




 本文介绍了一种使用 Hadoop 实现的数据连接方法——Reduce-side Join 的具体实现细节。通过自定义 Map 和 Reduce 类,文章展示了如何进行数据分组、标签化以及最终的连接操作。此外,还提供了一个具体的例子,包括输入数据文件和期望的输出结果。
本文介绍了一种使用 Hadoop 实现的数据连接方法——Reduce-side Join 的具体实现细节。通过自定义 Map 和 Reduce 类,文章展示了如何进行数据分组、标签化以及最终的连接操作。此外,还提供了一个具体的例子,包括输入数据文件和期望的输出结果。
Reduce-side joining / repartitioned sort-merge join
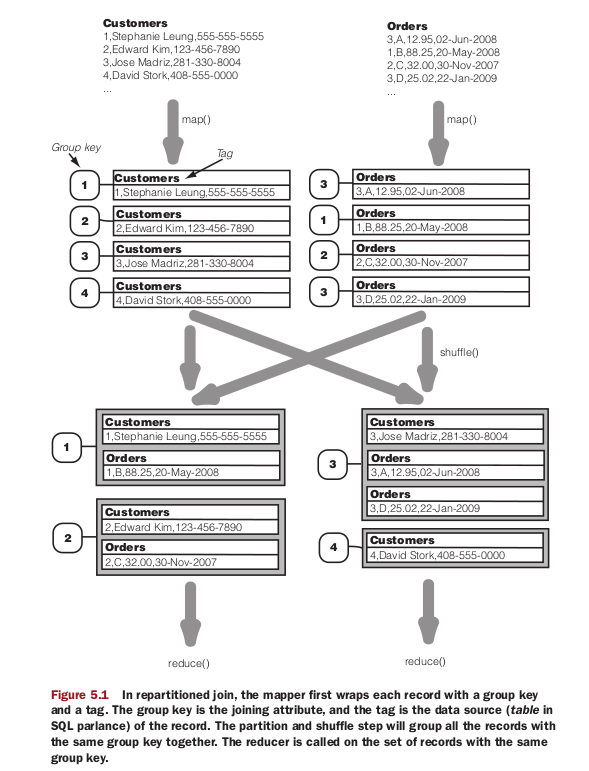
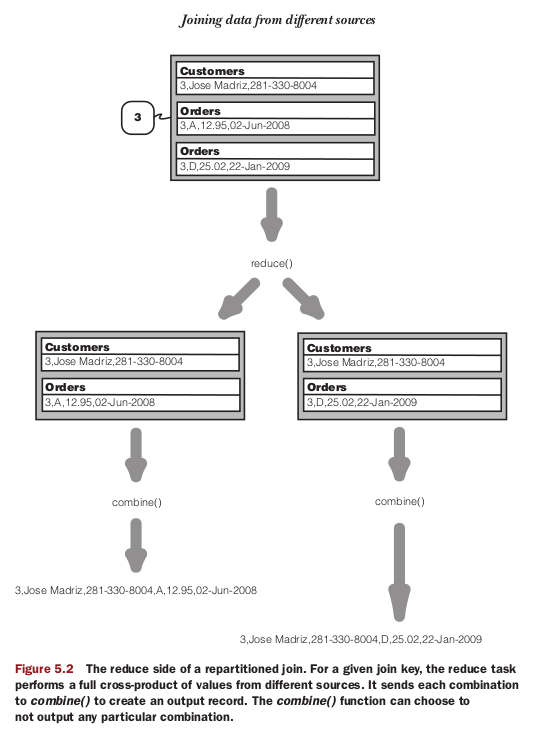
Note:DataJoinReducerBase, on the other hand, is the workhorse of the datajoin package, and it simplifies our programming by performing a full outer join for us. Our reducer subclass only has to implement the combine() method to filter out unwanted combinations to get the desired join operation (inner join, left outer join, etc.). It’s also in the combine() method that we format the combination into the appropriate
output format.
When run the sample code in <<hadoop in action>> chapter 5. There will some errors coming up. see
http://stackoverflow.com/questions/10201500/hadoop-reduce-side-join-using-datajoin
The correct code after modified likes
package com.test.datamine.topic;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.contrib.utils.join.DataJoinMapperBase;
import org.apache.hadoop.contrib.utils.join.DataJoinReducerBase;
import org.apache.hadoop.contrib.utils.join.TaggedMapOutput;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.ReflectionUtils;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class DataJoin extends Configured implements Tool {
public static class MapClass extends DataJoinMapperBase {
protected Text generateInputTag(String inputFile) {
String datasource = inputFile.split("-")[0];
return new Text(datasource);
}
protected Text generateGroupKey(TaggedMapOutput aRecord) {
String line = ((Text) aRecord.getData()).toString();
String[] tokens = line.split(",");
String groupKey = tokens[0];
return new Text(groupKey);
}
protected TaggedMapOutput generateTaggedMapOutput(Object value) {
TaggedWritable retv = new TaggedWritable((Text) value);
retv.setTag(this.inputTag);
return retv;
}
}
public static class Reduce extends DataJoinReducerBase {
protected TaggedMapOutput combine(Object[] tags, Object[] values) {
if (tags.length < 2)
return null;
String joinedStr = "";
for (int i = 0; i < values.length; i++) {
if (i > 0)
joinedStr += ",";
TaggedWritable tw = (TaggedWritable) values[i];
String line = ((Text) tw.getData()).toString();
String[] tokens = line.split(",", 2);
joinedStr += tokens[1];
}
TaggedWritable retv = new TaggedWritable(new Text(joinedStr));
retv.setTag((Text) tags[0]);
return retv;
}
}
public static class TaggedWritable extends TaggedMapOutput {
private Writable data;
public TaggedWritable() {
this.tag = new Text();
}
public TaggedWritable(Writable data) {
this.tag = new Text("");
this.data = data;
}
public Writable getData() {
return data;
}
public void setData(Writable data) {
this.data = data;
}
public void write(DataOutput out) throws IOException {
// this.tag.write(out);
// this.data.write(out);
this.tag.write(out);
out.writeUTF(this.data.getClass().getName());
this.data.write(out);
}
public void readFields(DataInput in) throws IOException {
// this.tag.readFields(in);
// this.data.readFields(in);
this.tag.readFields(in);
String dataClz = in.readUTF();
if (this.data == null
|| !this.data.getClass().getName().equals(dataClz)) {
try {
this.data = (Writable) ReflectionUtils.newInstance(
Class.forName(dataClz), null);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
this.data.readFields(in);
}
}
public int run(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job = new JobConf(conf, DataJoin.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("DataJoin");
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setInputFormat(TextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(TaggedWritable.class);
job.set("mapred.textoutputformat.separator", ",");
FileSystem fs = in.getFileSystem(conf);
fs.delete(out);
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new DataJoin(), args);
System.exit(res);
}
}
The test data is consist of two files
customers
1,Stephanie Leung,555-555-5555
2,Edward Kim,123-456-7890
3,Jose Madriz,281-330-8004
4,David Stork,408-555-0000
orders
3,A,12.95,02-Jun-2008
1,B,88.25,20-May-2008
2,C,32.00,30-Nov-2007
3,D,25.02,22-Jan-2009
the joined result is
1,Stephanie Leung,555-555-5555,B,88.25,20-May-2008
2,Edward Kim,123-456-7890,C,32.00,30-Nov-2007
3,Jose Madriz,281-330-8004,D,25.02,22-Jan-2009
3,Jose Madriz,281-330-8004,A,12.95,02-Jun-2008

















 1356
1356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









