







1、响应时间一般要求
1)一般页面响应时间要求
响应时间<2s 快
响应时间<5s 能接受
响应时间>8s 慢
2)一般接口调用时间标准
响应时间<100ms 快
100ms<响应时间<300ms 能接受
响应时间>500ms 慢
2、监控分析思路
思考:出门发现钱包不在身上,疑是丢了,你该怎么办?
出门有没有带钱包-->没带,回家看是否在家-->没在家,回忆最后一次见钱包是什么时候
-->带了,回忆在哪些地方会拿出钱包,这一路是否碰到小偷-->不确定,
再原路返回查找
联想:我们做性能监控分析也基本这个思路,首先要知道系统架构,然后才能知道请求流经哪些环节,根据问题,针对性的监控分析相应指标。
下面以最简单的架构来说明影响性能的因素,如下图
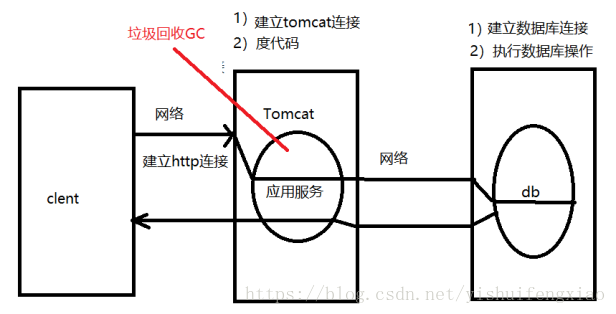
如上,影响性能的因素有:负载机性能、网络、硬件(cpu、内存、磁盘)、web容器连接池、业务逻辑代码、gc、db连接池、sql执行时间
附加,登录建立建立http连接伪代码:
uname = input(name)
pwd=input(pwd)
uid=select uid from user where name=uname and pswd=pwd;
if(uid = null){
system.out.print('用户名密码错误')
}else{
...
}
3、监控分析步骤
登陆响应时间长,监控哪些,怎么监控?
1)了解系统架构图并画出
2)根据系统架构图,画出被测接口的数据流图,并列出可能存在问题的每个点
3)
a:要么从简单的开始排查(负载机-网络-硬件)-(容器连接池、db连接池)-sql执行效率--gc--代码逻辑;
b:要么通过系统日志打印出接口及sql或者web容器排队时间(非必须),然后根据时间去判断可能存在问题的点,缩小问题的范围;
4、开发打印时间,问题分析举例
1)时间说明
* 工具测试响应时间:client发起请求到client接收请求
* 接口响应时间:进入接口程序到跳出接口程序所用时间(硬件、代码业务逻辑、GC)
* sql执行时间:即,网络、建立tomcat连接、GC 、db连接、执行sql所用时间
2)问题分析事例
* 工具rt=10,开发日志打印,接口=2s,db=1s,慢在哪?
--可能原因:负载机、网络、连接池
--主要问题:都有可能
* 工具rt=10,开发日志打印,接口=9s,db=1s,慢在哪?
--主要矛盾点在接口,可能出问题地方:硬件、代码业务逻辑、GC
--主要问题:可能服务器(排队)
* 工具rt=10,开发日志打印,接口=9s,db=8s,慢在哪?
--主要矛盾主要矛盾db,可能出问题的地方:网络、db服务器硬件、建立数据连接)、sql执行效率、web容器连接
--主要问题可能:sql执行效率
5、负载机问题举例
①银行协议某协议,只允许以进程方式运行,测试时单机最大并发是50,tps=500,此时负载机、服务器cpu、内存、io、tcp/ip连接数、网络都没任何问题,单机并发>50时,tps小于500,负载机、服务器cpu、内存、io、tcp/ip连接数、网络都没任何问题,服务器cpu使用率还下降了一点,分析是什么原因?
原因:16核cpu,1个cpu同一时间只能处理1个请求,理论上处理16个进程最合适,实际是50个时能达到最大,大于50个进程数量大,导致cpu上下文切换
②分布式三机器作为负载时,tps只能达到800,分析什么原因?
分布式有性能损耗,但也不至于只有800,查看服务器64核cpu,基本打满,此时是cpu满导致TPS上不去。
附,负载机问题排查方法:负载机排查方法,1个负载机,50并发,rt8秒,2个负载机,每个25并发,rt5s,这就是负载机问题,若rt没啥变化,则不是负载机问题
更多内容欢迎关注微信公众号查看


















 1797
1797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









