







状态的定义
状态在Flink中叫做State,用了保存中间计算结果或者缓存数据。
有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。下面的几个场景都需要使用流处理的状态功能:
- sum求和
对一个时间窗口内的数据进行聚合分析,分析一个小时内某项指标的75分位或99分位的数值。 - 去重
数据流中的数据有重复,想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入过的数据来判断去重。 - 模式检测
检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
一个状态更新和获取的流程如下图所示,一个算子子任务接收输入流,获取对应的状态,根据新的计算结果更新状态。一个简单的例子是对一个时间窗口内输入流的某个整数字段求和,那么当算子子任务接收到新元素时,会获取已经存储在状态中的数值,然后将当前输入加到状态上,并将状态数据更新。

状态的类型
按照数据结构的不同,Flink中定义了多种State,应用与不同的场景,具体如下:
1、ValueState
即类型为T的单值状态。可以使用 update(T) 进行更新,并通过 value() 获取状态值。
2、ListState
存储列表类型的状态。可以使用 add(T) 或 addAll(List) 添加元素;并通过 get() 获得整个列表。
3、MapState
维护 Map 类型的状态。通过put(K,V)或者putAll(Map<K,V>)来添加,使用get(K)来获取。
4、ReducingState
通过用户传入的 reduceFunction ,使用 add(T) 增加元素时,会调用reduceFunction,最后合并到一个单一的状态值。
5、AggregatingState
聚合状态,和4不同的是,这里聚合的类型可以是不同的元素类型,使用 add(IN) 添加元素,并使用AggregateFunction函数计算聚合结果。
6、FoldingState
和ReducingState类似,不过它的状态值类型可以和add方法中传入的元素类型不同。已被标识为废弃,不建议使用。
State按照是否有key划分为KeyedState和OperateorState两种,如下:
| 按是否有key划分 | 支持的state |
|---|---|
| KeyState | ValueState ListState ReducingState AggregationState MapState FoldingState |
| OperatorState | ListState |
状态的存储
Flink中无论是那种类型的State,都需要被持久化到可靠存储中,才具备应用级到容错能力,State的存储在Flink中叫做StateBackend。StateBackend需要具备如下两种能力。
- 在计算过程中提供访问State的能力,开发者在编写业务逻辑中能够使用
StateBackend的接口读写数据。 - 能够将State持久化到外部存储,提供容错能力。
根据使用场景不同,flink内置了3种StateBackend,如下:
- 纯内存:MemoryStateBackend,适用于验证、测试,不推荐生产环境。
- 内存+文件:FsStateBackend,适用于长周期大规模的数据。
- RocksDB:RocksDBStateBackend,适用于长周期大规模的数据。
上面提到的是面向用户的,那么flink内部3种State的关系如下:
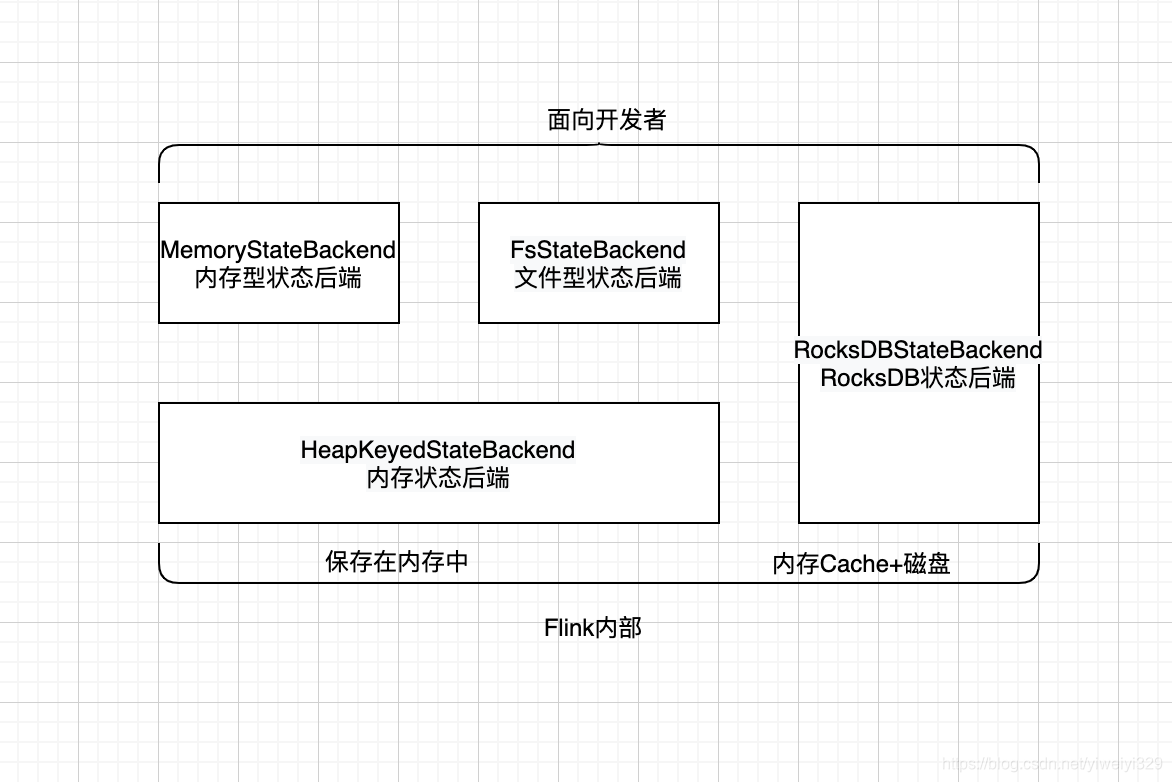
在运行时,MemoryStateBackend和FsStateBackend本地的State都保存在TaskMananger的内存中,所以其底层都依赖于HeapKeyedStateBackend。HeapKeyedStateBackend面向flink引擎内部,使用者无须感知。
内存型和文件型状态存储
内存型和文件型状态存储都依赖于内存保存运行时所需都state,区别在于状态保存的位置。
- 内存型StateBackend
内存型StateBackend在flink中叫作MemoryStateBackend,运行时所需要的State数据保存在TaskManager JVM堆上内存中,KV类型的State、窗口算子的State使用HashTable来保存数据、触发
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3666
3666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









