分别对这五个区域进行详细的原理讲解。
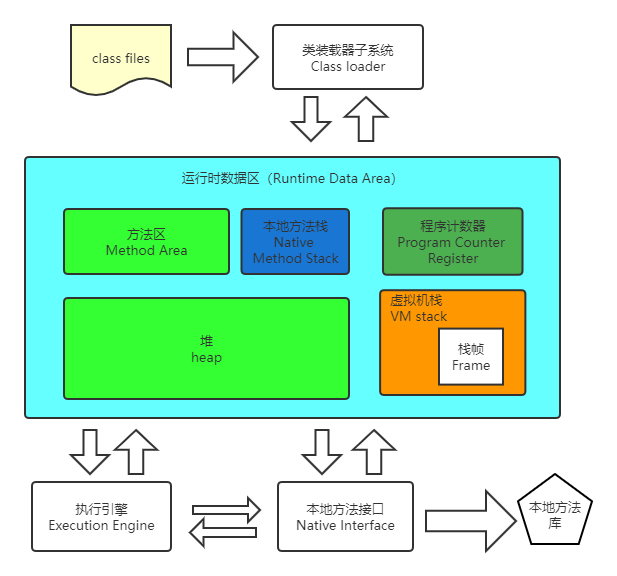
方法区:它用于存储已被虚拟机加载的类信息,常量,静态变量,即时编译(JIT)后的代码等数据。由于程序中所有的线程共享一个方法区,所以访问方法区的信息必须确保线程是安全的。如果有两个线程同时去加载一个类,那么只能有一个线程被允许去加载这个类,另一个必须等待。在程序运行时,方法区的大小是可以改变的。同时,方法区里面的对象也可以被垃圾回收,但是只有在该类没有任何引用的情况下才能被GC回收。
堆内存:堆内存是所有线程共享的,生成的对象和数据都是存在这个区域。
虚拟机栈:存储的是每个方法在执行时创建一个栈帧(Stack Frame),操作数栈,动态链接,方法出口等信息。每一个方法从调用至出栈的过程,就对应着栈帧在虚拟机中从入栈到出栈的过程。
本地方法栈:主要用于执行本地方法的,本地方法栈存放的方法调用本地方法接口,最终调用本地方法库,实现与操作系统、硬件交互。
程序计数器:说到这里我们的类已经加载了,实例对象、方法、静态变量都去了自己改去的地方,那么问题来了,程序该怎么执行,哪个方法先执行,哪个方法后执行,这些指令执行的顺序就是程序计数器在管,它的作用就是控制程序指令的执行顺序。
1.方法区(Method Area)
- 方法区是所有线程共享。
- 它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
- 方法区逻辑上属于堆的一部分,但是为了与堆进行区分,通常又叫“非堆”。
面试题:永久代(PermGen)、方法区(Method Area)、元空间(Metaspace)之间的关系:
方法区(Method Area)是规范层面的东西,规定了这一个区域要存放哪些东西,永久代(PermGen)和元空间(Metaspace)是对方法区(Method Area)的不同实现。
永久代(PermGen)是Java7以及之前JVM对于方法区(Method Area)的实现。
元空间(Metaspace)是Java8以及之后JVM对于方法区(Method Area)的实现。
举个例子:方法区比作手机,那么永生带可以比作诺基亚手机,元空间可以比作华为手机。
面试题:Java8的时候为什么要用元空间(Metaspace)替换掉永久代(PermGen):
- 永久代大小有限制,如果加载的类太多,很可能导致永久代内存溢出,即java.lang.OutOfMemoryError: PermGen,因此 JVM 的开发者希望这一块内存可以更灵活地被管理,不要再经常出现这样的 OOM。
- 移除 永久代 可以促进 HotSpot JVM 与 JRockit VM 的融合,因为 JRockit 没有永久代。
- 在Java7的时候,对于interned strings,不再分配在堆的永久代中了,而是分配在了堆中的主要部分:新生代和老年代中。在Java8的时候官方文档讲到了移除了永久代,但没有说其它关于interned strings相关的变化信息,因此,可以确定在Java8中字符串常量池存放在堆中。
- 也就是说在Java8的时候方法区由原来的永久代变成了元空间(类信息)和堆实现(常量池、静态变量)两个部分。堆中包含正常对象和常量池,new String()放入堆中,String::intern方法会首先从堆中的常量池中取,如果常量池中没有,就在常量池中保存String的值,然后返回其引用,下次在调用String::intern方法时,会直接返回常量池中的该值。
- 我们在Java8中也可以说常量池在方法区,因为永久代(PermGen)和元空间(Metaspace)是对方法区(Method Area)的不同实现,在上面我们刚刚也提到过。
- 元空间是使用本地内存(Native Memory)实现的,也就是说它的内存是不在虚拟机内的,所以可以理论上物理机器还有多个内存就可以分配,而不用再受限于JVM本身分配的内存。
