






 本文详细介绍了MySQL中的索引类型(如BTREE和B+树),索引设计原则,以及多版本并发控制(MVCC)在解决并发问题、优化SQL查询和避免幻读等方面的应用。讲解了事务隔离级别对快照读的影响,强调了在高并发场景下的SQL优化技巧。
本文详细介绍了MySQL中的索引类型(如BTREE和B+树),索引设计原则,以及多版本并发控制(MVCC)在解决并发问题、优化SQL查询和避免幻读等方面的应用。讲解了事务隔离级别对快照读的影响,强调了在高并发场景下的SQL优化技巧。
一、mysql 索引(左小右大)
下图中为二叉树
MyISAM和InnoDB到底有什么区别呢?
InnoDB的主键使用的都是聚簇索引,而MyASM无论是主键索引还是二级索引,使用的都是非聚簇索引。
1、MyISAM和InnoDB的区别
MySQL 5.5以后的版本开始将InnoDB作为默认的存储引擎,之前的版本都是MyISAM。关于MyISAM和InnoDB的区别,我总结为以下5个方面,希望能帮助到大家。
1). 数据的存储结构不同
先来看MyISAM,每个MyISAM在磁盘上存储成三个文件,它们以表的名字开头来命名。.frm文件存储表定义。.MYD(MYD)存储数据文件。.MYI(MYIndex)存储索引文件。
而 InnoDB在磁盘上保存为两个文件。.frm文件同样存储为表结构文件,.ibd文件存储的是数据和索引文件。
mysql索引类型以及数据结构

BTREE结构
BTree又叫多路平衡搜索树,一颗m叉的BTree特性如下:
-
树中每个节点最多包含m个孩子。
-
除根节点与叶子节点外,每个节点至少有[ceil(m/2)]个孩子。
-
若根节点不是叶子节点,则至少有两个孩子。
-
所有的叶子节点都在同一层。
-
每个非叶子节点由n个key与n+1个指针组成,其中[ceil(m/2)-1] <= n <= m-1
以5叉BTree为例,key的数量:公式推导[ceil(m/2)-1] <= n <= m-1。所以 2 <= n <=4 。当n>4时,中间节点分裂到父节点,两边节点分裂。
