







 本文介绍了零基础开发Spark实时计算程序的过程,重点讲解了Kafka的作用和Spark的功能,以及如何学习Spark。文章还讨论了Kafka、Spark和Hadoop的不同版本之间的关系,并分享了在开发过程中遇到的版本匹配问题及其解决方案。
本文介绍了零基础开发Spark实时计算程序的过程,重点讲解了Kafka的作用和Spark的功能,以及如何学习Spark。文章还讨论了Kafka、Spark和Hadoop的不同版本之间的关系,并分享了在开发过程中遇到的版本匹配问题及其解决方案。
摘要
为了完成数据实时ETL功能,项目使用kafka进行接收,spark进行实时计算,再通过kafka输出。在零基础入门的过程中,顺带解决了几个版本相关的问题:1)低版本spark和kafka使用structure streaming的问题;2)低版本spark无法向kafka写入数据的问题。因此,文章将分位如下几个部分。首先,是整理了kafka和spark的0基础入门相关问题。然后,梳理了kafka,spark和hadoop不同版本之间的关系。最后,介绍了工作过程中遇到的难点和解决问题的方法。
零基础入门
什么是kafka,为什么要用kafka
个人理解,kafka就是一个带管道的数据池,数据生成方(在kafka中被称为producer)通过一种颜色的管道(在kafka中被称为链路)向池子里灌数,数据使用方(在kafka中被称为consumer,数据消费)通过另一条相同颜色的管道消费数据。在这种机制下,不同的生产者使用不同管道向同一个大池子灌数,不同的消费者只要找同种颜色的管道就可以消费他关心的数据。这里的颜色就是topic,可以理解为加密双方约定的公钥。当然,实际项目中单条链路肯定是有多个topic,每个topic下也会通过offset管理历史数据,这就是后话了。

那么为什么要用kafka呢?因为SqlServer之类的传统关系型数据库,无法支撑大规模数据在短时间内(实时)完成高频的获取,存储,加工和输出的工作。当然,更重要的理由是,在kafka大规模应用的今天,很多数据就是kafka传过来的,不用不行。。。
什么是spark,为什么要用spark,如何学习spark
kafka解决的是数据的传输问题,但是在数据输入和输出之间的加工计算工作,则需要spark来完成。spark就是个计算器,输入1+1,spark返回2,听起来好像很蠢,但是当数据规模很大,尤其是数据实时输入的时候,spark就不可或缺了。spark的优势很多资料都有介绍,大部分都看不懂。。。就不写了,毕竟对标的其他方式我也没接触过。这里就说说以够用为目的的学习方式。
spark分为两部分:spark core和spark api。官方文档的地址里,latest换成spark版本就可以切换到对应的文档了。实在英文无力的话可以用谷歌翻译或者看翻译版。具体的学习看这一篇。
http://spark.apache.org/docs/latest/
http://spark.apache.org/docs/2.2.0/

