






 本文详细介绍了Redis缓存的三种异常情况:雪崩、击穿和穿透,以及相应的预防策略。针对缓存雪崩,提出了设置随机过期时间、服务降级和熔断限流的解决方案。缓存击穿主要是热点数据过期失效,建议不设置过期时间。缓存穿透则可以通过缓存空值、布隆过滤器和前端安全检测来预防。总结中强调了预防式方案的重要性。
本文详细介绍了Redis缓存的三种异常情况:雪崩、击穿和穿透,以及相应的预防策略。针对缓存雪崩,提出了设置随机过期时间、服务降级和熔断限流的解决方案。缓存击穿主要是热点数据过期失效,建议不设置过期时间。缓存穿透则可以通过缓存空值、布隆过滤器和前端安全检测来预防。总结中强调了预防式方案的重要性。
上几篇笔者描述了reids持久化机制、redis高性能、redis高可靠之主从模式以及redis高可靠之哨兵模式. 本期主要介绍缓存雪崩、击穿、穿透等. 废话不多说, 直接上菜:
Q: 为什么会出现缓存异常?
A: 缓存异常概括来说主要分为四种:
- 缓存数据与数据库数据一致性;
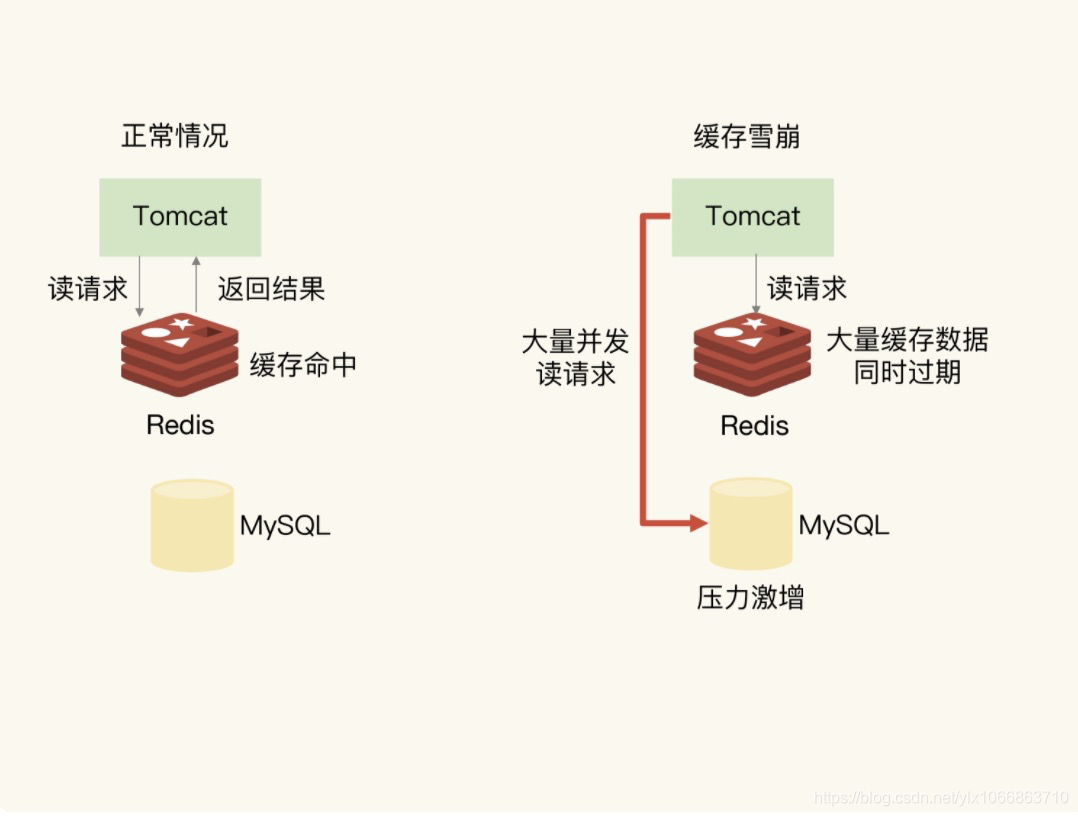
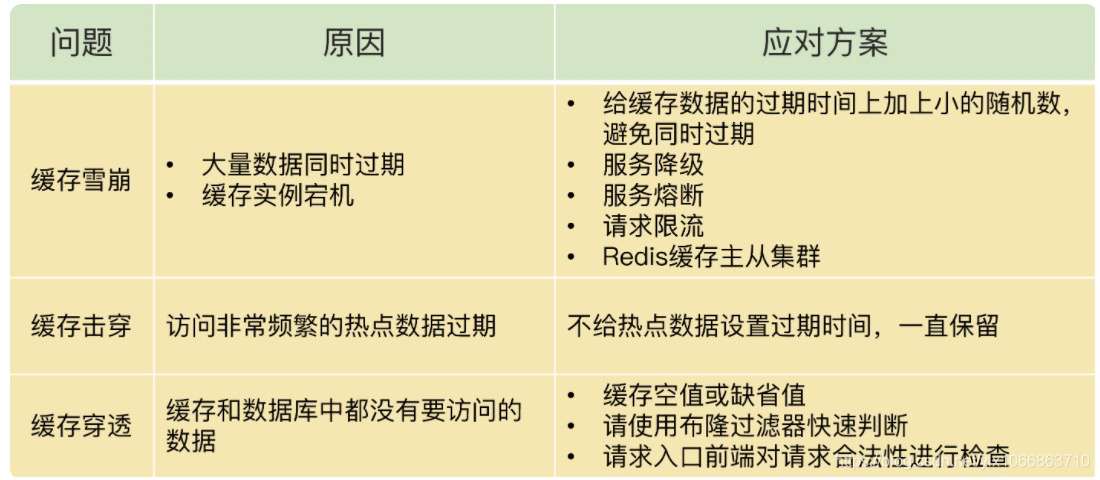
- 缓存雪崩: 指大量的应用请求无法在 Redis 缓存中进行处理,紧接着,应用将大量请求发送到数据库层,导致数据库层的压力激增。缓存雪崩一般由两个原因导致, 应对方案也有所不同.
- 缓存击穿: 缓存击穿是指,针对某个访问非常频繁的热点数据的请求,无法在缓存中进行处理,紧接着,访问该数据的大量请求,一下子都发送到了后端数据库,导致了数据库压力激增,会影响数据库处理其他请求。缓存击穿的情况,经常发生在热点数据过期失效时.
- 缓存穿透: 缓存穿透是指要访问的数据既不在 Redis 缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。
本章首先介绍缓存雪崩、缓存击穿以及缓存穿透.
Q: 缓存雪崩的原因有哪些?以及应对策略?