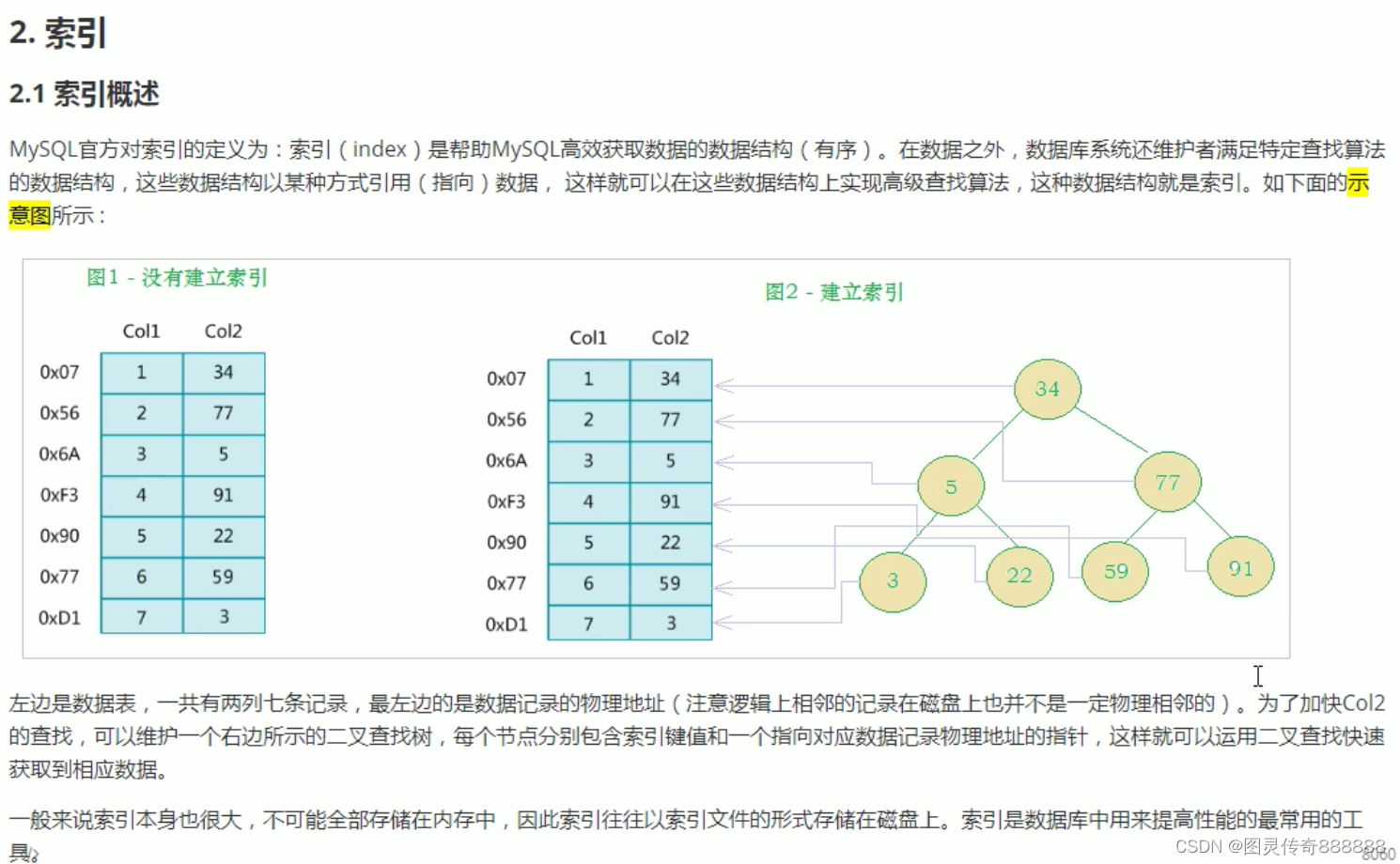
插入 C N G A H E K Q M F W L T Z D P R X Y S 数据为例。
演变过程如下:
1). 插入前4个字母 C N G A
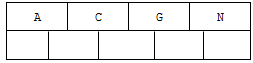
2). 插入H,n>4,中间元素G字母向上分裂到新的节点
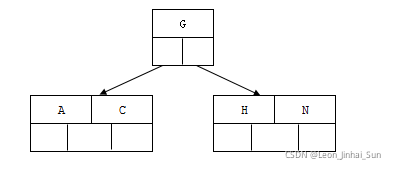
3). 插入E,K,Q不需要分裂
4). 插入M,中间元素M字母向上分裂到父节点G

5). 插入F,W,L,T不需要分裂
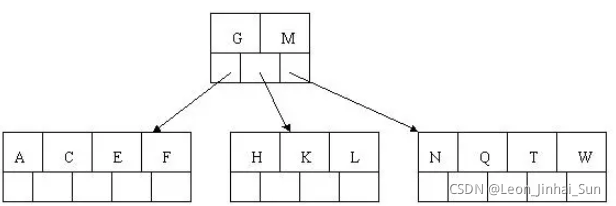
6). 插入Z,中间元素T向上分裂到父节点中
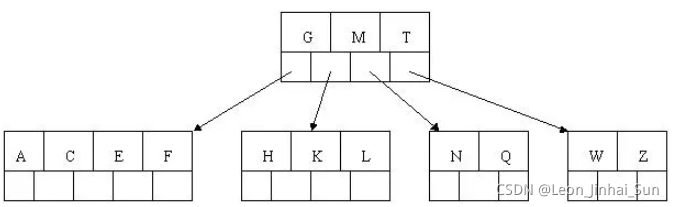
7). 插入D,中间元素D向上分裂到父节点中。然后插入P,R,X,Y不需要分裂
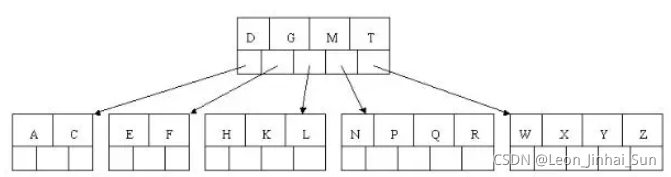
8). 最后插入S,NPQR节点n>5,中间节点Q向上分裂,但分裂后父节点DGMT的n>5,中间节点M向上分裂
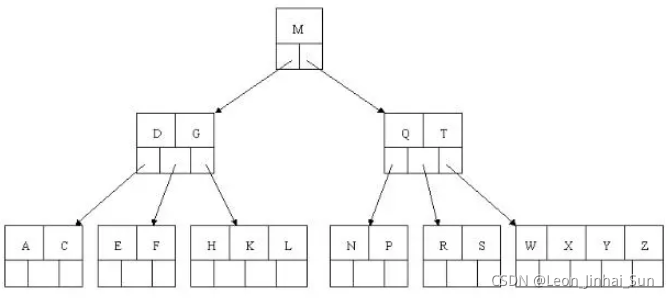
到此,该BTREE树就已经构建完成了, BTREE树 和 二叉树 相比, 查询数据的效率更高, 因为对于相同的数据量来说,BTREE的层级结构比二叉树小,因此搜索速度快。
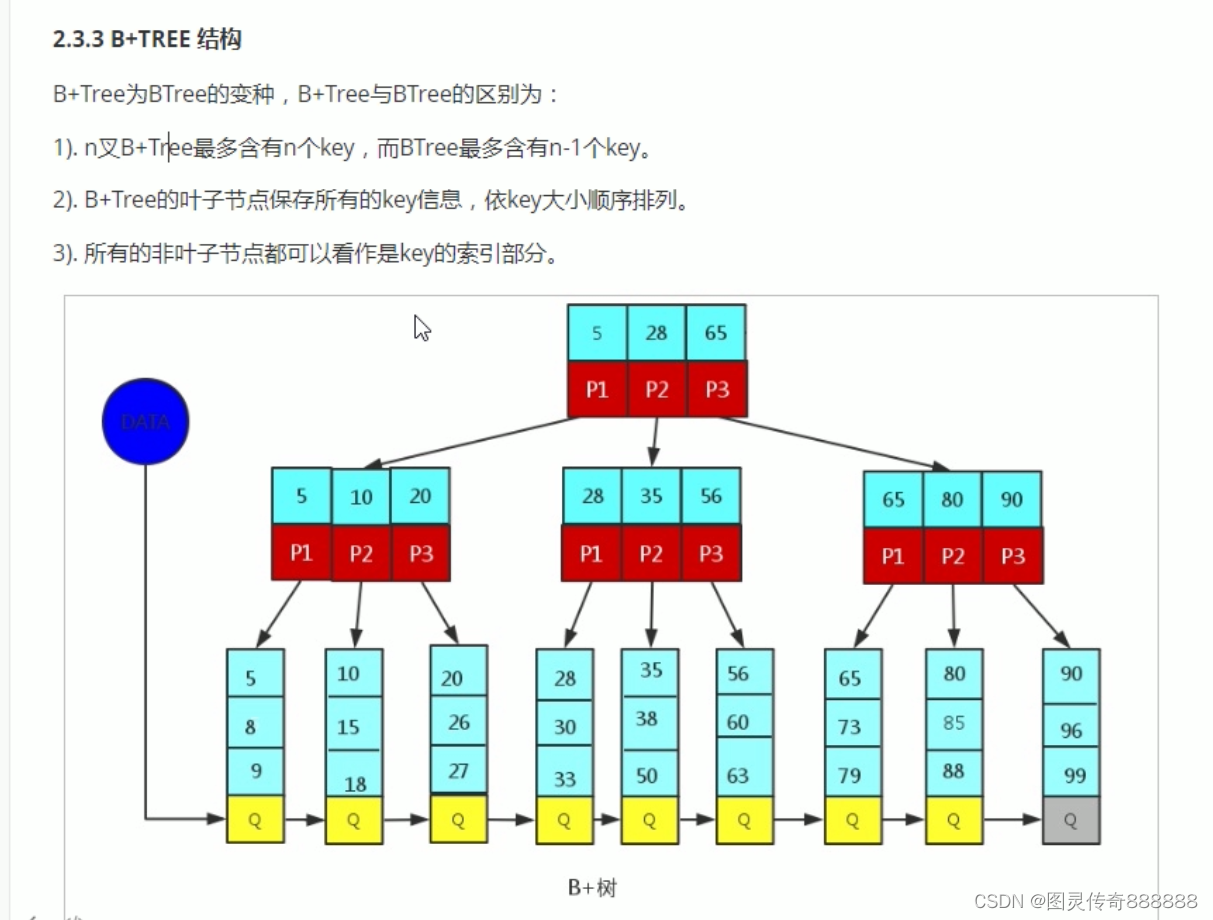
B+树的数据结构
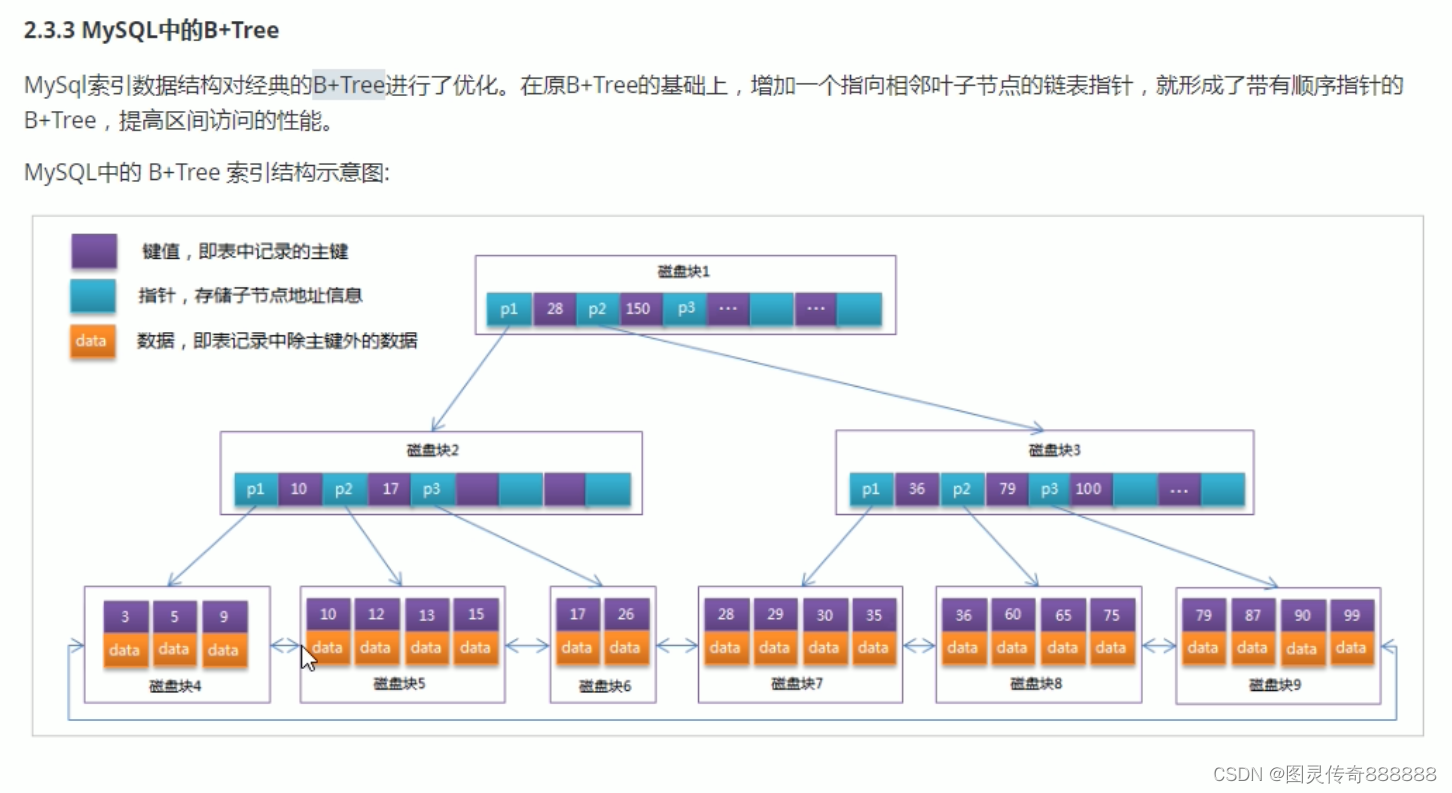
索引设计原则

sql优化重点
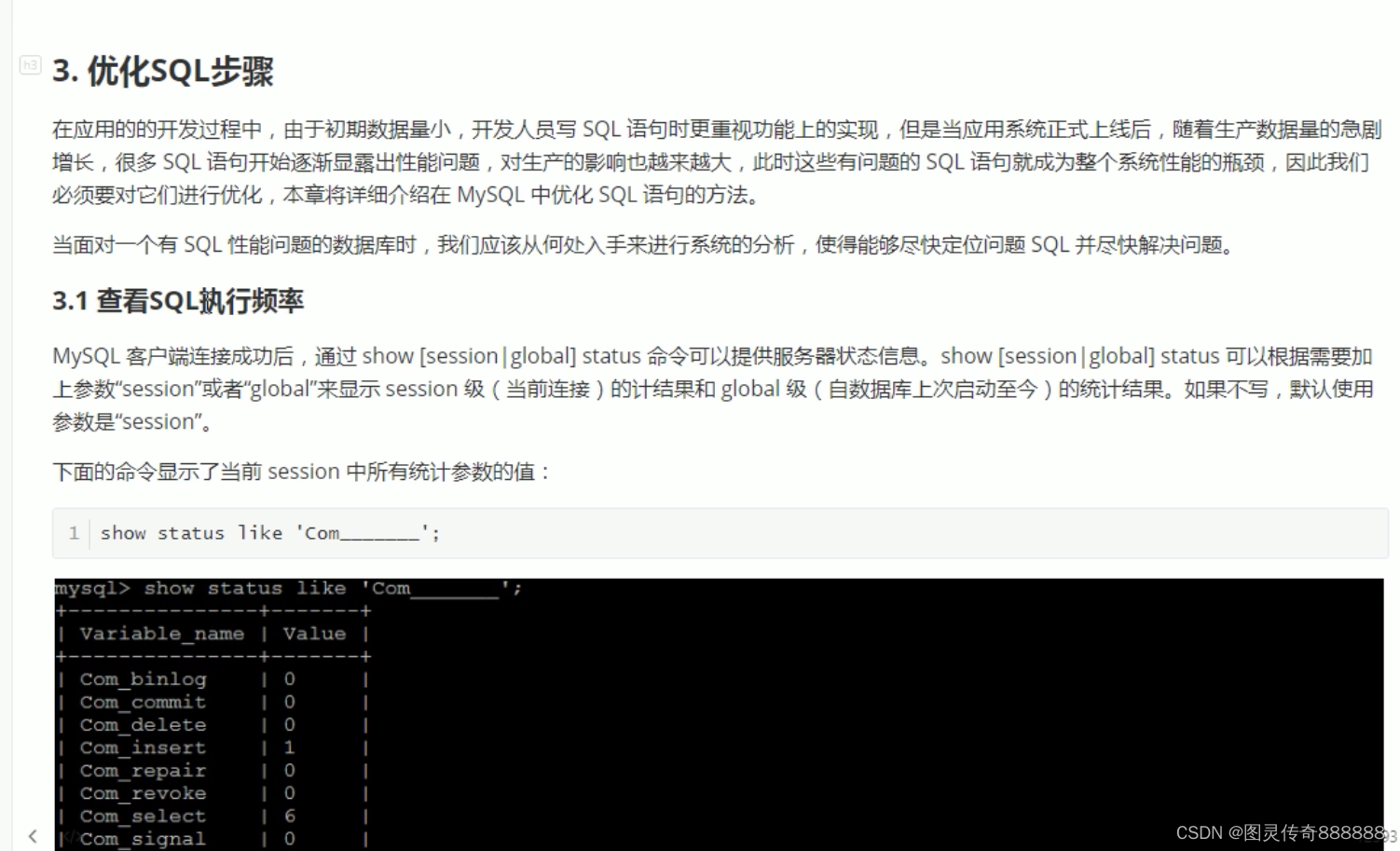
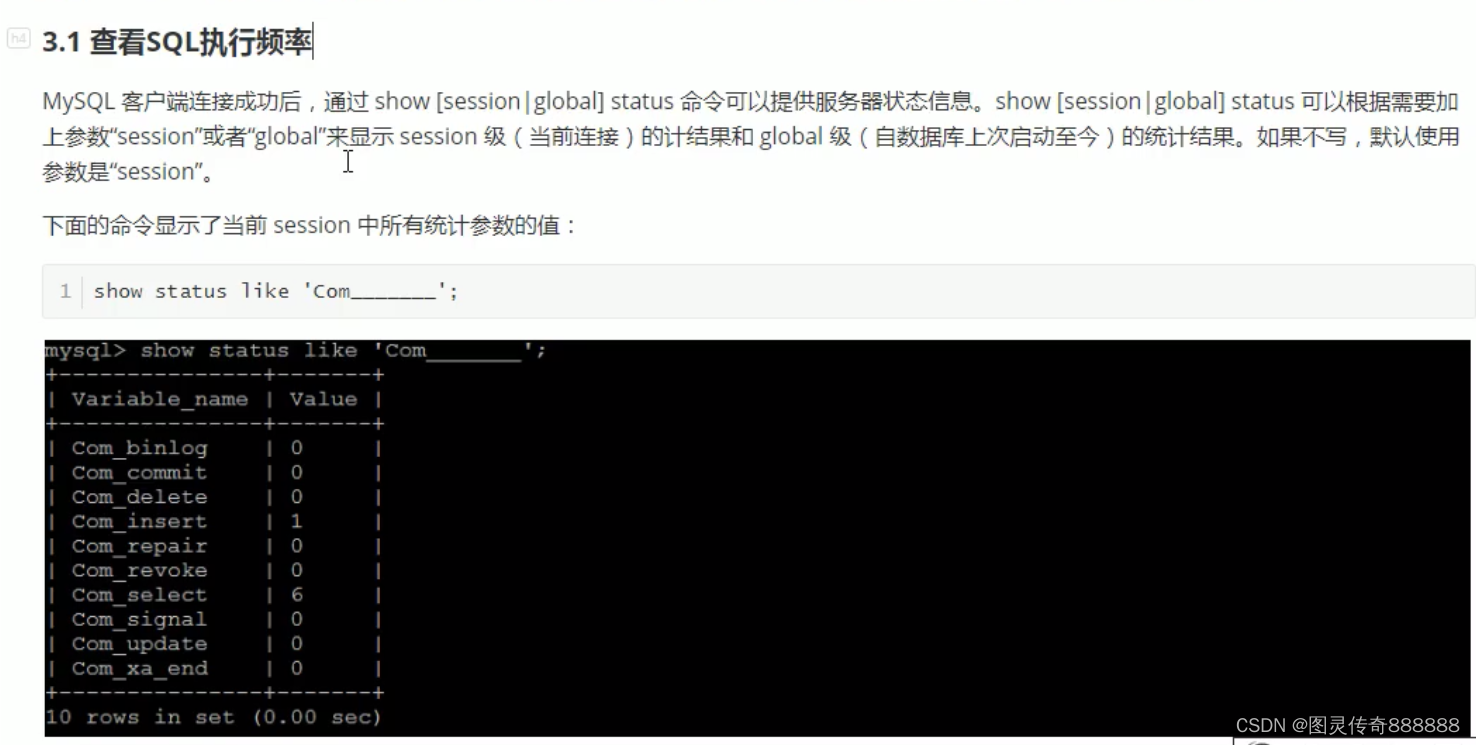
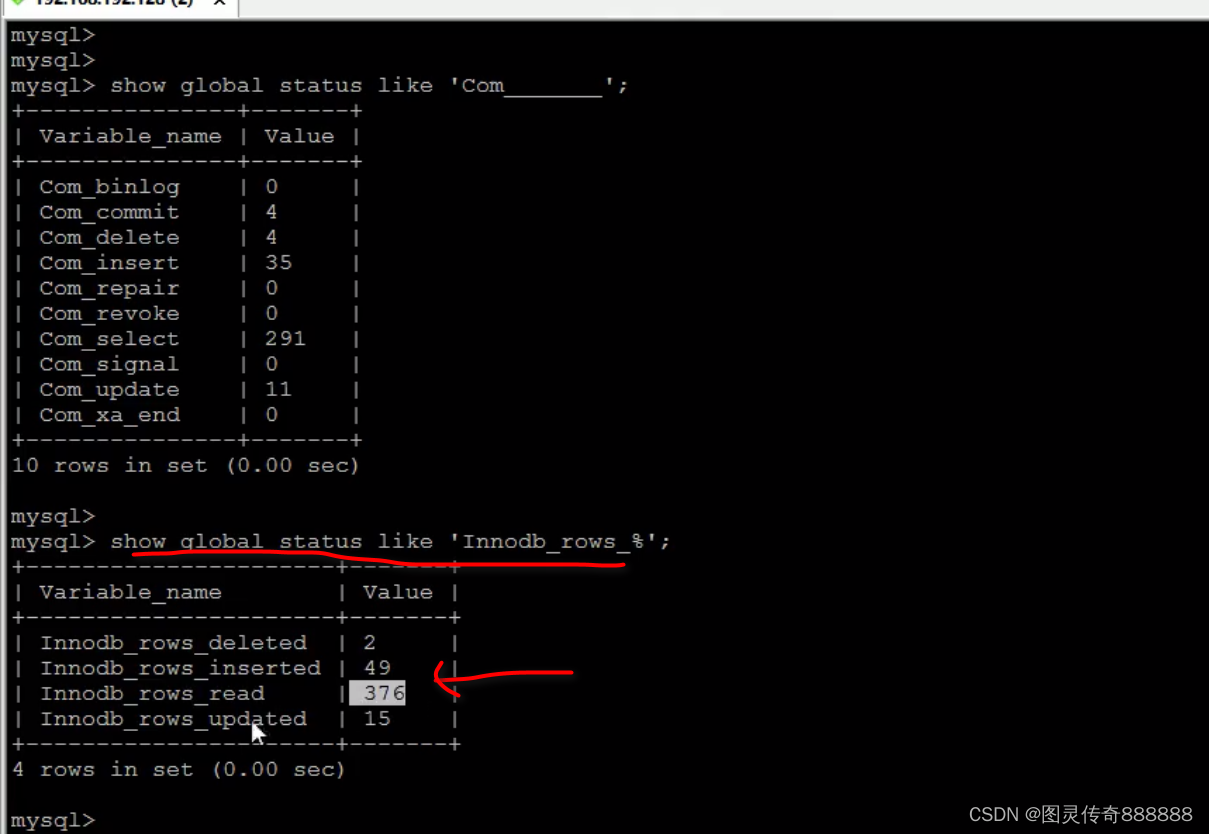
show status like 'Com_______';
