







背景
有A B两张表,其中A表为任务表,有executor执行人字段,一个任务可能由多个执行人执行,该字段通过逗号拼接。B表为子表,和A表的执行人相关联, 现在的问题是写一条sql语句 将A表中的executor字段替换成B表中的user_name字段,替换后的效果是
| 1 | 张三,李四,王五 |
|---|
原始表结构
OA_DemandTask表
| id | executor |
|---|---|
| 1 | 11,22,33 |
| 2 | 22,33 |
OA_HRM_Resource表
| id | user_name |
|---|---|
| 11 | 张三 |
| 22 | 李四 |
| 33 | 王五 |
给OA_DemandTask 起别名A, OA_HRM_Resource别名 B
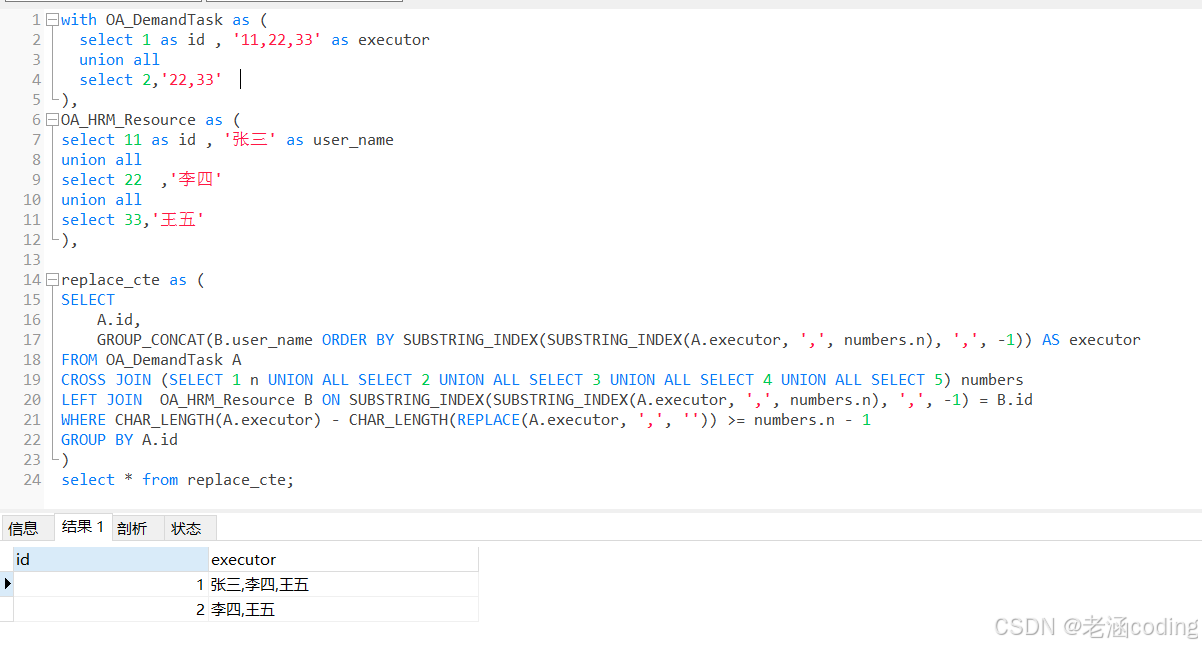
先上代码
SELECT
A.id,
GROUP_CONCAT(B.user_name ORDER BY SUBSTRING_INDEX(SUBSTRING_INDEX(A.executor, ',', numbers.n), ',', -1)) AS executor
FROM OA_DemandTask A
CROSS JOIN (SELECT 1 n UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) numbers
LEFT JOIN OA_HRM_Resource B ON SUBSTRING_INDEX(SUBSTRING_INDEX(A.executor, ',', numbers.n), ',', -1) = B.id
WHERE CHAR_LENGTH(A.executor) - CHAR_LENGTH(REPLACE(A.executor, ',', '')) >= numbers.n - 1
GROUP BY A.id
运行结果
前提知识点
这里需要先简单提一下sql中关键字的处理顺序,然后上面的那条sql有两个关键的函数,
substring_index、group_concat
-
sql的关键字处理顺序
网上参考其他博主博文:mysql关键字及执行顺序 -
substring_index以及group_concat介绍
1、substring_index 函数的语法是 substring_index(str, 拆分符号, n)
当n为正的时候 表示从左向右截取str, 截止的位置是 第n 个 拆分符号,如果n大于str中拆分符号的数量, 就返回原始字符串本身;
当n为负的时候 表示从右往左截取str, 和n为正数的情况恰好相反。
2、group_concat
作用是 将group by分组后的结果集 中的某个数据列 按照给定的拼接符,给定的分组字段的排序规则 进行拼接, 默认的拼接符号是逗号。
比如在经历join 等一系列操作之后,group by之后的部分结果集如下
| id | bid | user_name |
|---|---|---|