- 如果Metaspace的空间占用达到了设定的最大值,那么就会触发GC来收集死亡对象和类的加载器。
2.堆(heap)
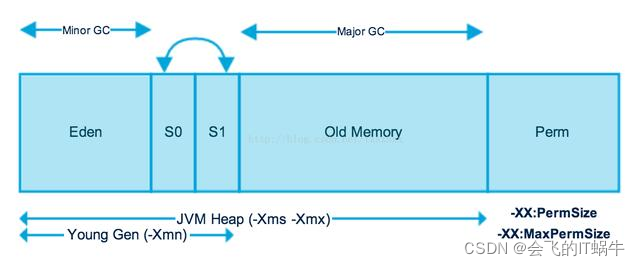
Java7以及之前的结构图:
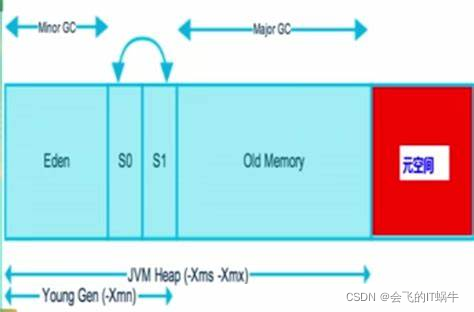
Java8以及之后的图如下:
面试题:堆为什么为什么分代:
- 分代的唯一理由就是优化GC性能。
- 如果没有分代,所有的对象都在一块,GC的时要找到哪些对象是没用的,这样就会对堆的所有区域进行扫描。而我们的很多对象都是朝生夕死的,比如年轻代中的对象基本都是朝生夕死的(80%以上),所以在年轻代的垃圾回收算法使用的是复制算法(后续会写一遍博文详细介绍)。
- 如果分代的话,把新创建的对象放到某一地方,当GC的时先把这块存“朝生夕死”对象的区域进行回收,这样就会腾出很大的空间出来。
面试题:Minor GC、Major GC和Full GC之间的区别:
- Minor GC或Young GC,用来回收年轻代(包括 Eden 和 Survivor 区域)内存空间的 。
- Old GC ,是清理老年代内存空间的。
- Full GC ,是回收整个堆空间,包括年轻代和老年代。在Java7以及之前还包括永久代;Java8及以后由于改成了元空间,它的垃圾回收就不是由java来控制了,元空间的默认情况下内存空间是使用的操作系统的内存空间,所以空间的容量是比较充裕的,不会发生元空间的空间不足问题,如果Metaspace的空间占用达到了设定的最大值,那么也会触发GC来收集死亡对象和类的加载器。
- Major GC ,有的人会把它和 Old GC等价,有的人会把它和Full GC等价,我们尽量不提这个Major GC,如果提到了,要问清楚对方指的是Old GC还是Full GC。
HotSpot JVM把年轻代分为了三部分:
- 三个部分分别是1个Eden区和2个Survivor区(分别叫from和to)。默认比例为8:1:1
- 如果没有Survivor,Eden区每进行一次Minor GC,存活的对象就会被送到老年代。老年代很快被填满,老年代的内存空间超过某个阈值或者远大于新生代时,会进行一次Full GC,而Full GC消耗的时间比Minor GC长得多。
- 设置两个Survivor区最大的好处就是解决了碎片化。
年轻代如何变成老年代
- 一般情况下,新创建的对象都会被分配到Eden区(一些大对象特殊处理),这些对象经过第一次Minor GC后,如果仍然存活,将会被移到Survivor区。对象在Survivor区中每熬过一次Minor GC,年龄就会增加1岁,当它的年龄增加到一定程度时(一般16次),就会被移动到年老代中。
3.虚拟机栈(VM stack)
- 每个线程有一个私有的栈,随着线程的创建而创建。
- 能抛出StackOverflowError和OutOfMemoryError异常。
如果线程请求分配的栈容量超过虚拟机栈允许的最大容量,java虚拟机将会抛出一个Stack Overflow Error异常。
如果虚拟机栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存,或者在创建新的线程时,没有足够的内存去创建对应的虚拟机栈,那么java虚拟机将会抛出一个OutOfMemoryError异常。
方法调用相关知识:
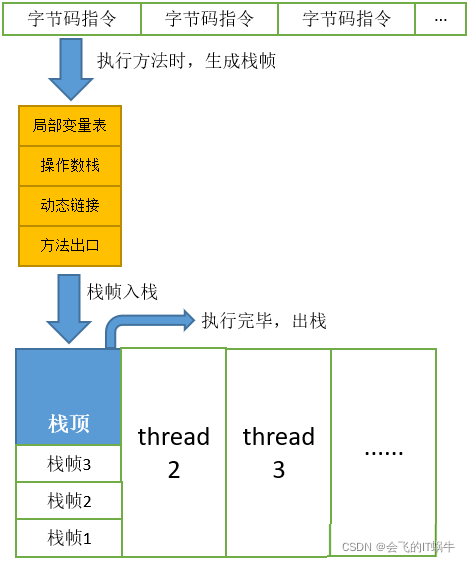
- 方法调用时,创建栈帧,并压入虚拟机栈;方法执行完毕,栈帧出栈并被销毁,
- 栈里面存着的是一种叫“栈帧”的东西,每个方法会创建一个栈帧,栈帧结构分为:局部变量表(基本数据类型和对象引用)、操作数栈、方法出口等信息。
我们debug的时候可以很明确的看到Frames,如下图:
- 栈内存指的便是虚拟机栈的栈帧中的局部变量表,因为这里存放了一个方法的所有局部变量。
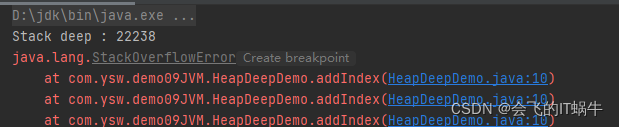