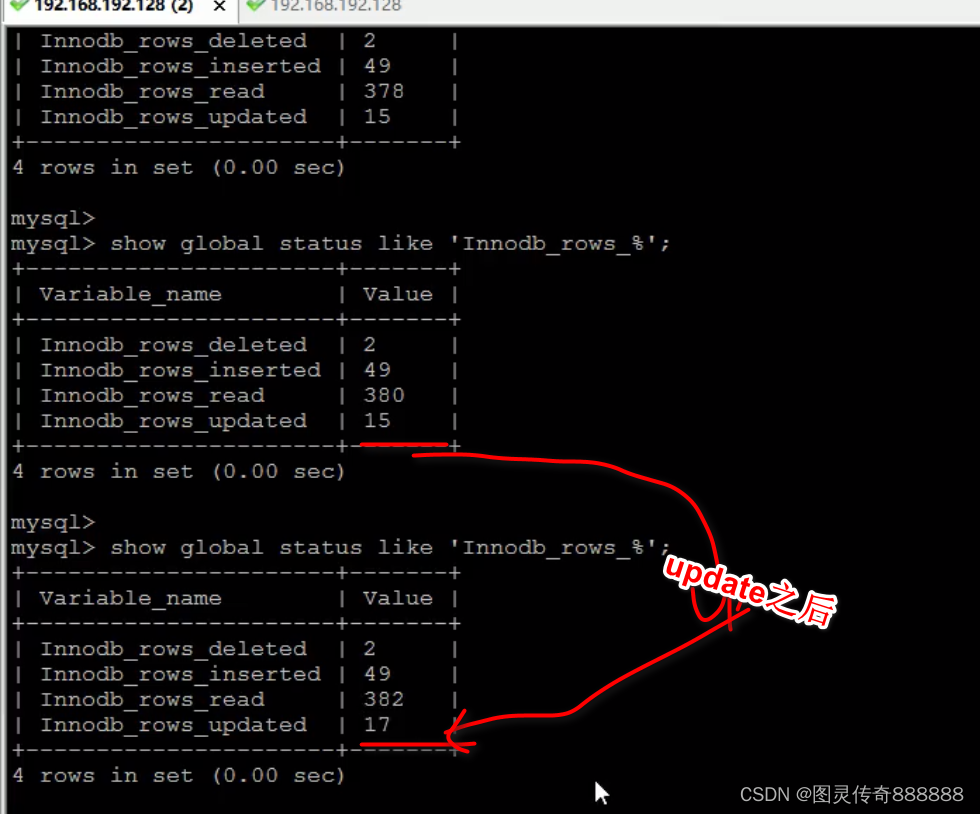
show global status like 'Innodb_rows%';
查询到goods_innobd表中有两行数据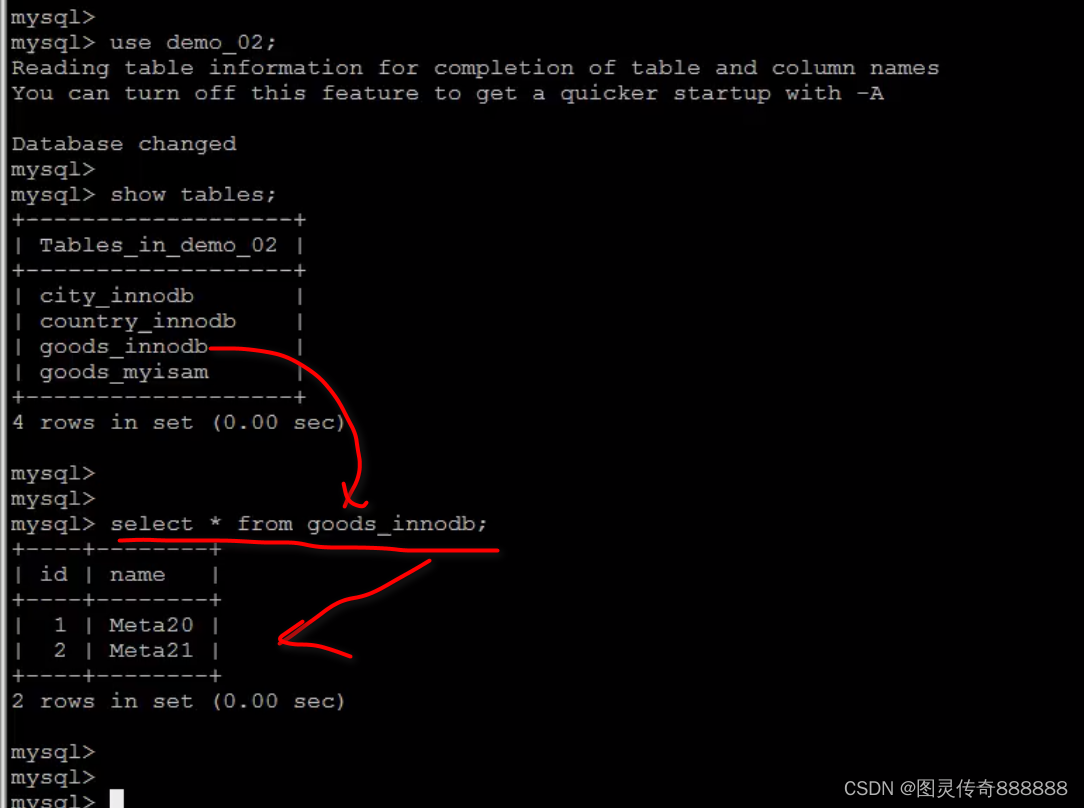
查询之后数据表行自动统计了统计两行,ows_read表示读取的行数有多少行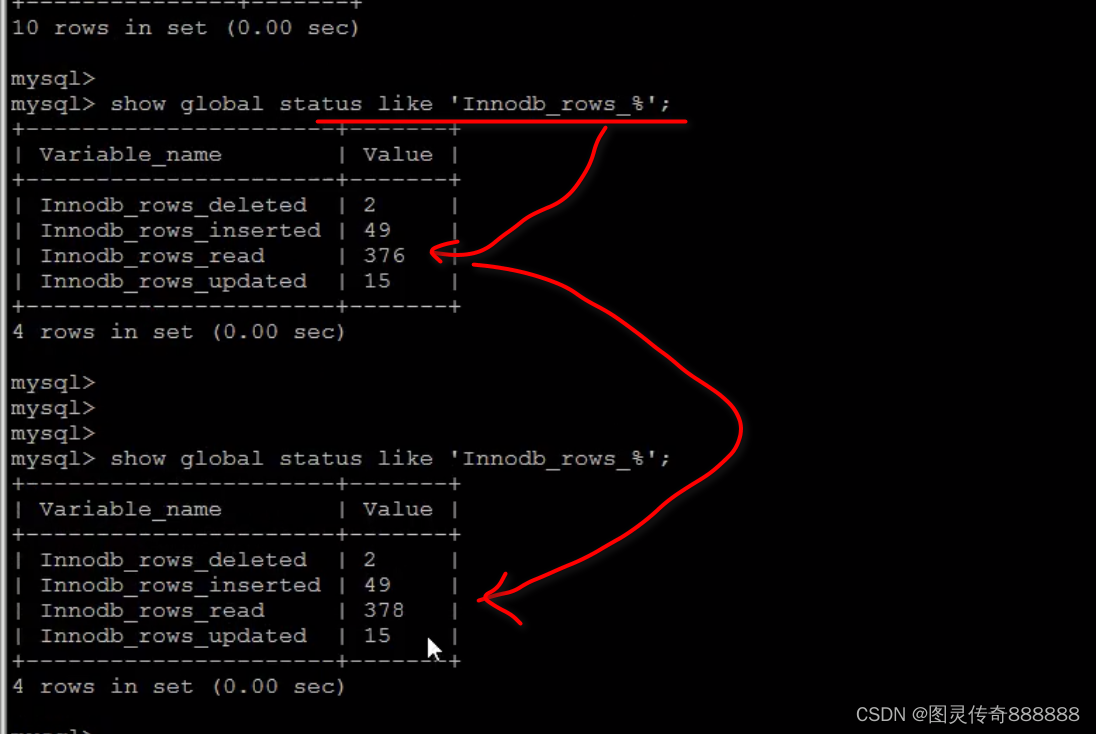
删除与更新插入show global status like 'Innodb_rows%';都会自动统计
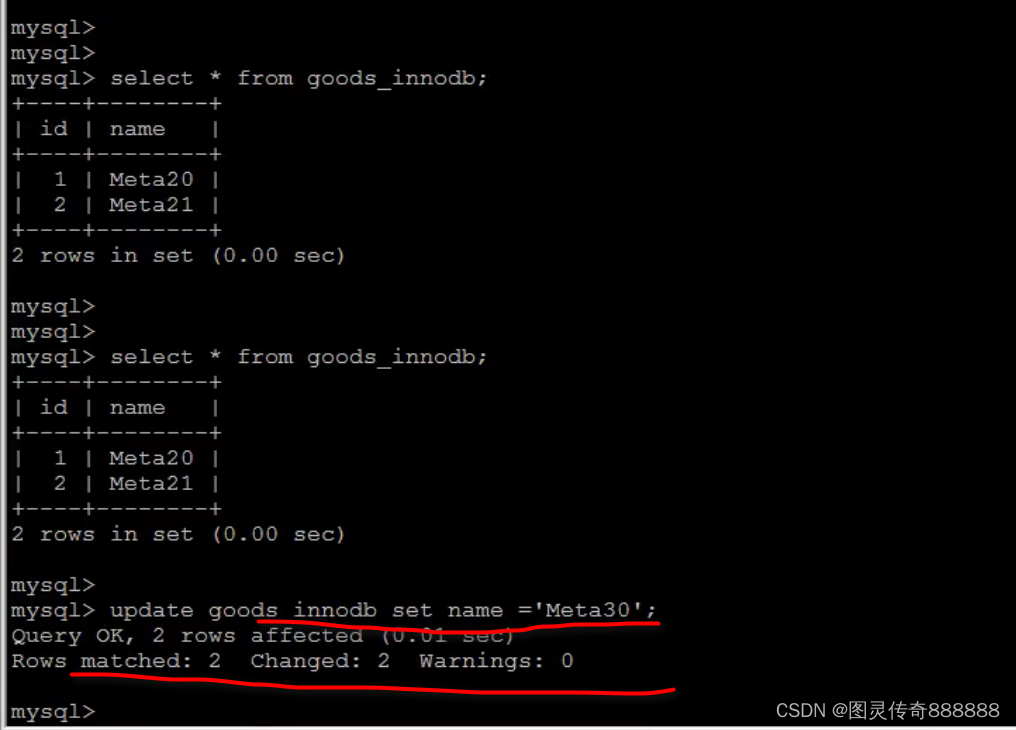
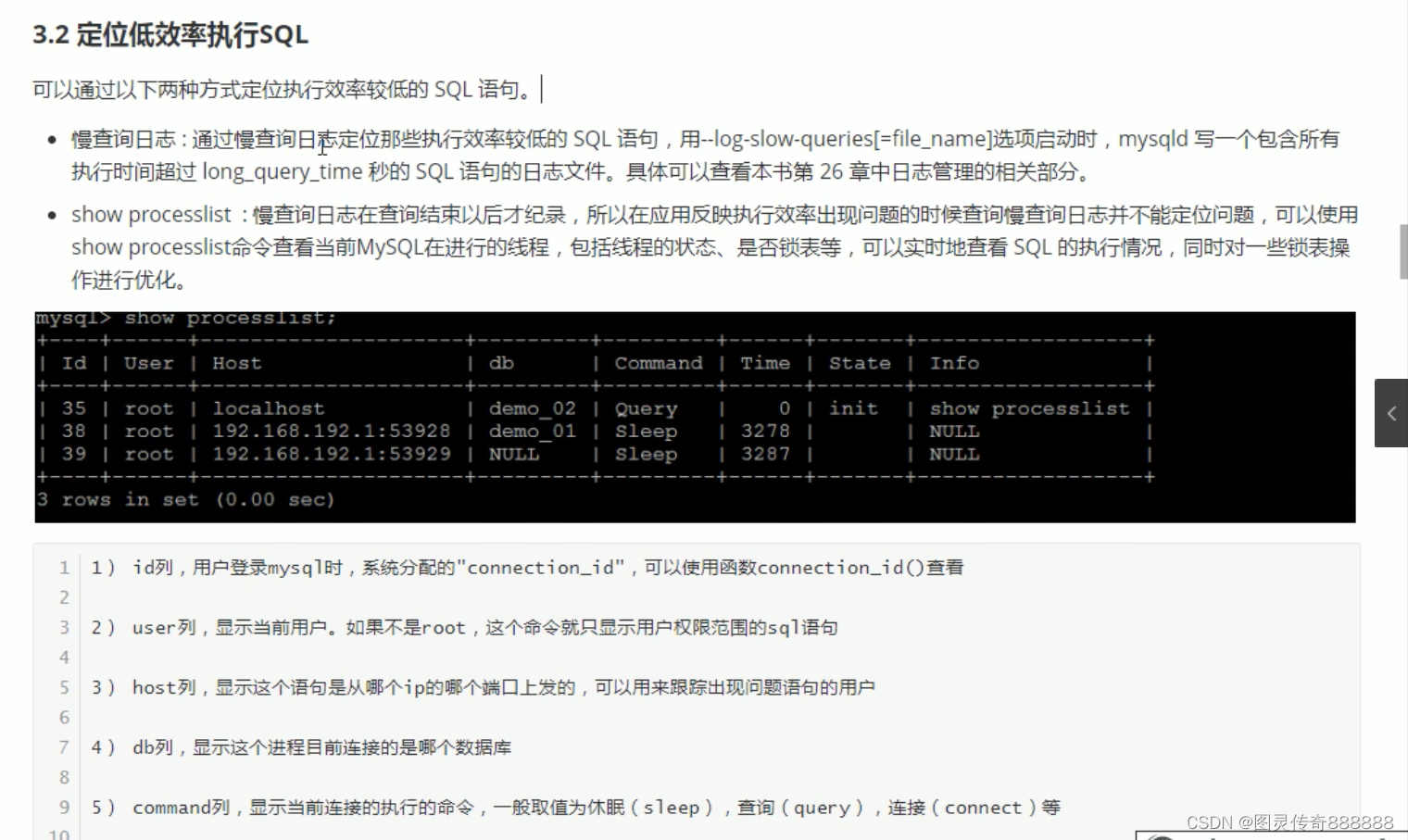
定位低效的sql语句
show processlist; 慢查询日志
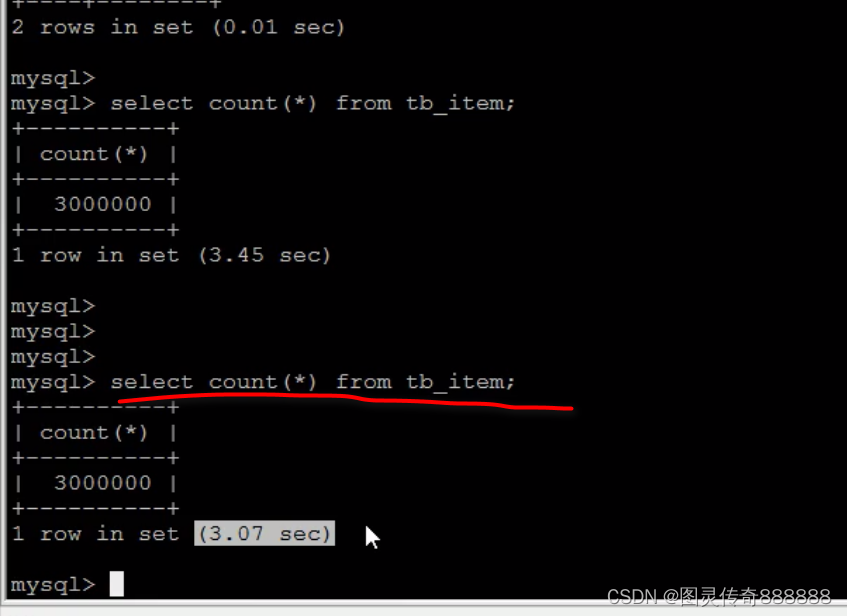
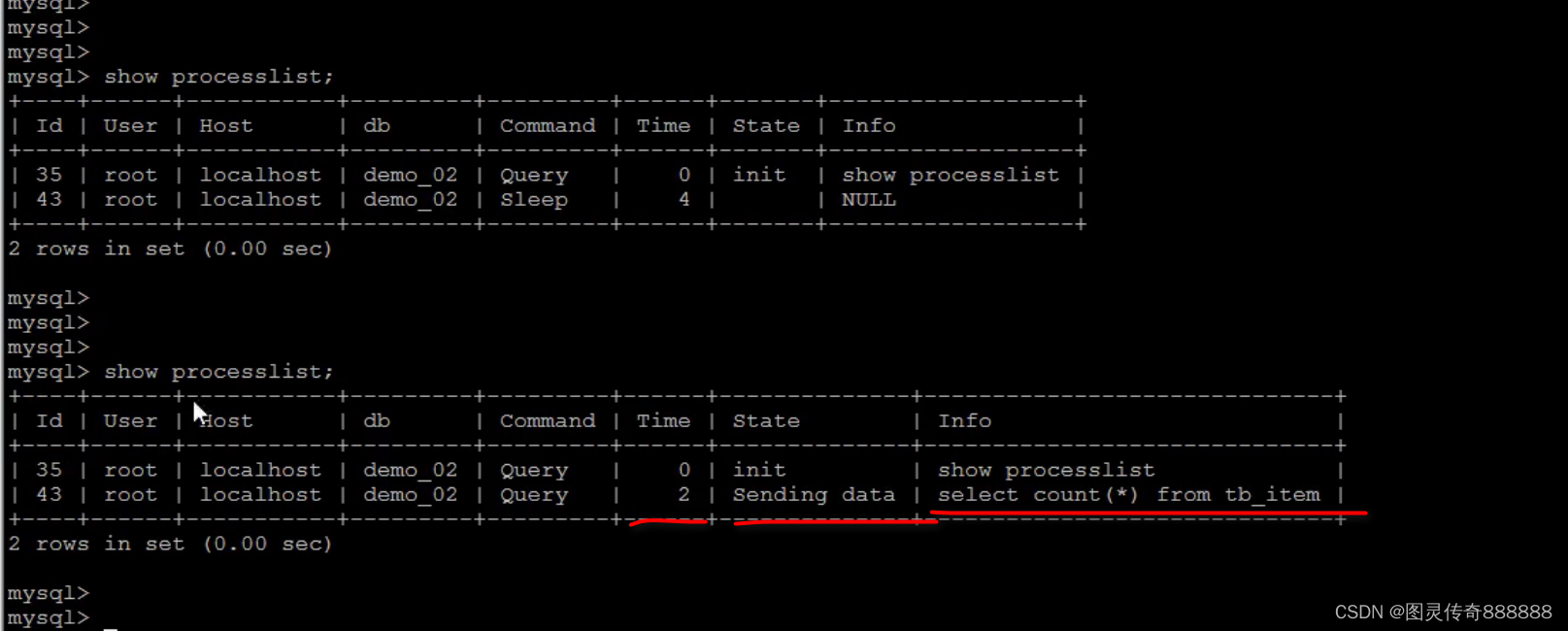
查询一个有三百万条记录的数据表
explain 查询重点
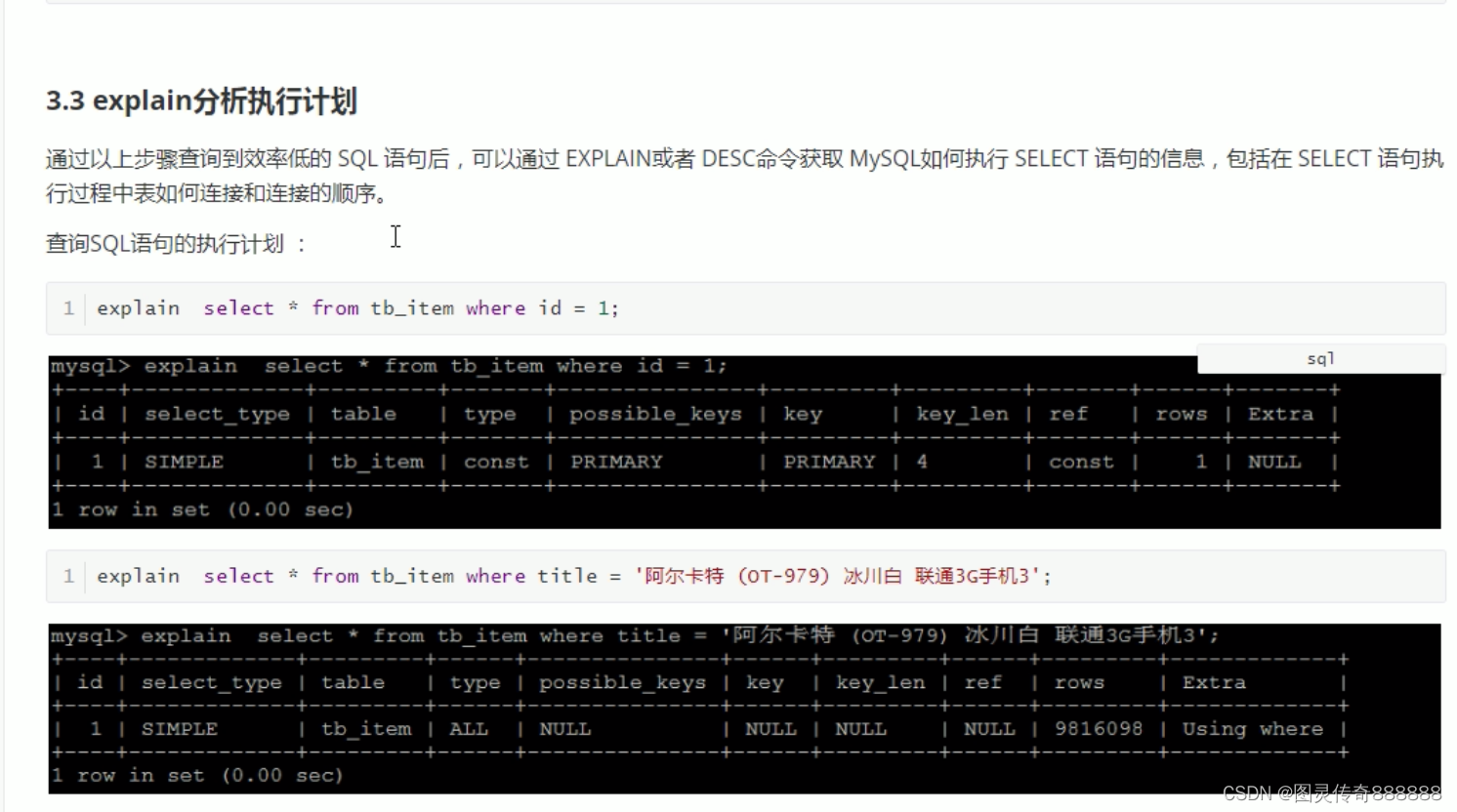
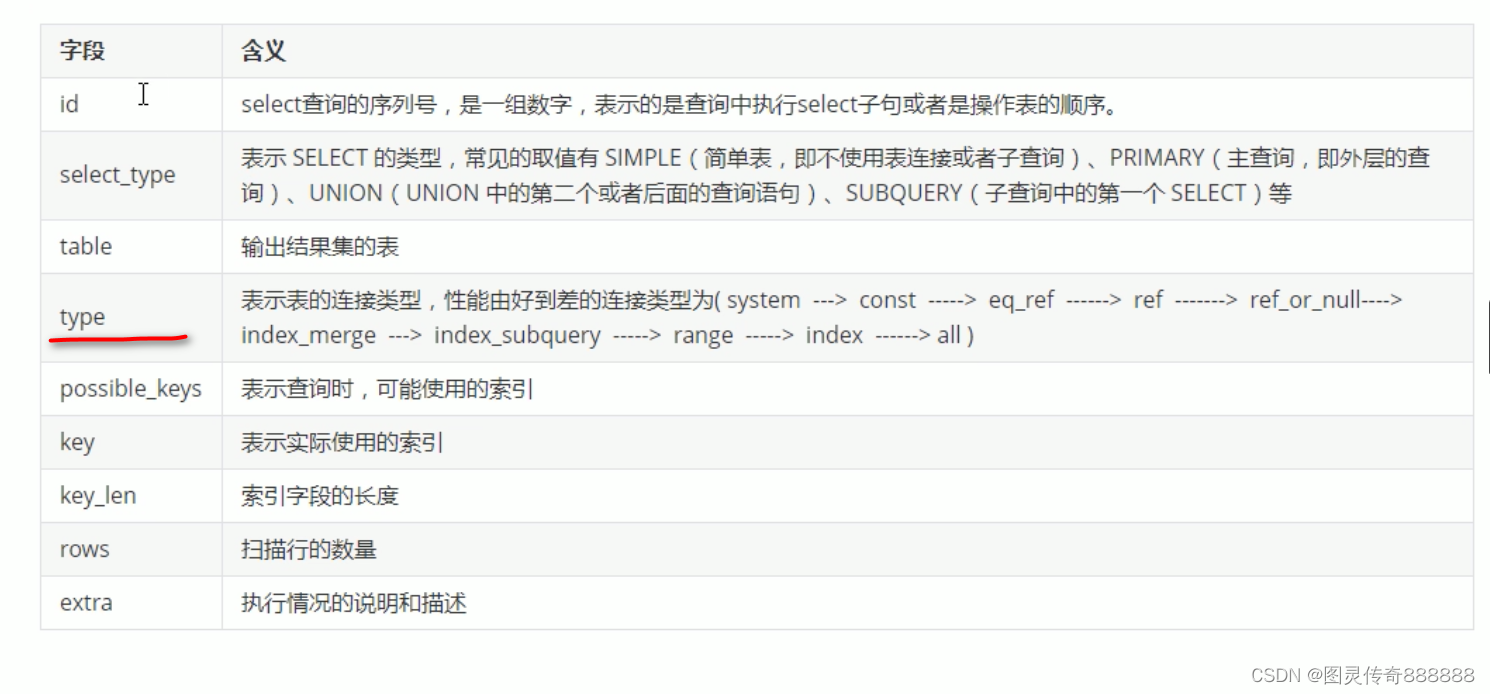
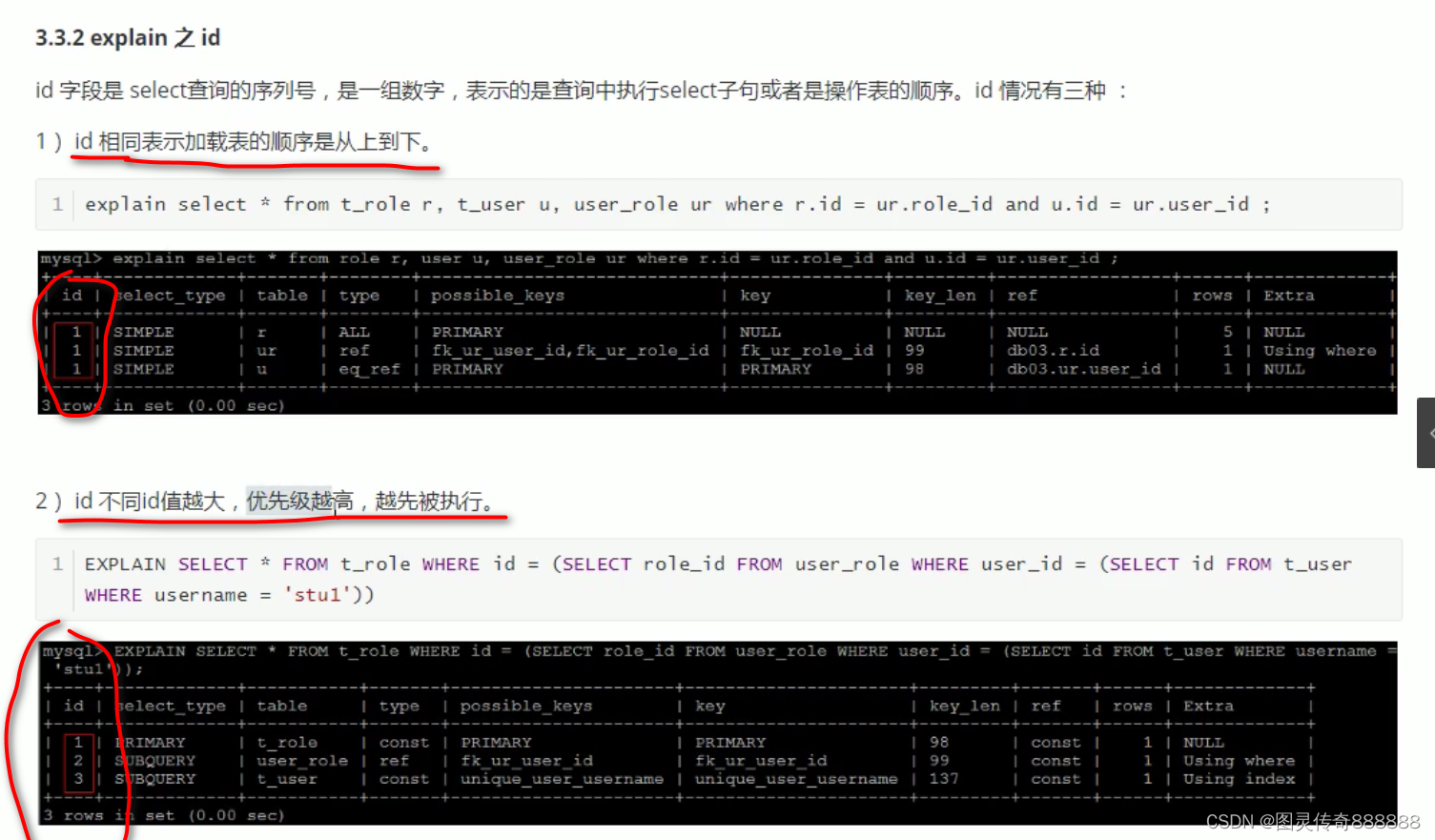
explain之id
explain之select_type
explain之type
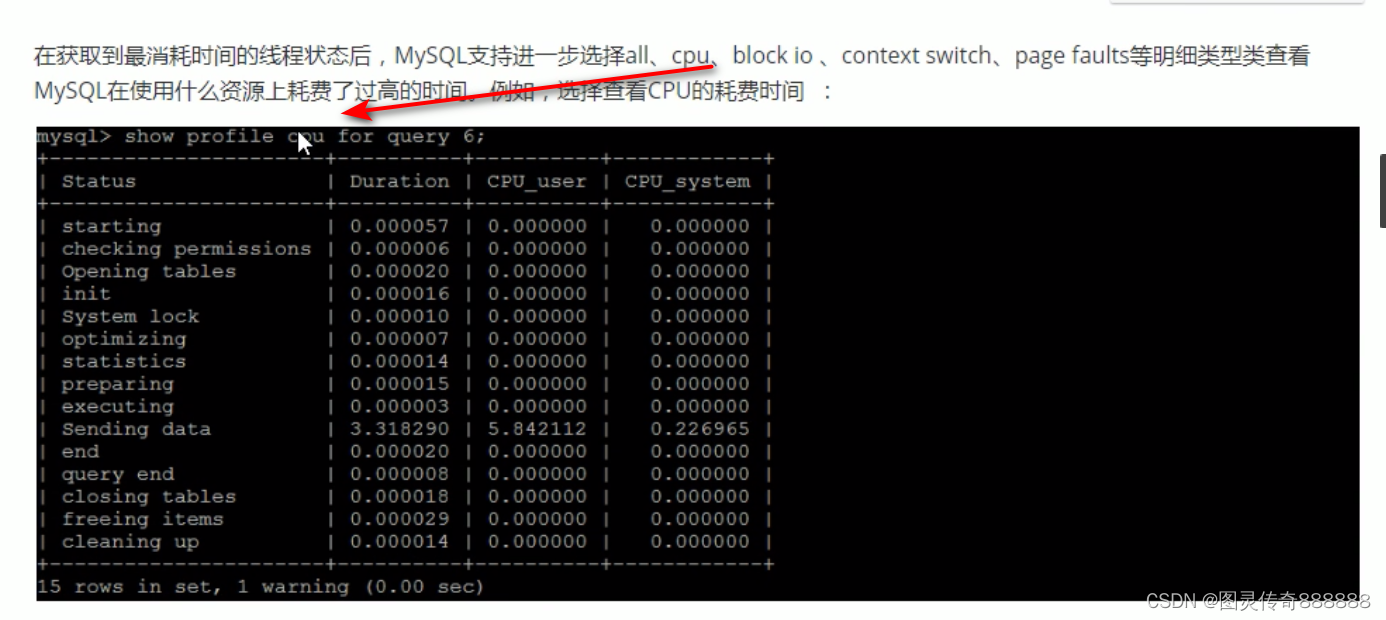
分析sql语句性能的show profile
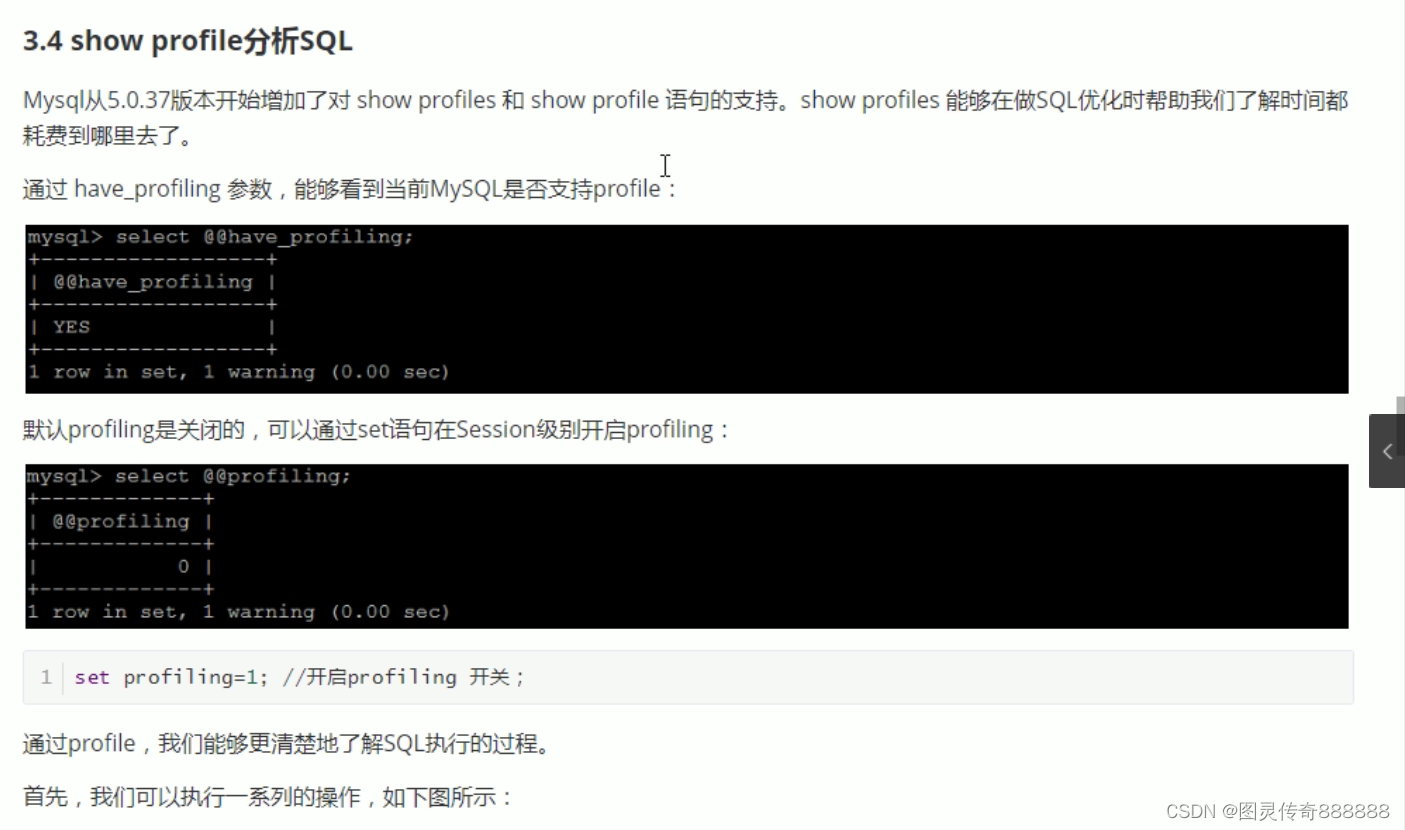
show profiles; 列出所有语句耗时
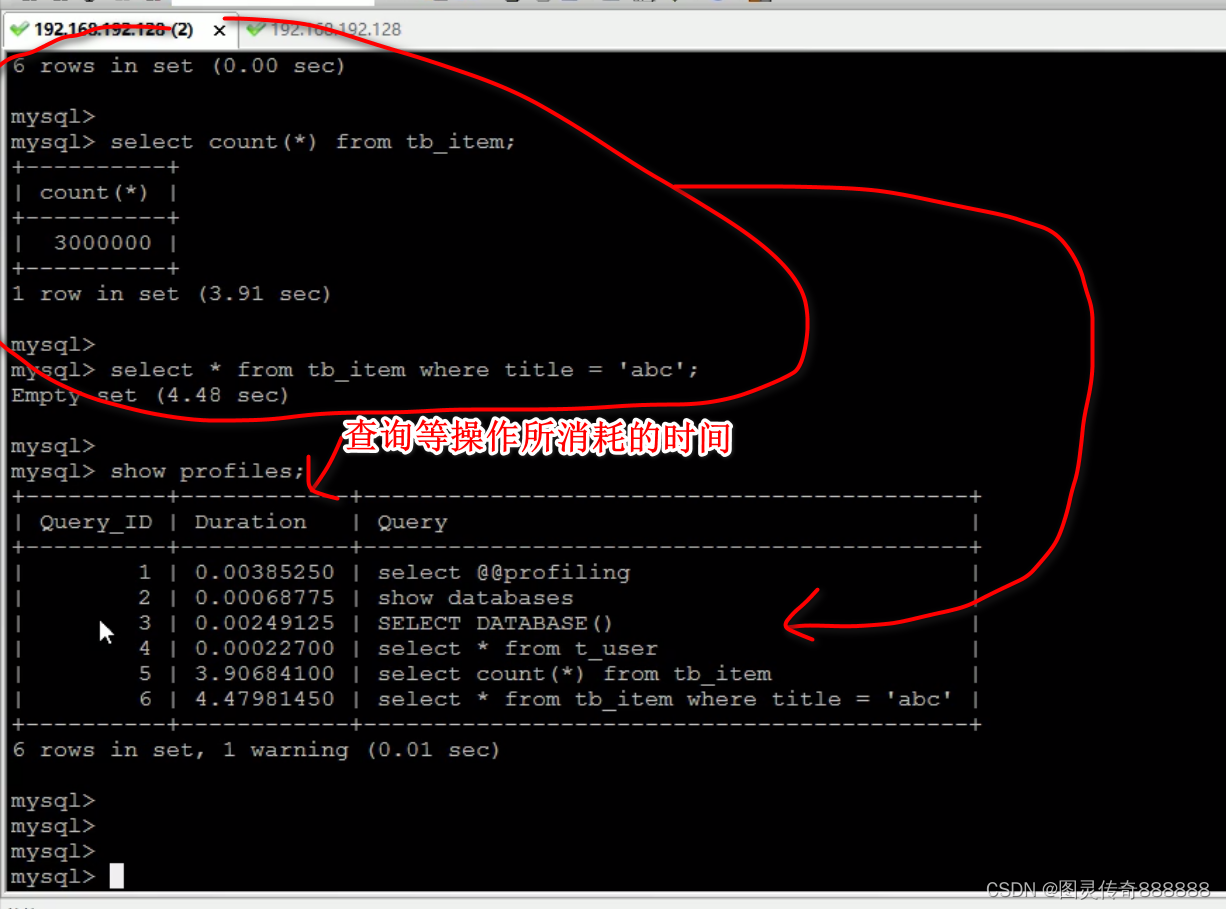
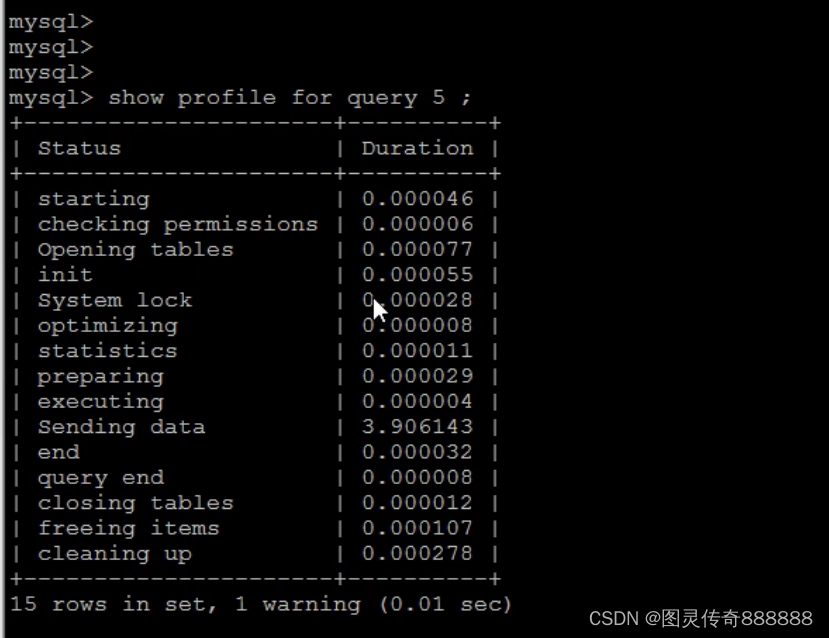