A: 缓存雪崩的原因如下:
- 缓存同时过期 :缓存中有大量数据同时过期, 导致大量请求无法得到处理。
- redis缓存宕机: Redis 缓存实例发生故障宕机了,无法处理请求,这就会导致大量请求一下子积压到数据库层,从而发生缓存雪崩。
缓存雪崩如下图所示:
针对大量数据同时失效带来的缓存雪崩问题,提供两种解决方案:
-
设置缓存随机过期时间: 避免给大量的数据设置相同的过期时间。如果业务层的确要求有些数据同时失效,你可以在用 EXPIRE 命令给每个数据设置过期时间时,给这些数据的过期时间增加一个较小的随机数(例如,随机增加 1~3 分钟),这样一来,不同数据的过期时间有所差别,但差别又不会太大,既避免了大量数据同时过期,同时也保证了这些数据基本在相近的时间失效,仍然能满足业务需求。
-
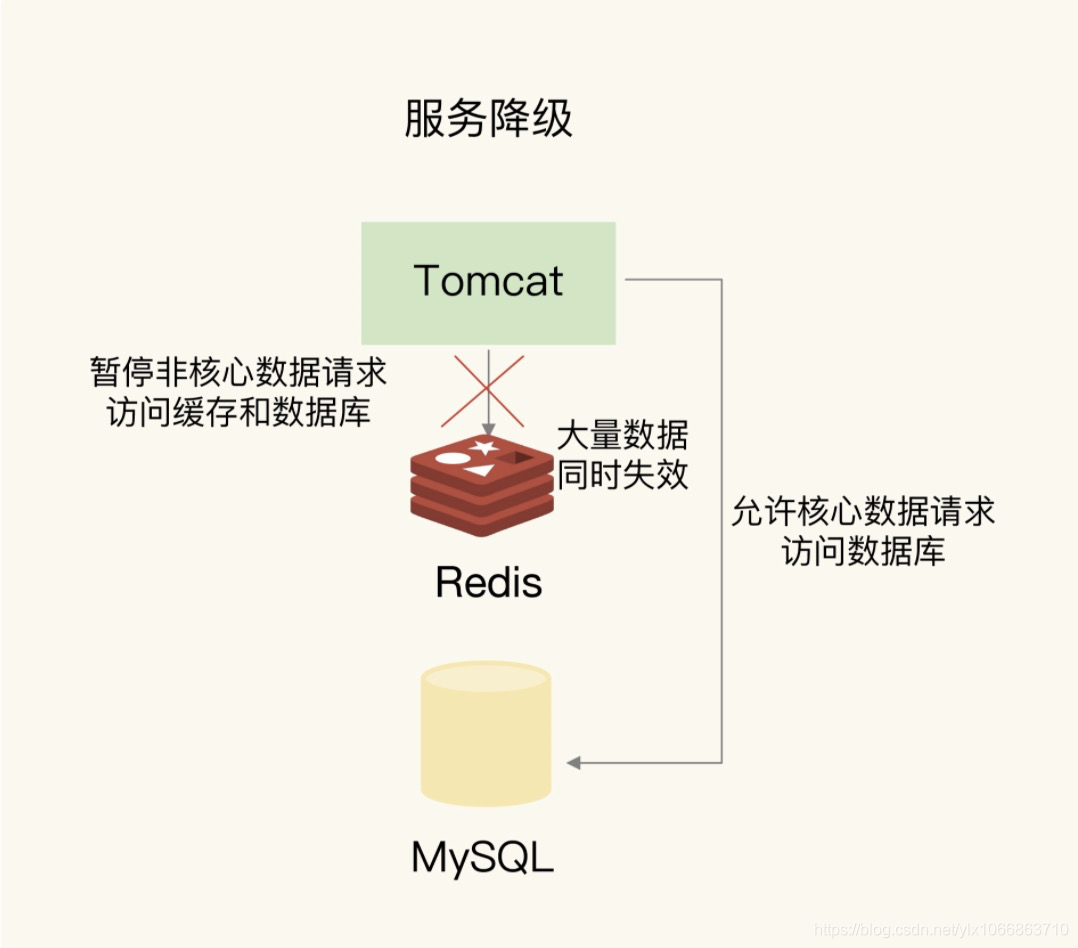
服务降级
当发生雪崩时,针对不同的数据采取不同的处理方式。
- 当业务应用访问的是非核心数据(例如电商商品属性)时,暂时停止从缓存中查询这些数据,而是直接返回预定义信息、空值或是错误信息;
- 当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。
简言之: 降级非核心应用对数据库的访问, 保证核心流程不受影响.
