






简介
Redis布隆过滤器是一种概率型数据结构,对插入和查询操作非常高效。它能够计算“某样东西一定不存在或者可能存在”。其工作原理是,当向布隆过滤器添加元素(key)时,会使用多个hash函数对key进行hash,算出一个整数索引值,然后对位数据长度进行取模运算,得到一个位置为1。每个hash函数都会得到一个位置。判断key是否存在时,也会进行hash取模运算,判断数组这些位置是否都为1,只要有一个位为0,说明这个key不存在。
然而,布隆过滤器的缺点是返回的结果可能存在误判。即,可能误将不存在的元素判断为存在(这是由于hash的碰撞导致的)。但如果布隆过滤器判断某元素不存在,那么该元素就一定不存在。
相比于传统的List、Set、Map等数据结构,Redis布隆过滤器在插入和查询方面更高效,且占用空间更少。通过合理设置长度以及hash函数的个数,可以提高其准确率。
总的来说,Redis布隆过滤器是一种在Redis中实现的概率型数据结构,用于高效地处理插入和查询操作,但需要注意其可能存在的误判情况。
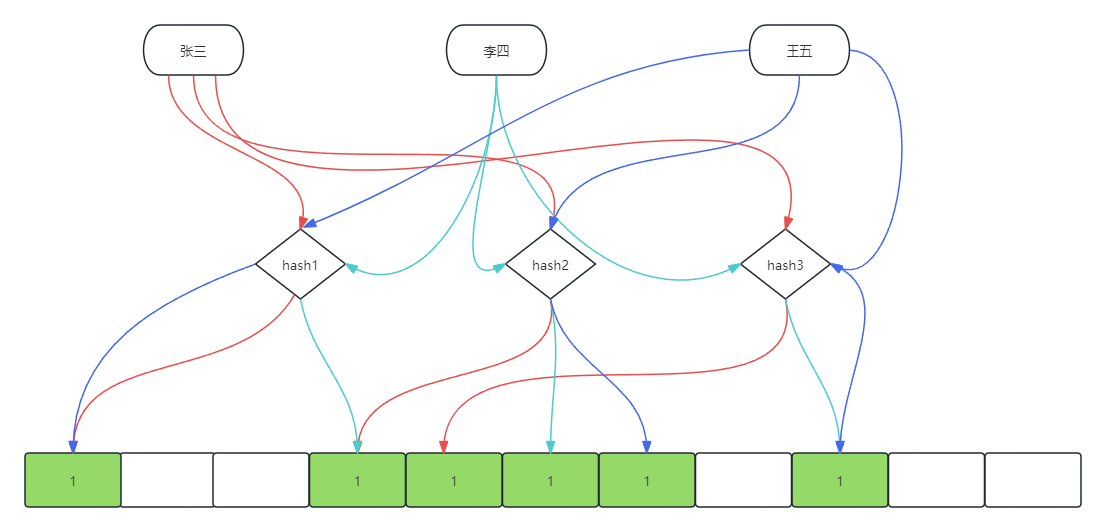
所以,布隆过滤器存在误判的可能性。当存入王麻子的时候,通过hash1、hash2、hash3计算后发现和其他元素都冲突,那么就会误判元素存在,实际是不存在
 想要降低这种误判的概率,主要的办法就是降低哈希冲突的概率及引入更多的哈希算法
想要降低这种误判的概率,主要的办法就是降低哈希冲突的概率及引入更多的哈希算法
应用场景
布隆过滤器具有广泛的应用场景,特别是在处理大数据和高并发场景时表现出色。以下是一些布隆过滤器的常见应用场景:
- 缓解缓存穿透:在缓存系统中,当查询一个不存在的数据时,缓存系统不会命中,导致请求直接打到数据库上,造成数据库压力增大。使用布隆过滤器可以预先判断数据是否存在于缓存中,从而避免不必要的数据库查询。
- 垃圾邮件过滤:在处理大量的电子邮件时,布隆过滤器可以用来判断某封邮件是否可能是垃圾邮件。通过预先训练好的布隆过滤器,可以快速过滤掉大部分垃圾邮件,减轻后续处理系统的负担。
- 网页爬虫去重:在爬虫系统中,布隆过滤器可以用来判断某个网页是否已经被爬取过,避免重复爬取相同的网页。
- 数据库查询优化:在数据库查询中,可以利用布隆过滤器快速判断某个值是否存在于某个字段中,从而优化查询性能。
- 集合重复元素的判断:在处理大量数据时,布隆过滤器可以用来判断一个元素是否已经存在于某个集合中,避免重复添加。
需要注意的是,由于布隆过滤器存在一定的误报率,因此在某些对准确性要求极高的场景中可能不适用。此外,布隆过滤器不支持删除操作,这是因为删除一个数据需要将其对应的所有位置的值都设为0,但这样可能会影响到其他数据的判断。如果需要删除元素,可能需要考虑其他数据结构或方法。