shw profile for query 5; 分析单条语句耗时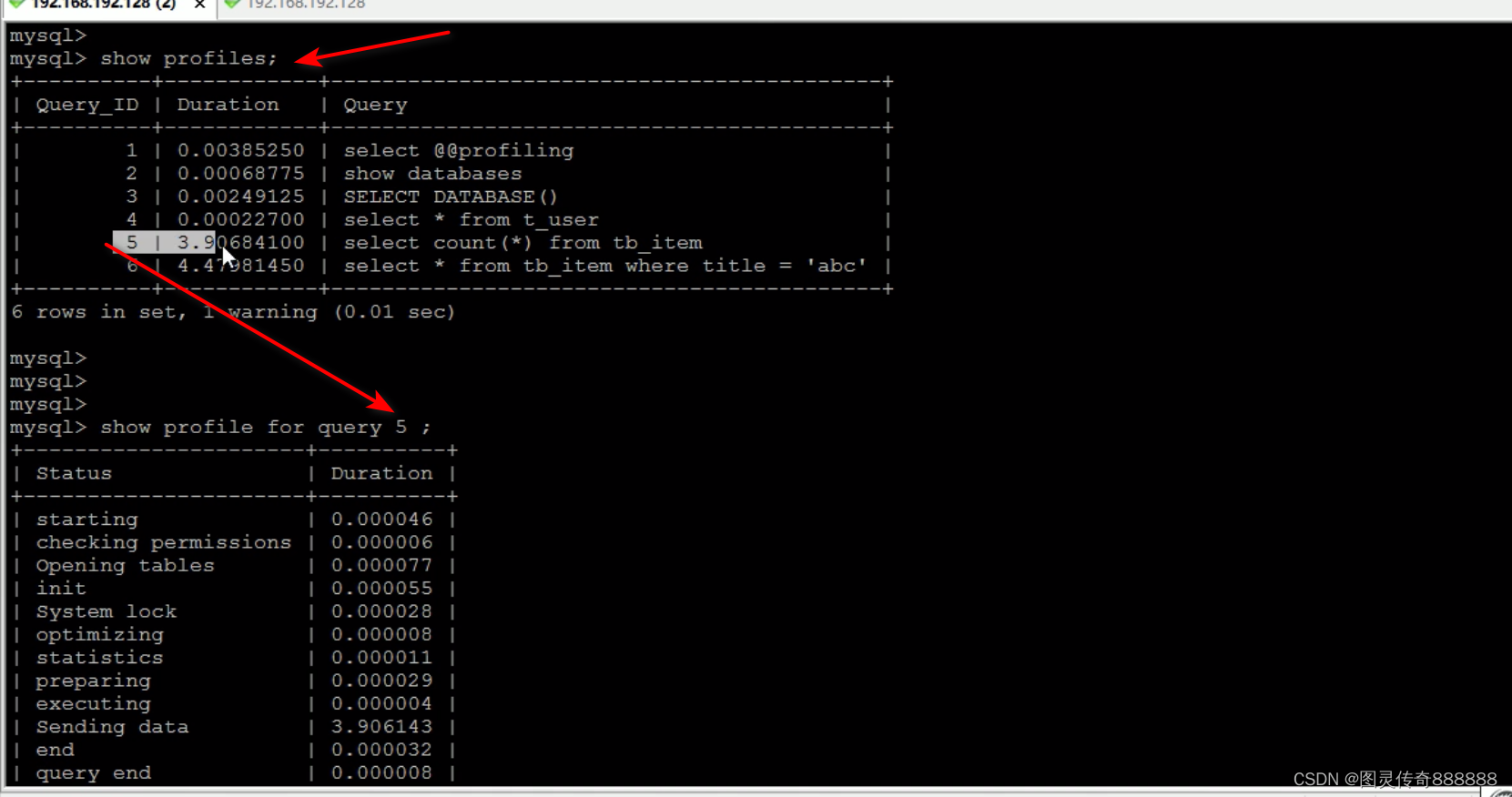
列出各个阶段所消耗的时间
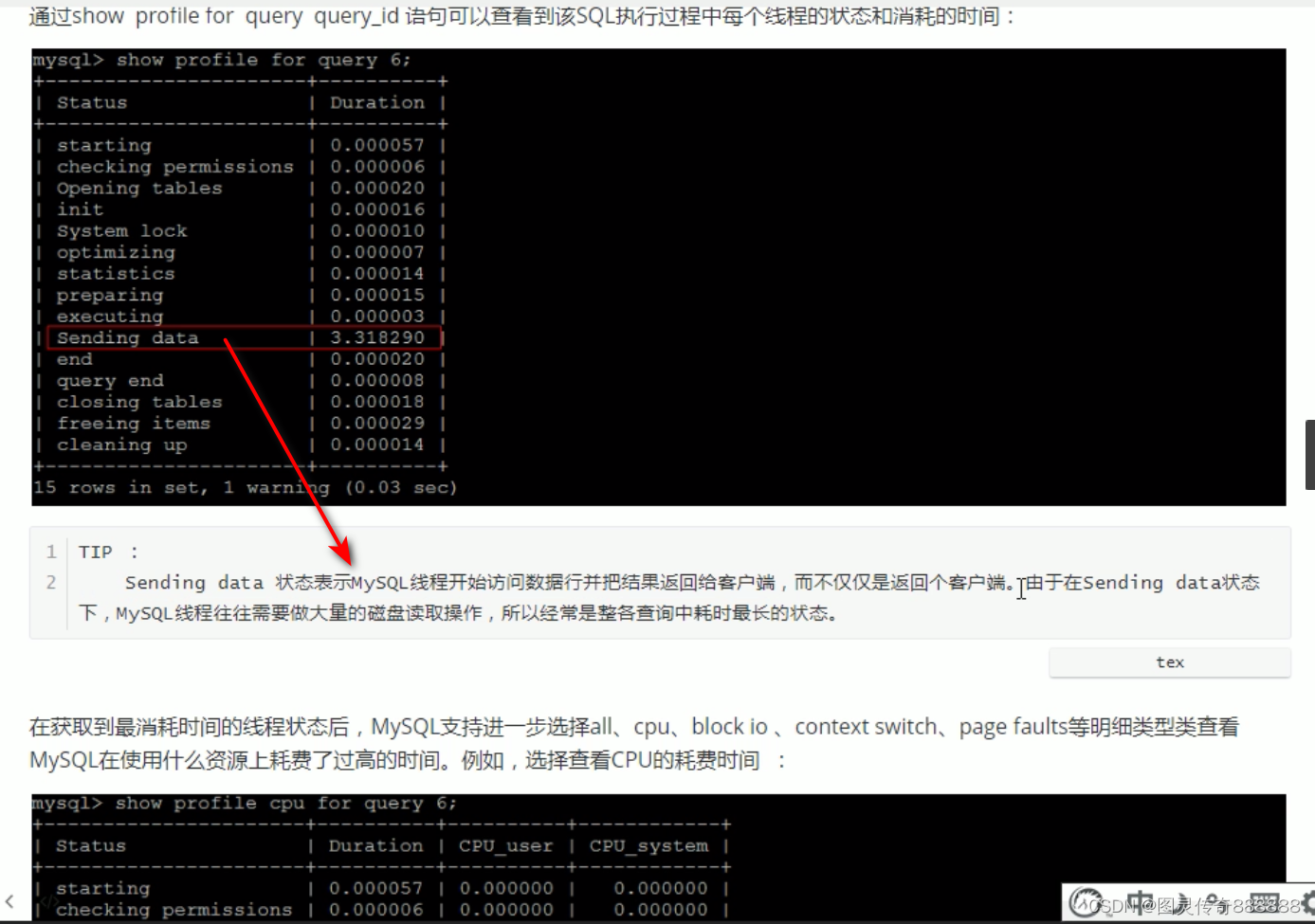
也可以加上一些参数查看
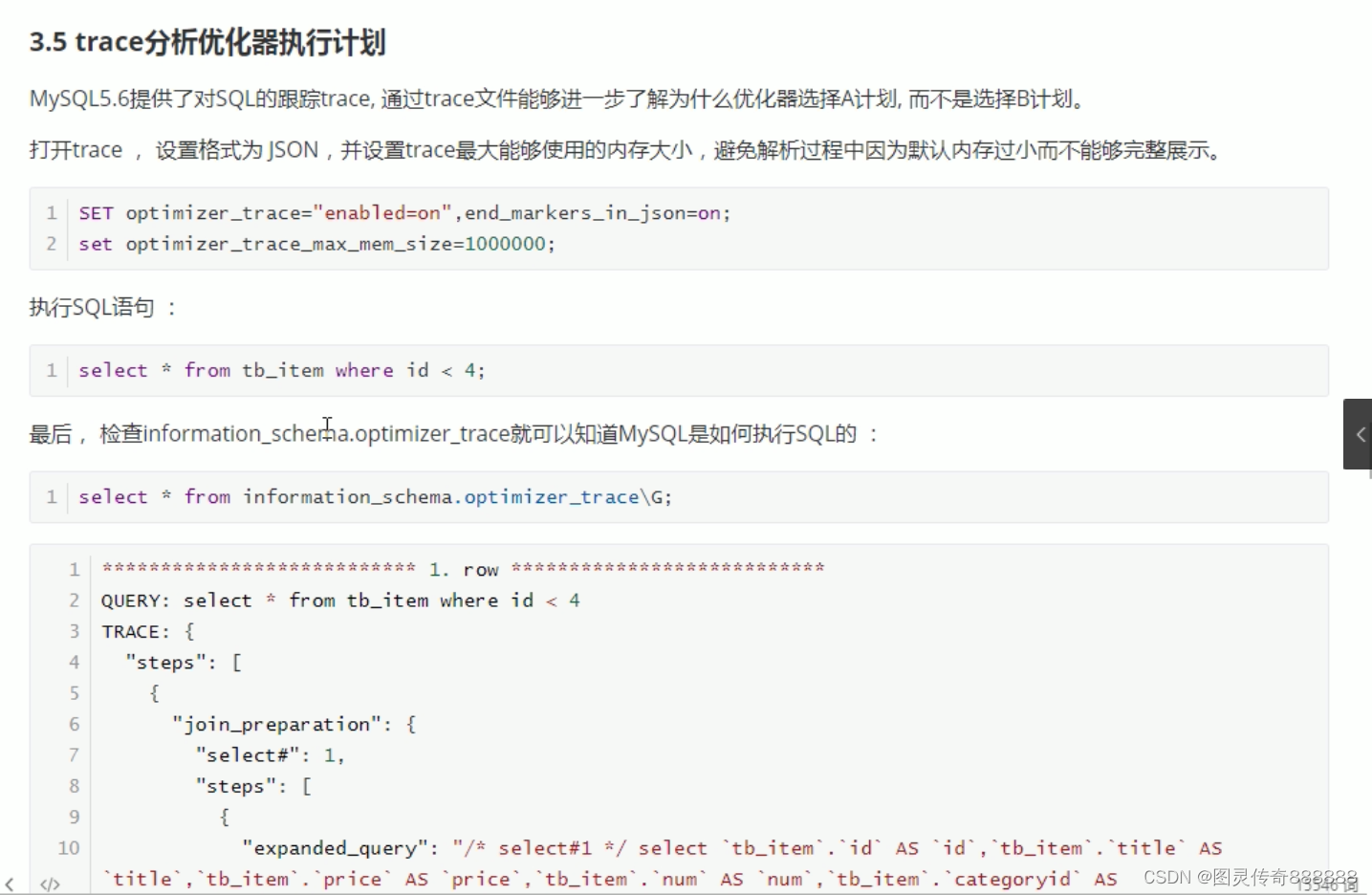
trace 分析优化器执行计划
mysql MVCC
一、什么是MVCC
MVCC,全称Multi-Version Concurrency Control,即多版本并发控制,是一种并发控制的方法,一般用在数据库管理系统中,实现对数据库的并发访问,比如在MySQL InnoDB中主要是为了提高数据库并发性能,不用加锁,非阻塞并发读。
MVCC多版本并发控制指的是维持一个数据的多个版本,使得读写操作没有冲突,快照读是MySQL为实现MVCC的一个非阻塞读功能。
二、解决的问题是什么
1、三种数据库并发场景:
读读:不会有问题,也不需要并发控制
读写:有线程安全问题,可能会造成事务隔离性问题,可能遇到脏读、幻读、不可重复读
写写:有线程安全问题,可能存在更新丢失问题
3.mvcc实现原理
三、实现原理
主要依赖于记录中的三个隐藏字段、undolog,read view来实现的。
1、隐藏字段
每行记录,除了我们自定义的字段外,还有数据库隐式定义的DB_TRX_ID,DB_ROLL_PTR,DB_ROW_ID等字段:
DB_ROW_ID:6字节,隐藏的主键,如果数据表没有主键,那么innodb会自动生成一个6字节的row_id
DB_TRX_ID:6字节,最近修改事务id,记录创建这条记录或者最后一次修改该记录的事务id
DB_ROLL_PTR:7字节,回滚指针,用于配合undo日志,指向上一个旧版本

在mysql存储的数据中,除了我们显式定义的字段,mysql会隐含的帮我们定义几个字段。
trx_id:事务id,每进行一次事务操作,就会自增1。
roll_pointer:回滚指针,用于找到上一个版本的数据,结合undolog进行回滚。