服务降级如下图所示:
- 宕机:
一般来说,一个 Redis 实例可以支持数万级别的请求处理吞吐量,而单个数据库可能只能支持数千级别的请求处理吞吐量,它们两个的处理能力可能相差了近十倍。由于缓存雪崩,Redis 缓存失效,所以,数据库就可能要承受近十倍的请求压力,从而因为压力过大而崩溃。
此时,因为 Redis 实例发生了宕机,需要通过其他方法来应对缓存雪崩了。我给你提供两个建议。
- 第一个建议,是在业务系统中实现服务熔断或请求限流机制。
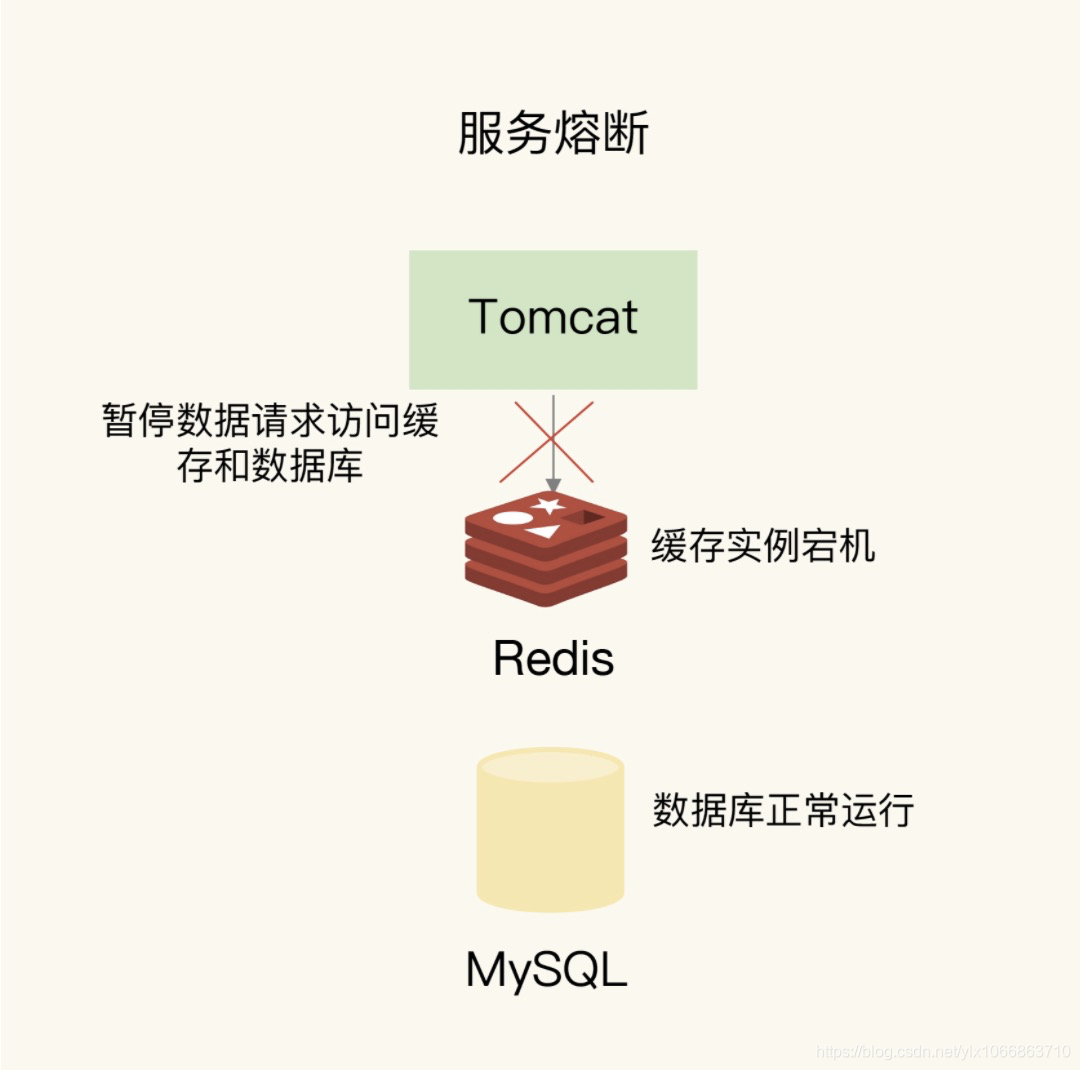
服务熔断: 是指在发生缓存雪崩时,为了防止引发连锁的数据库雪崩,甚至是整个系统的崩溃,暂停业务应用对缓存系统的接口访问。再具体点说,就是业务应用调用缓存接口时,缓存客户端并不把请求发给 Redis 缓存实例,而是直接返回,等到 Redis 缓存实例重新恢复服务后,再允许应用请求发送到缓存系统。
这样一来,我们就避免了大量请求因缓存缺失,而积压到数据库系统,保证了数据库系统的正常运行。