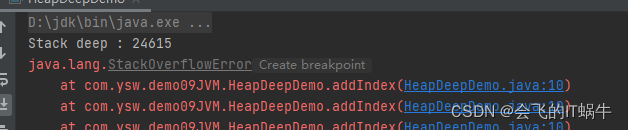
- 栈的大小可以固定也可以动态扩展。当栈调用深度大于JVM所允许的范围,会抛出StackOverflowError的错误,不过这个深度范围不是一个固定的值
大家可以通过下面的代码进行测试:
public class HeapDeepDemo {
private static int index = 0;
public void addIndex() {
index++;
addIndex();
}
public static void main(String[] args) {
HeapDeepDemo heapDeepDemo = new HeapDeepDemo();
try {
heapDeepDemo.addIndex();
} catch (Error e) {
System.out.println("Stack deep : " + index);
e.printStackTrace();
}
}
}
四次执行结果都不同,如下:


4.本地方法栈(Native Method Stack)
Java方法调用本地方法栈的过程如下图:
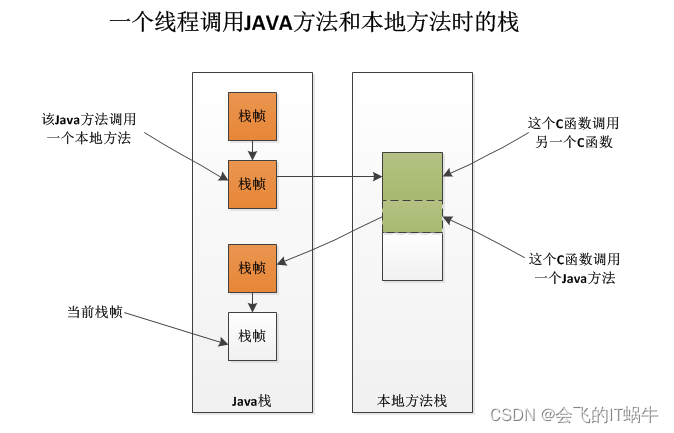
本地方法栈的知识点:
- 上面我们提到了VM虚拟机栈,虚拟机栈用于管理java方法的调用,而本地方法栈用于管理本地方法的调用,各司其职。
- 和虚拟机栈VM stack一样,本地方法栈Native Method Stack同样它也是线程私有的。
- 和虚拟机栈VM stack一样,允许被实现成固定或者是可动态扩展的大小
- 和虚拟机栈VM stack一样,本地方法栈Native Method Stack也能抛出StackOverflowError和OutOfMemoryError异常。
如果线程请求分配的栈容量超过本地方法栈允许的最大容量,java虚拟机将会抛出一个Stack Overflow Error异常。
如果本地方法栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存,或者在创建新的线程时,没有足够的内存去创建对应的本地方法栈,那么java虚拟机将会抛出一个OutOfMemoryError异常。
面试题:什么是本地方法栈(Native Method Stack)?
- 一个Native Method就是一个Java调用非Java代码的接口。方法的实现由非Java语言实现,比如C或C++。他的具体做法是Native Method Stack中登记native方法,在Execution Engine执行时加载本地方法库。
面试题:为什么要用到本地方法栈(Native Method Stack)?
- 有些层次的任务用java实现起来不容易,或者对程序的效率有要求时,还有时java应用需要与java外部的环境交互,这就是本地方法存在的主要原因。
5.程序计数器(Program Counter Register)
程序计数器是一个比较小的内存区域,可能是CPU寄存器或者操作系统内存,其主要用于指示当前线程所执行的字节码执行到了第几行,可以理解为是当前线程的行号指示器。字节码解释器在工作时,会通过改变这个计数器的值来取下一条语句指令。 每个程序计数器只用来记录一个线程的行号,所以它是线程私有(一个线程就有一个程序计数器)的。
如果程序执行的是一个Java方法,则计数器记录的是正在执行的虚拟机字节码指令地址;如果正在执行的是一个本地(native,由C语言编写完成)方法,则计数器的值为Undefined,由于程序计数器只是记录当前指令地址,所以不存在内存溢出的情况,因此,程序计数器也是所有JVM内存区域中唯一一个没有定义OutOfMemoryError的区域。


















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