2、undolog
1)概念
回滚日志,表示在进行insert,delete,update操作的时候产生的方便回滚的日志。
2)说明
当进行insert操作的时候,产生的undolog,只在事务回滚的时候需要用到,并且在事务提交之后可以被立刻丢弃
当进行update和delete操作的时候,产生的undolog,不仅仅在事务回滚的时候需要,在快照读的时候也需要,所以不能随便删除,只有在快照读或事务回滚不涉及该日志时,对应的日志才会被purge线程统一清除
当数据发生更新和删除操作的时候,实际只是设置了旧记录的deleted_bit,并不是将过时的记录删除,因为为了节省磁盘空间,innodb有专门的purge线程来清除deleted_bit为true的记录,如果某个记录的deleted_id为true,并且DB_TRX_ID相对于purge线程的read view 可见,那么这条记录就是可以被清除的
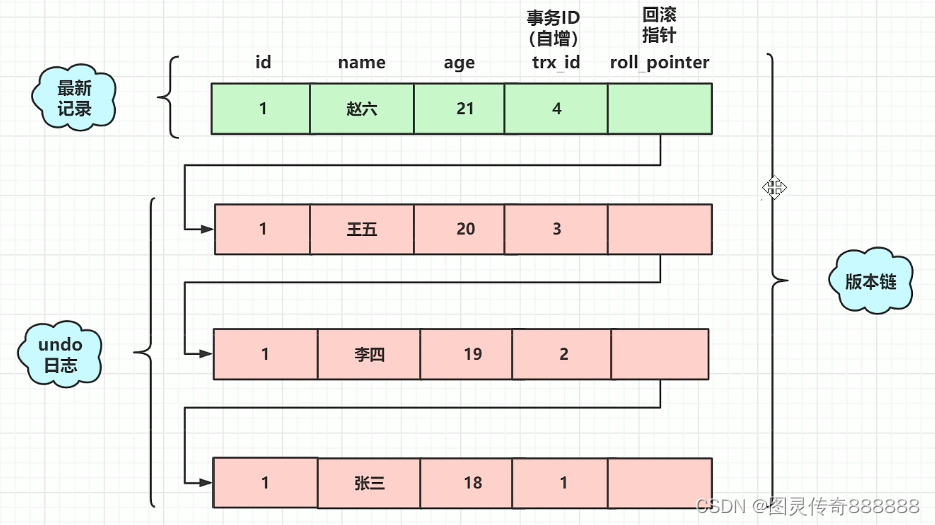
3)undolog生成的记录链表
(1)假设有一个事务编号为1的事务向表中插入一条记录,那么此时行数据如下,主键id=1,事务id=1

(2)假设有第二个事务(编号为2)对该记录的name做出修改,改为lisi
底层操作:在事务2修改该行记录数据时
1、对该数据行加排他锁
2、把该行数据拷贝到undolog中,作为旧记录
3、修改该行name为lisi,并且修改事务id=2,回滚指针指向拷贝到undolog的副本记录中
4、提交事务,释放锁
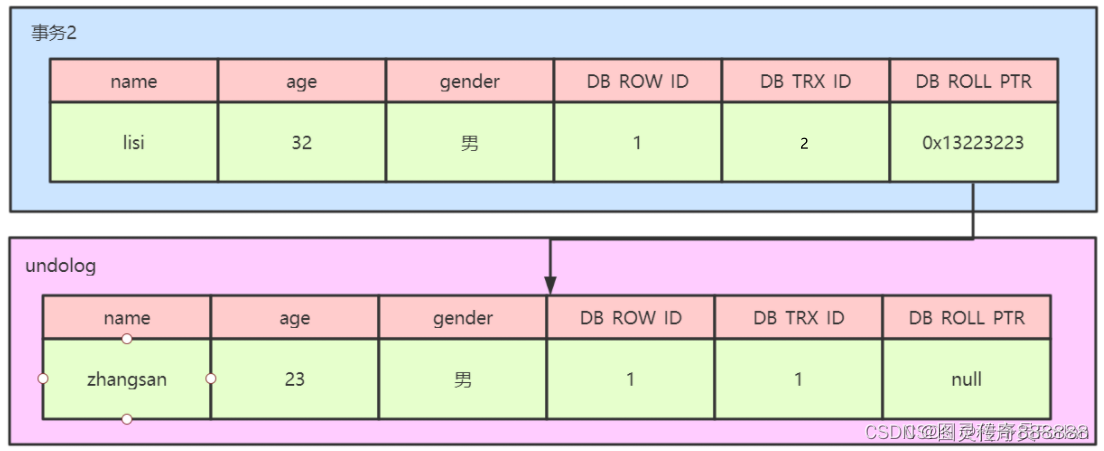
(3)假设有第三个事务(编号为3)对该记录的age做了修改,改为32
底层操作:在事务3修改该行记录数据时
1、对该数据行加排他锁
2、把该行数据拷贝到undolog中,作为旧记录,发现该行记录已经有undolog了,那么最新的旧数据作为链表的表头,插在该行记录的undolog最前面
3、修改该行age为32岁,并且修改事务id=3,回滚指针指向刚刚拷贝的undolog的副本记录