在业务系统运行时,我们可以监测 Redis 缓存所在机器和数据库所在机器的负载指标,例如每秒请求数、CPU 利用率、内存利用率等。如果我们发现 Redis 缓存实例宕机了,而数据库所在机器的负载压力突然增加(例如每秒请求数激增),此时,就发生缓存雪崩了。大量请求被发送到数据库进行处理。我们可以启动服务熔断机制,暂停业务应用对缓存服务的访问,从而降低对数据库的访问压力,如下图所示:
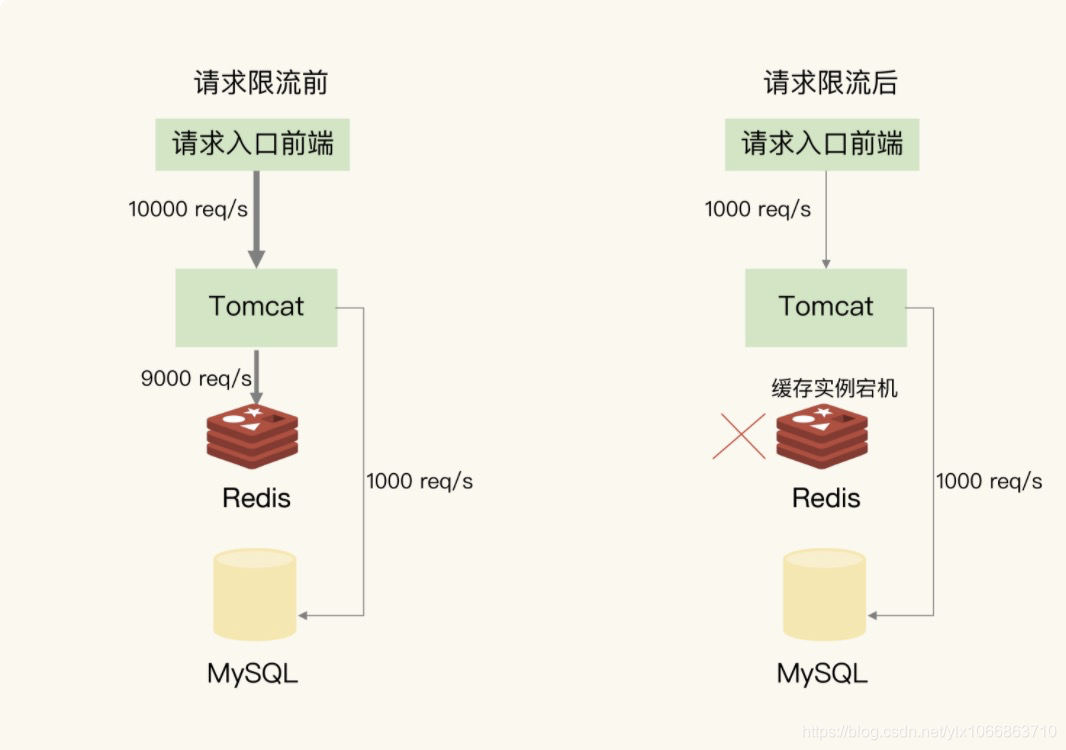
请求限流机制: 例如: 请求入口前端允许每秒进入系统的请求是 1 万个,其中,9000 个请求都能在缓存系统中进行处理,只有 1000 个请求会被应用发送到数据库进行处理。一旦发生了缓存雪崩,数据库的每秒请求数突然增加到每秒 1 万个,此时,我们就可以启动请求限流机制,在请求入口前端只允许每秒进入系统的请求数为 1000 个,再多的请求就会在入口前端被直接拒绝服务。所以,使用了请求限流,就可以避免大量并发请求压力传递到数据库层。