IDEA、Maven、scala相关概念
IDEA是代码编辑和运行的软件,入门可以看这一篇,主要是用来开发Java用的比较多,但是支持Scala,所以拿来写spark比较方便。这里插一句,从spark的官方文档看,虽然Scala,Java,Python和R都支持开发saprk程序,但从网上可以找到的分享代码来看,Scala占了大部分,很少有Java,Python更是没见过几次,R就。。。一次都没见过,而且部分API接口的例子只演示了Scala和Java,不清楚对其他语言是否支持,所以虽然人生苦短,但是该学的新语言还是免不了。
Maven是管理代码依赖包的插件,集成在IDEA里了。举例来讲,代码里要引用下面的包
import org.apache.spark.sql._
import com.google.xxx._
那么只要在Maven生成的pom.xml文件里按格式添加,Maven就可以从默认的仓库里自动下载对应的包,自动放在xxx/org/apache/spark/sql/目录,程序也就可以到这个目录引用了。如果因为物理隔离等原因,连不了外网,可以配置连接公司的私有仓库(如果有)进行下载,没有私有仓库或者私有仓库不全的话也可以参考这一篇手动下载jar包后导入。
下载jar包可以从这两个网站找
https://mvnrepository.com/
https://search.maven.org/
用下来感觉上面那个方便些,下面那个全一些。
版本
版本是个大坑,个人3周的开发时间里,2周是在版本的坑里打转。所以开始开发之前一定要确认几个版本问题:
- 集群的kafka版本
- 集群的spark版本
- 集群的hadoop版本
确定之后,开发使用的版本和集群版本对应,才能保证不出问题。
kafka版本
kafka大致上分2种版本,两种版本启动方式略有差别
之所以区分kafka的版本,主要因为2方面
- 如果使用Structure Streaming,因为它是spark2.3之后才成熟的新API,没有对10版本之前的kafka的官方支持。非官方支持见这一篇。GitHub上的源代码是针对spark2.1的,另一位中国的哥们又改了些代码push上去适配了spark2.2的,当时我还在版本的坑里打转,以此为基础又针对spark2.3改了些代码,重新编译了下,打包了成jar包,应该是可以同时适配spark2.2和2.3的,放出来给有需要的人吧。不过应用在集群上跑的时候总是跑几天就停了,不知道是不是这个包的原因,老版本kafka尽量还是用Spark Streaming吧。
下载地址
链接: https://pan.baidu.com/s/1H1zLxab94fsxs-Z77g-62g 提取码: ex7g
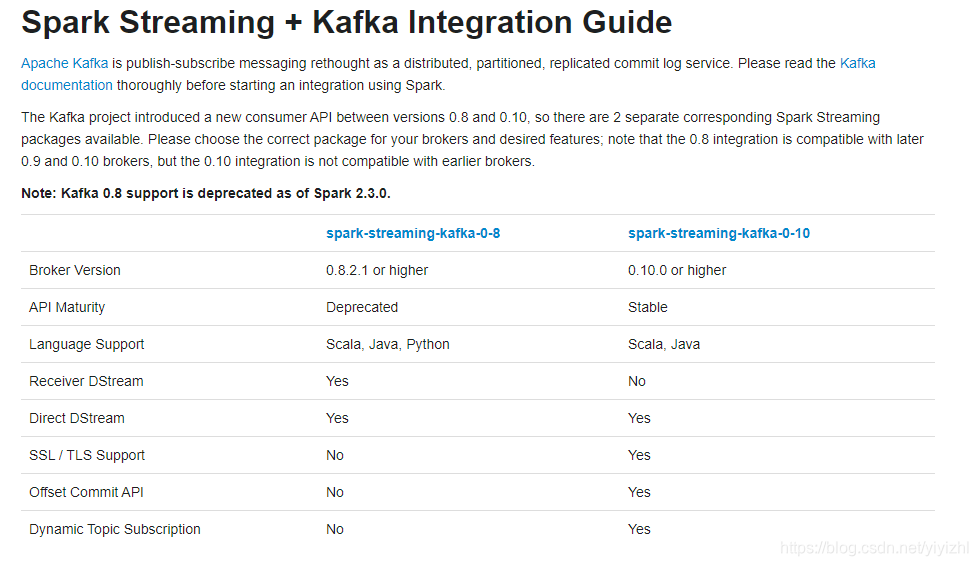
- 如果使用Spark Streaming,虽然它是旧的api,但是对不同版本的kafka支持力度也不同,见下图。
