







大家好!今天给大家安利一个超厉害的长视频定位框架——SOONet!👏
传统方法处理长视频时,总是需要把视频切成一小段一小段,再逐一分析,不仅耗时还容易出错。但SOONet不一样,它可以一次性处理长达数小时的视频,效率杠杠的!🚀
SOONet采用“粗筛-精筛”两阶段策略,结合独特的网络结构和损失函数,能精准捕捉视频中的关键信息,无论是上下文还是细节都不放过。💪
在实际测试中,SOONet在MAD和Ego4d两个数据集上的表现非常出色,定位准确度达到顶尖水平,推理效率更是提升了14.6倍和102.8倍!简直太牛了!🌟
如果你也经常处理长视频,一定要试试SOONet,它绝对是你的好帮手!👍
🏷️#长视频处理 #高效定位 #技术创新
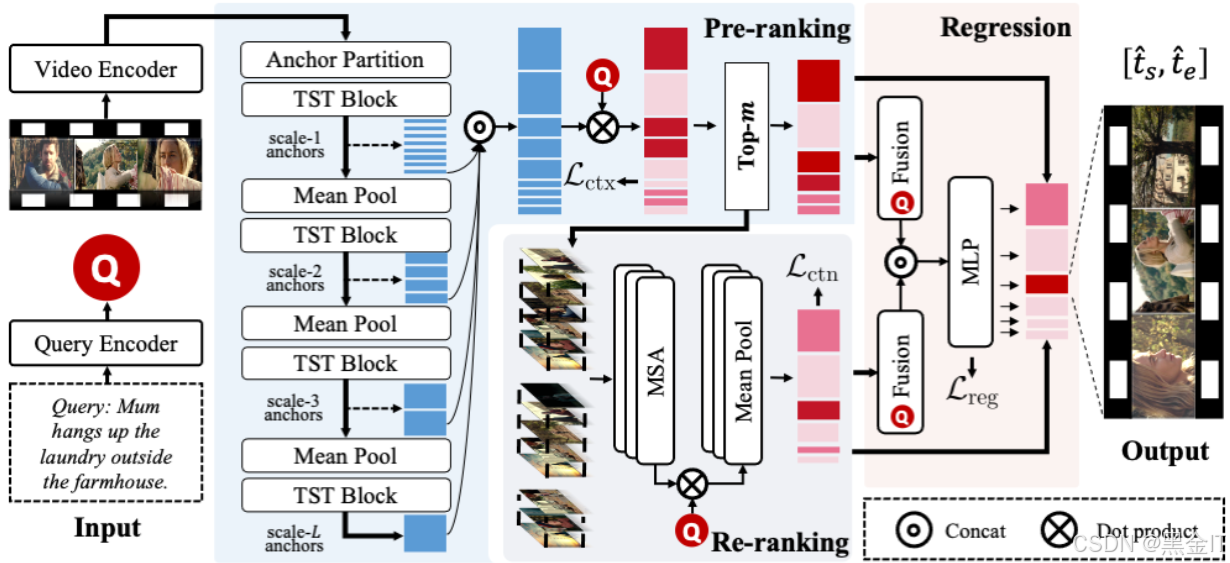
SOONet在提高长视频时序定位准确度方面有以下创新:
1. “粗筛-精筛”二阶段召回策略
SOONet采用“粗筛-精筛”的二阶段召回策略,先通过粗筛快速定位出可能包含目标片段的候选区域,再通过精筛对这些候选区域进行精细化处理,精确确定目标片段的起始和结束时间。
2. 融合上下文信息和内容信息
SOONet通过精细定制化的网络结构和损失函数,很好地融合了anchor间的上下文信息和anchor内的内容信息。这种融合方式有助于模型更全面地理解视频内容,从而提高时序定位的精度。
3. 端到端的推理方式
SOONet是第一个端到端的长视频时序定位框架,能够直接对长视频进行推理,而无需像传统方法那样将长视频切割成多个短视频片段进行重复推理。这种方式不仅提高了处理效率,还避免了滑动窗口方法带来的低效率问题。
4. 高效的网络结构和损失函数
SOONet采用了定制化的网络结构和损失函数,能够更好地适应长视频时序定位任务。其网络结构和损失函数的设计使得模型在处理长视频时能够更高效地提取特征和优化参数。
5. 显著的性能提升
SOONet在MAD和Ego4d两个长视频数据集上均取得了SOTA的定位准确度。在MAD数据集上,SOONet的准确率显著高于其他方法,例如在R1@0.1指标上达到了11.26%,而其他方法如VLG-Net和CLIP分别为3.64%和6.57%。同时,SOONet在推理效率上也有显著提升,分别将推理效率提升14.6倍和102.8倍。
这些创新使得SOONet在长视频时序定位任务中表现出了更高的准确度和效率。

















 2682
2682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