使用服务熔断或是请求限流机制,来应对 Redis 实例宕机导致的缓存雪崩问题,是属于“事后诸葛亮”,也就是已经发生缓存雪崩了,我们使用这两个机制,来降低雪崩对数据库和整个业务系统的影响。
第二个建议就是事前预防
通过主从节点的方式构建 Redis 缓存高可靠集群。如果 Redis 缓存的主节点故障宕机了,从节点还可以切换成为主节点,继续提供缓存服务,避免了由于缓存实例宕机而导致的缓存雪崩问题。
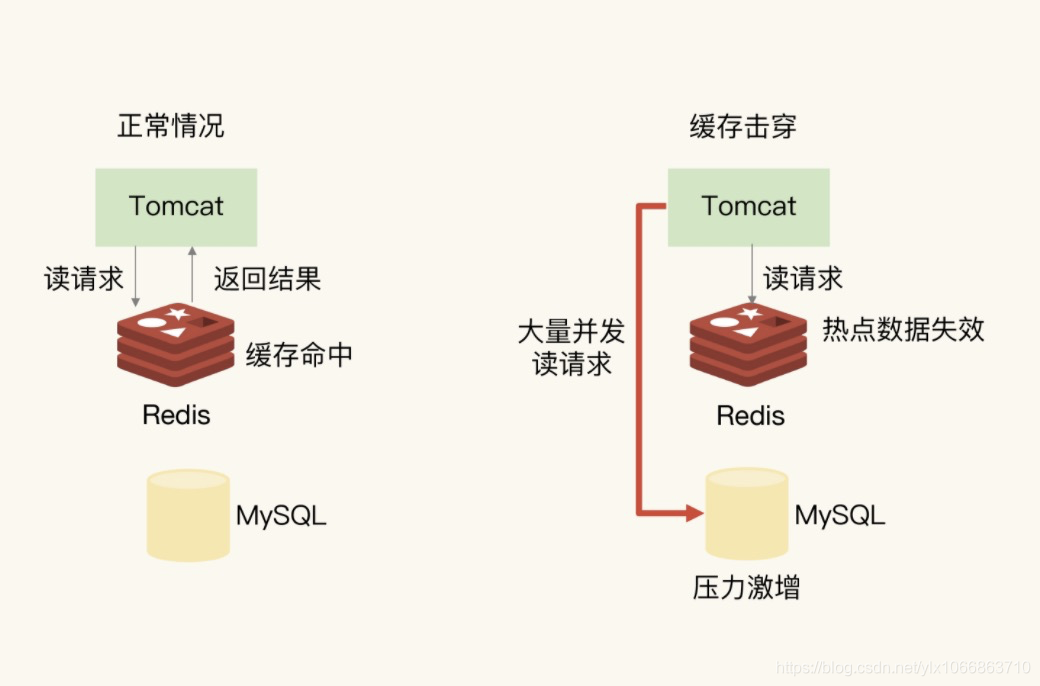
Q: 什么是缓存击穿?
缓存击穿是指,针对某个访问非常频繁的热点数据的请求,无法在缓存中进行处理,紧接着,访问该数据的大量请求,一下子都发送到了后端数据库,导致了数据库压力激增,会影响数据库处理其他请求。缓存击穿的情况,经常发生在热点数据过期失效时,如下图所示:
Q: 如何预防缓存击穿?
对于访问特别频繁的热点数据, 不设置过期时间了。
Q: 什么是缓存穿透?