http://spark.apache.org/docs/2.3.0/streaming-kafka-integration.html
hadoop版本
因为最终结果没落到hbase里,所有hadoop只提供了一个基础环境的作用(大概),但是又不能不装。。。安装见这一篇。这里提一下,虽然集群可能用的是CDH版,但是开发的时候用原版即可,不需要在开发环境再搭建CDH。如果涉及到hadoop不存在xxx的错误,可以用这个链接查看是否是版本问题。
http://hadoop.apache.org/docs/r2.6.0/api/org/apache/hadoop/
修改版本号,查看相关的组件是否存在,比如使用2.7的hadoop时。某个组件报错不存在,那么在http://hadoop.apache.org/docs/r2.7.0/api/org/apache/hadoop/中肯定找不到,但是如果能在http://hadoop.apache.org/docs/r2.6.0/api/org/apache/hadoop/能找到,说明是版本的问题,应该用2.6版本的hadoop。
spark版本
spark官网只提供最新版下载,历史版本可以在这里下,好像下载有限额,大概1天1个G。spark的版本问题有2个方面
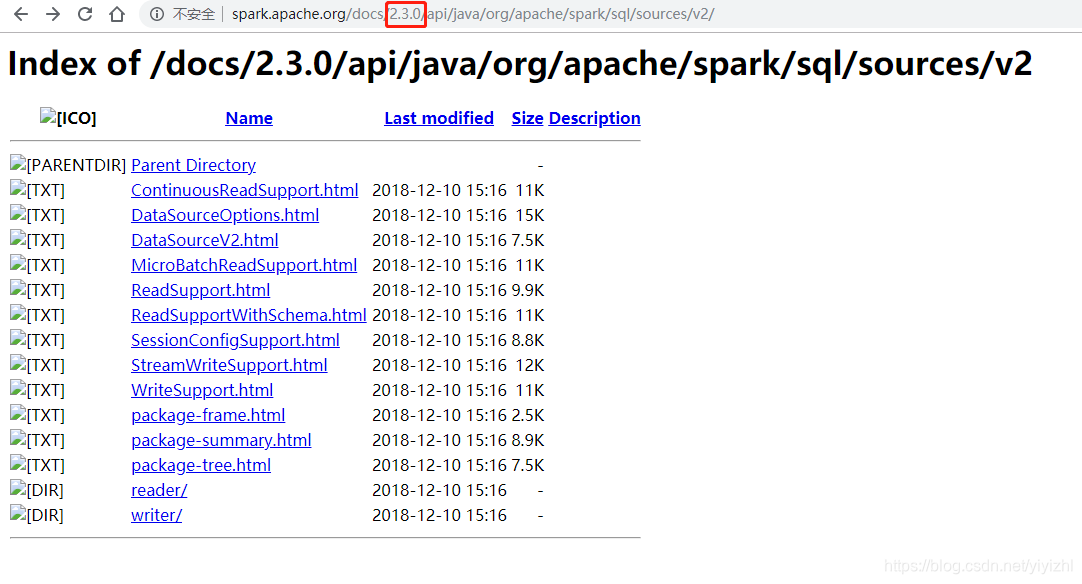
- 和hadoop一样,不同版本的spark有些组件不同,举个栗子,spark2.3里,有个叫v2的组件(org.apache.spark.sql.sources.v2),里面有reader和wirte类,当其他的包调用这个类的时候,如果此时用的是spark2.1,则会报错
`Exception in thread 'main' java.lang.NoClassDeffFoundError: org/apche/sql/source/v2/StreamWriteSupport`
这就是因为版本的组件缺失,更改spark版本即可。因此用这种方法,通过更改链接中的版本数字,可以快速的排查报错是否是因为spark版本问题。
http://spark.apache.org/docs/latest/api/

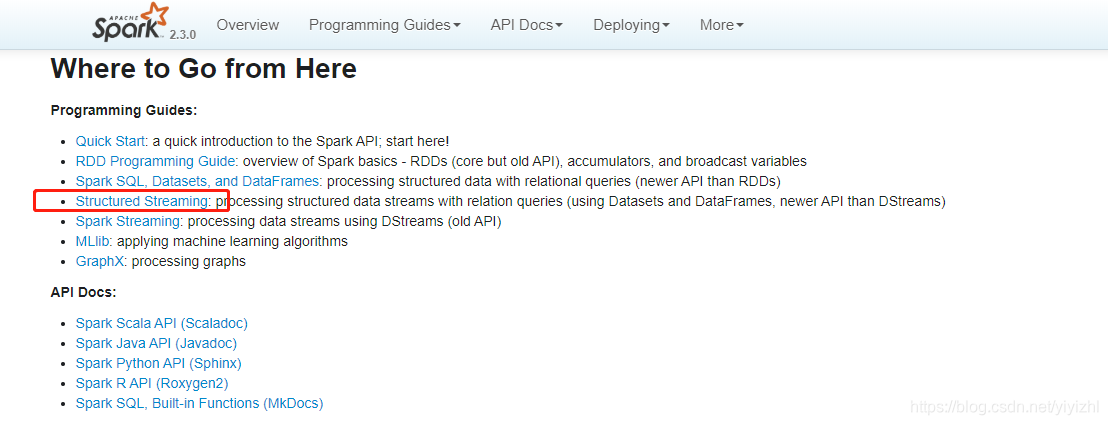
- 第二个方面就是新功能的api。其实和第一个方面本质是一样的,只不过还是值得拿出来说说。比如Structure Streaming是从spark2.3.0才能在文档首页看到的新API,因此只有高版本的spark才有,更进一步,比如数据流的Join操作,在spark2.3之前,只支持streamDatafram(流式数据框)和StaticDataframe(静态数据框)的join操作,之后的版本才支持streamDatafram之间的join操作。(实际上在spark2.1就已经有了alpha版本,但直到2.3才放到首页推荐,想来是在不断完善这些功能)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