4、提交事务,释放锁
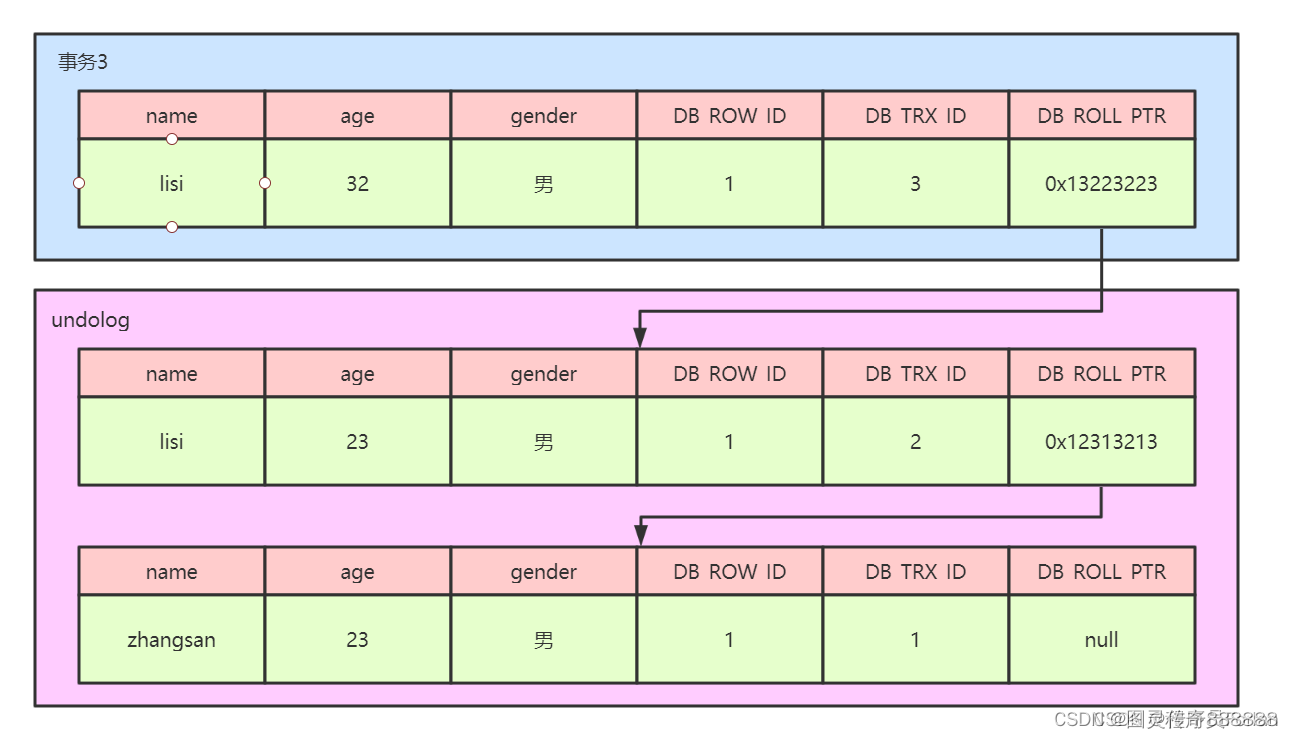
从上述的一系列图中,可以发现,不同事务或者相同事务的对同一记录的修改,会导致该记录的undolog生成一条记录版本链表,undolog的表头就是最新的旧记录,表尾就是最早的旧记录。
3、read view
Read View是事务进行快照读操作的时候生产的读视图,在该事务执行快照读的那一刻,系统会生成一个此刻的快照,记录并维护系统此刻活跃事务的id,用来做可见性判断的,也就是说当某个事务在执行快照读的时候,对该记录创建一个Read View的视图,把它当作条件去判断当前事务能够看到哪个版本的数据,有可能读取到的是最新的数据,也有可能读取到的是当前行记录的undolog中某个版本的数据
1)可见性算法
将要被修改的数据的最新记录中的DB_TRX_ID(当前事务id)取出来,与系统此刻其他活跃事务的id去对比,如果DB_TRX_ID跟Read View的属性做了比较,不符合可见性,那么就通过DB_ROLL_PTR回滚指针去取出undolog中的DB_TRX_ID做比较,即遍历链表中的DB_TRX_ID,直到找到满足条件的DB_TRX_ID,这个DB_TRX_ID所在的旧记录就是当前事务能看到的数据。
2)可见性规则
首先要知道Read View中的三个全局属性:
trx_list:一个数值列表,用来维护Read View生成时刻系统正活跃的事务ID(1,2,3)
up_limit_id:记录trx_list列表中事务ID最小的ID(1)
low_limit_id:Read View生成时,系统即将分配的下一个事务ID(4)
具体的比较规则如下:
首先比较DB_TRX_ID < up_limit_id
如果小于,则当前事务能看到DB_TRX_ID所在的记录
如果大于等于,则进入下一个判断
接下来判断DB_TRX_ID >= low_limit_id
如果大于等于,则代表DB_TRX_ID所在的记录在Read View生成后才出现的,那么对于当前事务不可见
如果小于,则进入下一步判断