缓存穿透是指要访问的数据既不在 Redis 缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。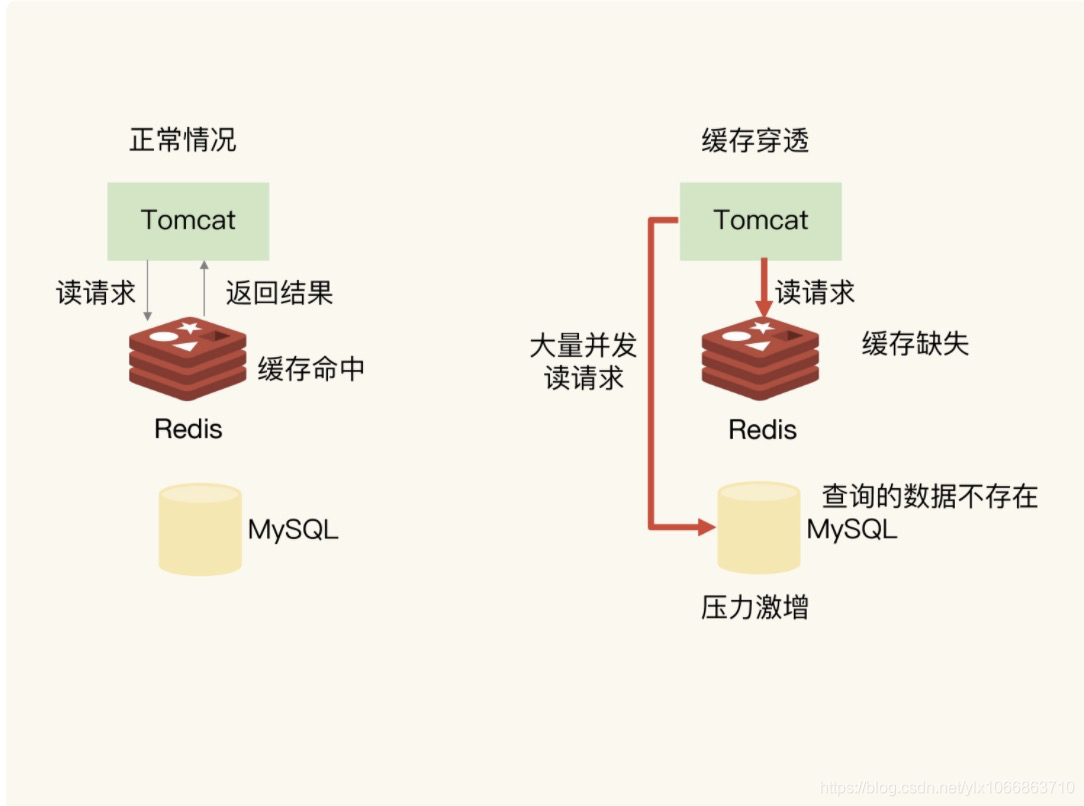
缓存穿透, 一般来说,有两种情况:
- 业务层误操作:缓存中的数据和数据库中的数据被误删除了,所以缓存和数据库中都没有数据;
- 恶意攻击:专门访问数据库中没有的数据。
Q: 如何预防缓存穿透?
