







本文主要讲述flink1.15版本checkpoint状态恢复之KafkaSourceEnumState和KafkaPartitionSplit恢复流程,其中包括topic、partition值、当前读取的offset值。
一、从checkpoint恢复
1. flink run形式的
A job may be resumed from a checkpoint just as from a savepoint by using the checkpoint’s meta data file instead (see the savepoint restore guide). Note that if the meta data file is not self-contained, the jobmanager needs to have access to the data files it refers to (see Directory Structure above).
$ bin/flink run -s :checkpointMetaDataPath [:runArgs]
例如:
$ bin/flink run -s hdfs://xxx/user/xxx/river/82d8fe12464eae32abeaadd5a252b888/chk-1 [:runArgs]
2. 从代码中恢复
Configuration configuration = new Configuration();
configuration.setString("execution.savepoint.path", "file:///c/xxx/3626c0cf8135dda32878ffa95b328888/chk-1");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
二、源码流程
1、入口
flink消费kafka任务直接启动入口:
@Internal
@Override
public SplitEnumerator<KafkaPartitionSplit, KafkaSourceEnumState> createEnumerator(
SplitEnumeratorContext<KafkaPartitionSplit> enumContext) {
return new KafkaSourceEnumerator(
subscriber,
startingOffsetsInitializer,
stoppingOffsetsInitializer,
props,
enumContext,
boundedness);
}
flink消费kafka的checkpoint恢复入口:
@Internal
@Override
public SplitEnumerator<KafkaPartitionSplit, KafkaSourceEnumState> restoreEnumerator(
SplitEnumeratorContext<KafkaPartitionSplit> enumContext,
KafkaSourceEnumState checkpoint)
throws IOException {
return new KafkaSourceEnumerator(
subscriber,
startingOffsetsInitializer,
stoppingOffsetsInitializer,
props,
enumContext,
boundedness,
checkpoint.assignedPartitions());
}
2、内容
flink读取kafka checkpoint的operator状态包括两种:coordinatorState和operatorSubtaskStates状态:
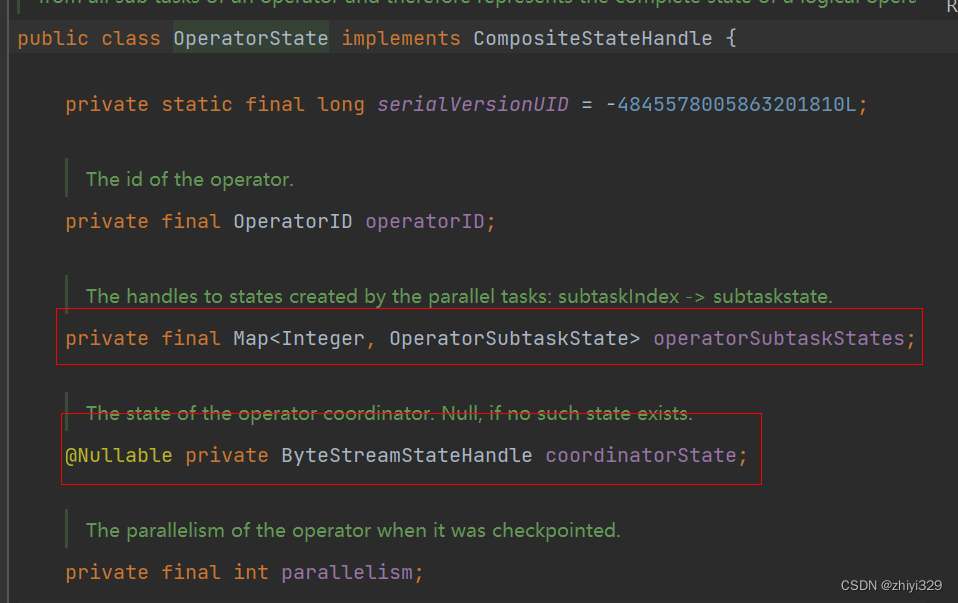
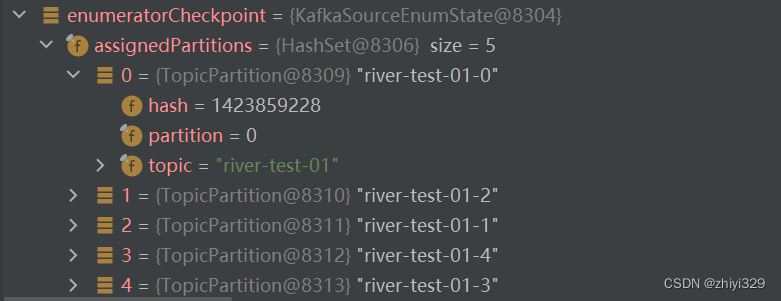
其中,coordinatorState保存了topic和以及当前任务分配的分区:
operatorSubtaskStates保存当前快照读取的offset值:
OperatorStateHandle{stateNameToPartitionOffsets={SourceReaderState=StateMetaInfo{offsets=[233, 280, 327, 374, 421], distributionMode=SPLIT_DISTRIBUTE}}, delegateStateHandle=ByteStreamStateHandle{handleName=‘file:/c/Users/liuguiru/test/checkpoint/f388506c01e786ab059809d65f8b5229/chk-16/6ac4a8e0-d50f-4115-91cb-bafd536b7226’, dataBytes=468}}
3、源码流程
主要讲解如何从checkpoint文件中读取checkpoint信息,然后解析成checkpoint数据KafkaSourceEnumState(即上面cp恢复入口处值)和KafkaPartitionSplit。
初始化JobMaster时,会创建DefaultScheduler实例,其调用父类SchedulerBase时,然后在createAndRestoreExecutionGraph中调用DefaultExecutionGraphFactory.createAndRestoreExecutionGraph -> tryRestoreExecutionGraphFromSavepoint -> CheckpointCoordinator.restoreSavepoint
public boolean restoreSavepoint(
SavepointRestoreSettings restoreSettings,
Map<JobVertexID, ExecutionJobVertex> tasks,
ClassLoader userClassLoader)
throws Exception {
final String savepointPointer = restoreSettings.getRestorePath();
final boolean allowNonRestored = restoreSettings.allowNonRestoredState();
Preconditions.checkNotNull(savepointPointer, "The savepoint path cannot be null.");
LOG.info(
"Starting job {} from savepoint {} ({})",
job,
savepointPointer,
(allowNonRestored ? "allowing non restored state" : ""));
final CompletedCheckpointStorageLocation checkpointLocation =
checkpointStorageView.resolveCheckpoint(savepointPointer);
// convert to checkpoint so the system can fall back to it
final CheckpointProperties checkpointProperties;
switch (restoreSettings.getRestoreMode()) {
case CLAIM:
checkpointProperties = this.checkpointProperties;
break;
case LEGACY:
checkpointProperties =
CheckpointProperties.forSavepoint(
false,
// we do not care about the format when restoring, the format is
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