判断DB_TRX_ID是否在活跃事务中,trx_list包含DB_TRX_ID
如果包含,则代表在Read View生成的时候,这个事务还是活跃状态,未commit的数据,当前事务也是看不到
如果不包含,则说明这个事务在Read View生成之前就已经开始commit,那么修改的结果是能够看见的
流程图如下:
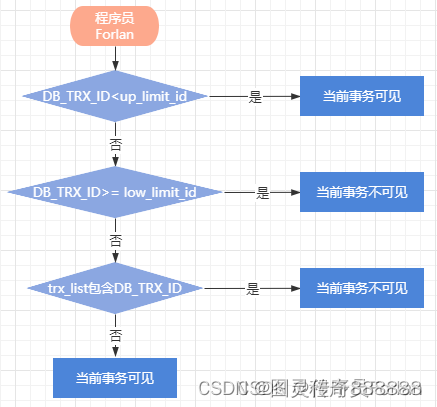
总结:两种情况可见
DB_TRX_ID < up_limit_id
DB_TRX_ID不在trx_list范围内,且小于low_limit_id
四、整个流程
假设有四个事务同时在执行,如下图所示:
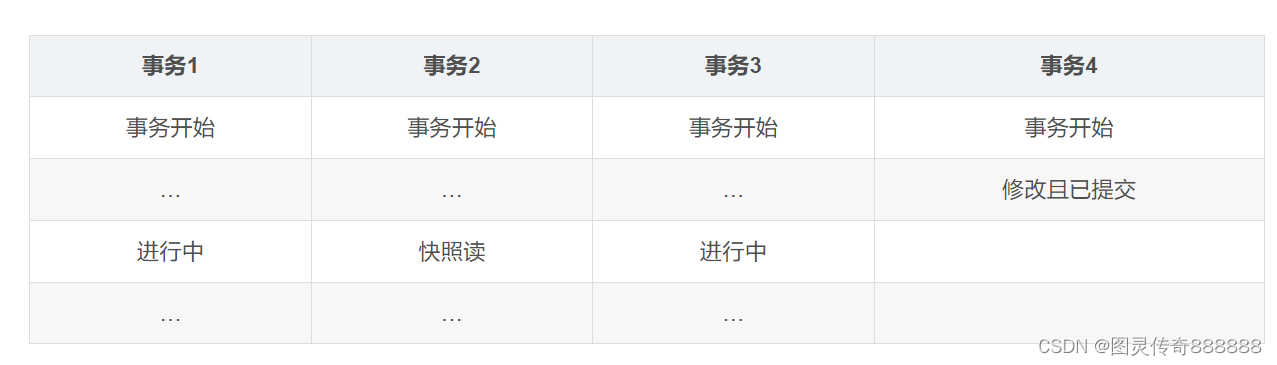
从上述表格中,我们可以看到,当事务2对某行数据执行了快照读,数据库为该行数据生成一个Read View视图,可以看到事务1和事务3还在活跃状态,事务4在事务2快照读的前一刻提交了更新,所以在Read View中记录了系统当前活跃事务1,3,维护在一个列表中。同时可以看到up_limit_id的值为1,而low_limit_id为5,如下图所示:
在上述的例子中,只有事务4修改过该行记录,并且在事务2进行快照读前,就提交了事务,所以该行当前数据的undolog如下所示:
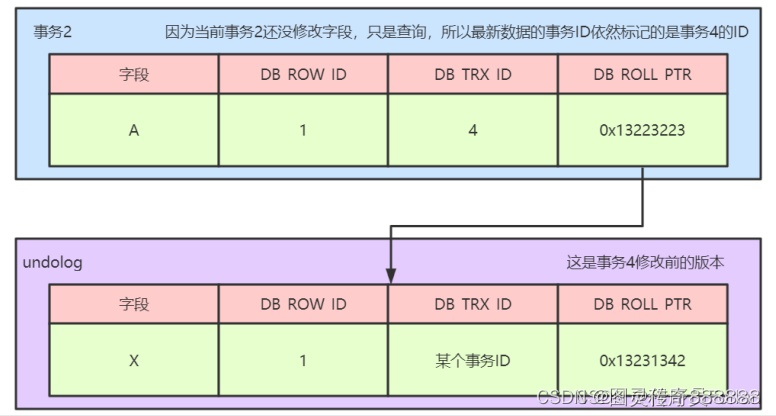
当事务2在快照读该行记录时,会拿着该行记录的DB_TRX_ID去跟up_limit_id、lower_limit_id和活跃事务列表进行比较,从而判读事务2能看到该行记录的版本是哪个。
具体流程如下:
拿该行记录的事务ID(4)去跟Read View中的up_limit_id(1)相比较,判断是否小于,通过对比发现不小于,所以不符合条件
继续判断4是否大于等于low_limit_id(5),通过比较发现也不大于,所以不符合条件
判断事务4是否处理trx_list列表中,发现不在列表中,那么符合可见性条件