| 1 | 11 | 李四 |
| 1 | 22 | 王五 |
那么 group_concat(id order by id desc)得到的结果就是
| 1 | 李四,王五 |
|---|
当然也可以自定义排序规则
比如
group_concat( id order by case when user_name = '王五' then 1
when user_name = '李四' then 2
end
)
## 这里和默认的按照id排序就不同了,根据user_name自定义排序
原理
上面简单介绍了 substring_index和group_concat这两个函数,下面我们根据sql关键字的执行顺序来一步步处理结果,看看为什么最终能得到想要的结果集
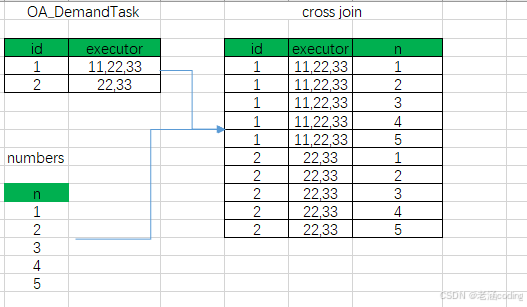
- from
由于这里是多张表进行join所以按照前后顺序 依次join,
第1 个是cross join,其实这个就是完全的笛卡尔积,
得到的结果就是
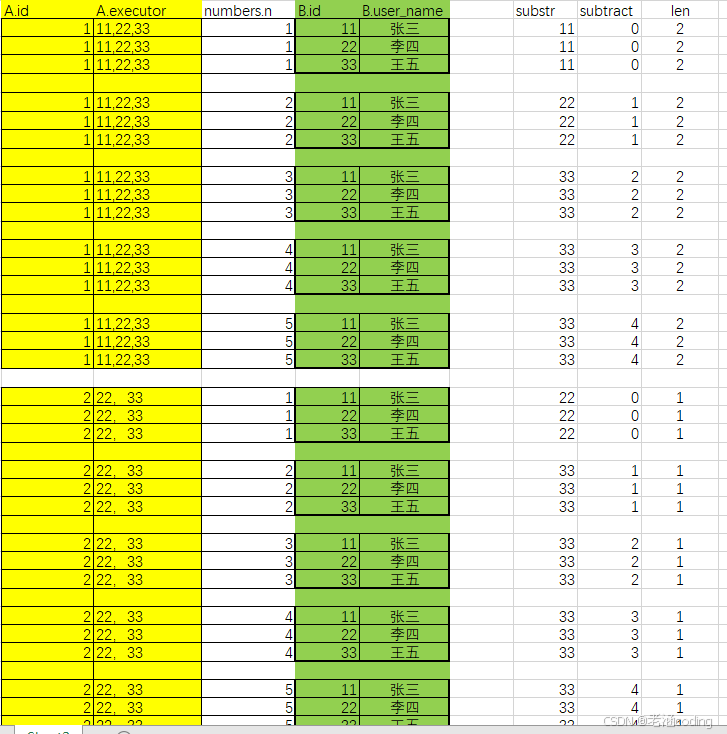
第二个join是left join
注意原始语句中在left join中有个on的过滤条件, 为了清晰的看到都做了哪些删选,我在上面的结果列中再增加几列
SUBSTRING_INDEX(SUBSTRING_INDEX(A.executor, ',', numbers.n), ',', -1) as substr
CHAR_LENGTH(A.executor) - CHAR_LENGTH(REPLACE(A.executor, ',', '')) as len
numbers.n-1 as substract
结果如下
至于为什么substr是这个样子,前面那个小结中有介绍substring_index的用法,我拿上面第一行来举例说明
首先内层的substring(A.executor,",",1), 从左至右数,从第0到executor字段的第1个逗号中间的字符串是 11
然后外层的substring(11,",", -1) 从右往左数 ,从右第0到 第1个逗号,由于没有逗号,所以取11本身
那么在on的过滤之后的结果集如下
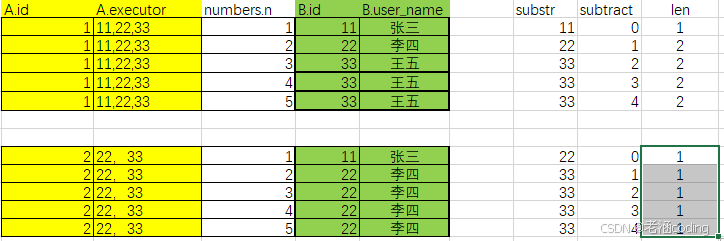
- where 过滤
然后where中是用substract去和len做比较, 大于等于的才返回
那么 过滤后的结果就是
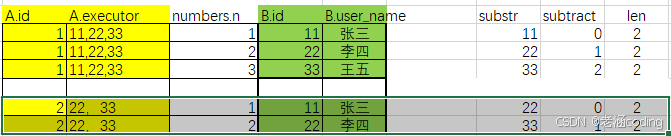
- group by
按照 A.id进行分组
参照上面那张截图 就好,我已经分好组了,上面的是A.id=1 下面的是A.id=2 - select
然后我们对分组结果集 执行group_concat(B.user_name)
那么就得到了
| 1 | 张三,李四,王五 |
|---|---|
| 2 | 张三,李四 |

















 241
241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