为了应对缓存穿透设置3中应策略:
1. 缓存空值或缺省值
一旦发生缓存穿透,我们就可以针对查询的数据,在 Redis 中缓存一个空值或是和业务层协商确定的缺省值(例如,库存的缺省值可以设为 0)。紧接着,应用发送的后续请求再进行查询时,就可以直接从 Redis 中读取空值或缺省值,返回给业务应用了,避免了把大量请求发送给数据库处理,保持了数据库的正常运行。
2. 使用布隆过滤器快速判断数据是否存在,避免从数据库中查询数据是否存在,减轻数据库压力
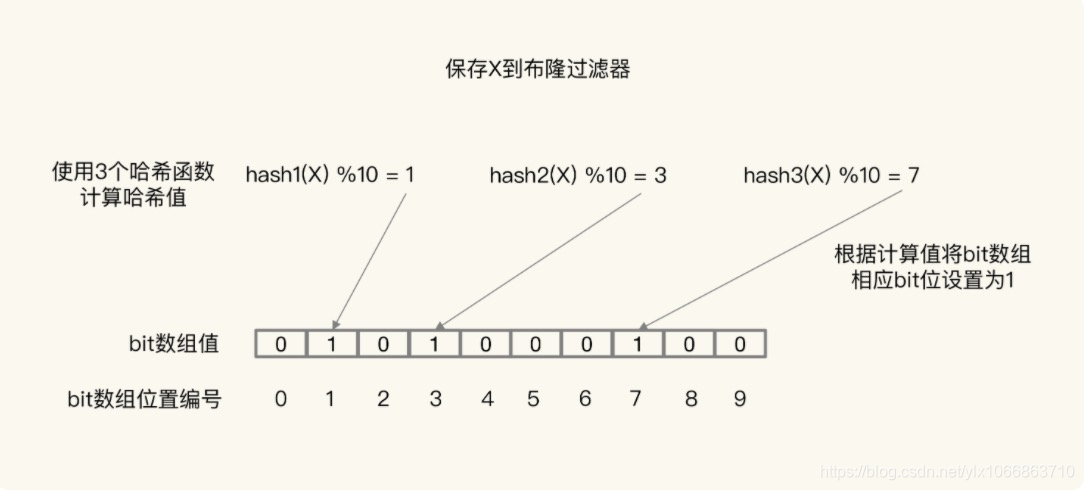
布隆过滤器由一个初值都为 0 的 bit 数组和 N 个哈希函数组成,可以用来快速判断某个数据是否存在。当我们想标记某个数据存在时(例如,数据已被写入数据库),布隆过滤器会通过三个操作完成标记:
- 首先,使用 N 个哈希函数,分别计算这个数据的哈希值,得到 N 个哈希值。
- 然后,我们把这 N 个哈希值对 bit 数组的长度取模,得到每个哈希值在数组中的对应位置。
- 最后,我们把对应位置的 bit 位设置为 1,这就完成了在布隆过滤器中标记数据的操作。
如果数据不存在(例如,数据库里没有写入数据),我们也就没有用布隆过滤器标记过数据,那么,bit 数组对应 bit 位的值仍然为 0。
当需要查询某个数据时,就执行刚刚说的计算过程,先得到这个数据在 bit 数组中对应的 N 个位置。紧接着,我们查看 bit 数组中这 N 个位置上的 bit 值。只要这 N 个 bit 值有一个不为 1,这就表明布隆过滤器没有对该数据做过标记,所以,查询的数据一定没有在数据库中保存。如下图:
正是基于布隆过滤器的快速检测特性,我们可以在把数据写入数据库时,使用布隆过滤器做个标记。当缓存缺失后,应用查询数据库时,可以通过查询布隆过滤器快速判断数据是否存在。如果不存在,就不用再去数据库中查询了。这样一来,即使发生缓存穿透了,大量请求只会查询 Redis 和布隆过滤器,而不会积压到数据库,也就不会影响数据库的正常运行。布隆过滤器可以使用 Redis 实现,本身就能承担较大的并发访问压力。
前端进行请求检测(安全检测)
缓存穿透的一个原因是有大量的恶意请求访问不存在的数据,所以,一个有效的应对方案是在请求入口前端,对业务系统接收到的请求进行合法性检测,把恶意的请求(例如请求参数不合理、请求参数是非法值、请求字段不存在)直接过滤掉,不让它们访问后端缓存和数据库。这样一来,也就不会出现缓存穿透问题了。
小结
服务熔断、服务降级、请求限流这些方法都是属于“有损”方案,在保证数据库和整体系统稳定的同时,会对业务应用带来负面影响。
预防式方案:
- 针对缓存雪崩,合理地设置数据过期时间,以及搭建高可靠缓存集群;
- 针对缓存击穿,在缓存访问非常频繁的热点数据时,不要设置过期时间;
- 针对缓存穿透,提前在入口前端实现恶意请求检测,或者规范数据库的数据删除操作,避免误删除。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