所以事务4修改后提交的最新结果对事务2的快照是可见的,因此事务2读取到的最新数据记录是事务4所提交的版本,而事务4提交的版本也是全局角度的最新版本。
五、拓展
1、当前读
读取的是最新版本的记录,读取时还要保证其它并发事务不能修改当前记录,会对读取的记录进行加锁
共享锁:select lock in share mode
排它锁:select for update 、update、 insert 、delete
2、快照/普通读
1)概念
像不加锁的select操作,就是快照读,即非阻塞读
2)为什么会出现快照读?
是基于提高并发性能的考虑,快照读是基于多版本并发控制,即MVCC,可以认为MVCC是行锁的一个变种,但它在很多情况下,避免了加锁操作,降低了开销;
3)存在问题
基于多版本,读到的并不一定是数据的最新版本,可能是之前的历史版本
串行级别下的快照读会退化成当前读
3、RC、RR级别下的InnoDB快照读有什么不同
因为Read View生成时机的不同,从而造成RC、RR级别下快照读的结果的不同
在RC级别下,事务中,每次快照读都会新生成一个快照和Read View,这就是我们在RC级别下的事务中可以看到别的事务提交的更新的原因
在RR级别下,某个事务的对某条记录的第一次快照读会创建一个快照(Read View),将当前系统活跃的其他事务记录起来,此后在调用快照读的时候,还是使用的是同一个Read View,所以只要当前事务在其他事务提交更新之前使用过快照读,那么之后的快照读使用的都是同一个Read View,之后的修改对其不可见
总结:在RC隔离级别下,是每个快照读都会生成并获取最新的Read View,而在RR隔离级别下,则是同一个事务中的第一个快照读才会创建Read View,之后的快照读获取的都是同一个Read View.
4、 RR级别下怎么避免幻读
快照读,和避免不可重复读原理一样,可以避免幻读
当前读,因为每次都是读取新的快照,如果需要避免,可以通过加锁
限制新增或删除相同条件的数据


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