总的来说,布隆过滤器在处理大数据和高并发场景时具有高效、节省空间的优势,适用于各种需要快速判断元素是否存在的场景。
工作过程
- 初始化位数组:首先,开辟一个长度为m的位数组(或称为二进制向量)。这个位数组在初始化时,每个位置的值都设为0。这个位数组的大小会直接影响布隆过滤器的误判率和空间效率。
- 选择哈希函数:获取几个哈希函数。这些哈希函数能够将输入数据映射到位数组中的特定位置。在实际应用中,已经有很多运行良好的哈希函数可供选择,如BKDRHash,JSHash,RSHash等。
- 插入数据:对于需要插入到布隆过滤器的每一个数据,使用选定的哈希函数进行计算,得到多个哈希值。这些哈希值对应到位数组中的不同位置,然后将这些位置的值设为1。这样,对于每一个插入的数据,都会在位数组中留下其存在的痕迹。
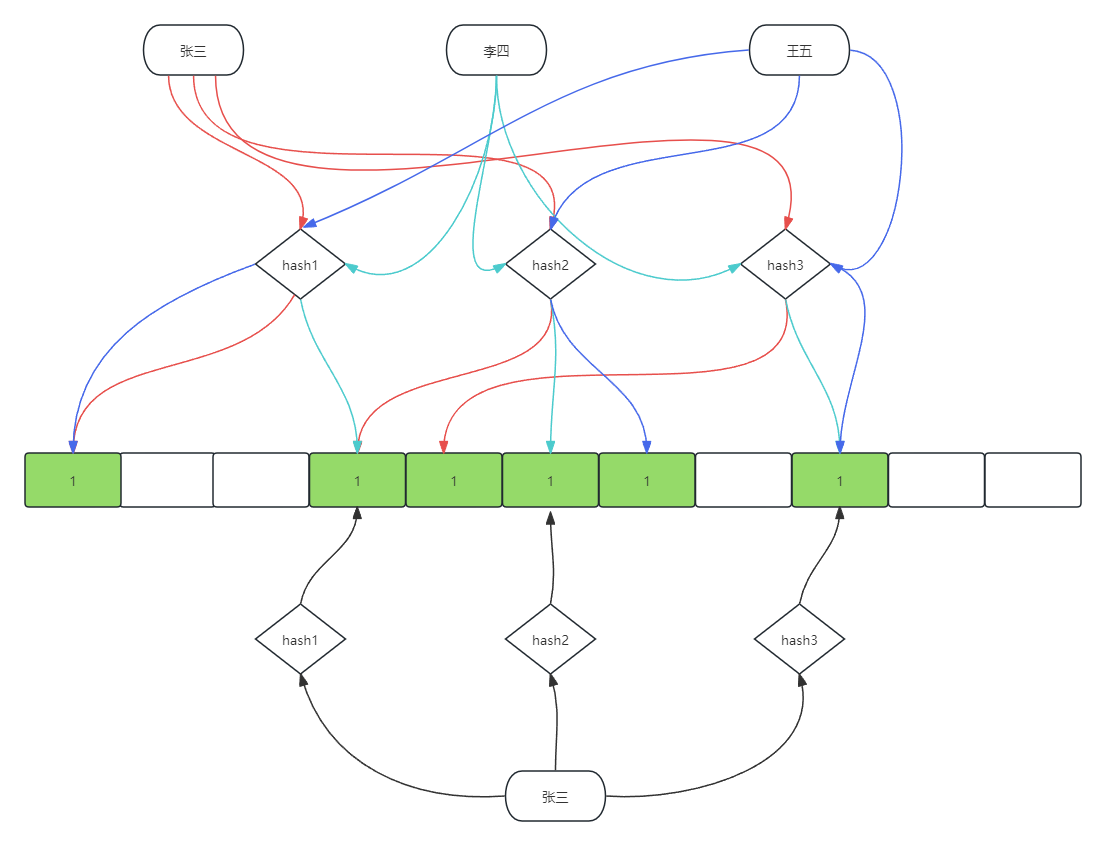
- 查询数据:当需要查询某个数据是否存在于布隆过滤器中时,再次使用相同的哈希函数进行计算,得到多个哈希值。然后检查位数组中这些哈希值对应的位置是否都为1。如果所有位置的值都为1,那么认为该数据可能存在于布隆过滤器中;如果有任何一个位置的值不为1,那么可以确定该数据一定不存在于布隆过滤器中。
如何使用
Java可以通过Guava、Redisson等方式实现
Guava:
import com.aliyun.openservices.shade.com.google.common.hash.BloomFilter;
import com.aliyun.openservices.shade.com.google.common.hash.Funnels;
import com.google.common.base.Charsets;
public class BloomTest {
public static void main(String[] args) {
// 创建布隆过滤器,预计插入10个元素,误判率为0.01
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), 10, 0.01);
// 插入元素
bloomFilter.put("张三");
bloomFilter.put("李四");
bloomFilter.put("王五");
// 判断元素是否存在
System.out.println(bloomFilter.mightContain("王麻子")); // false
System.out.println(bloomFilter.mightContain("张三")); // true
}
}Redisson:
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class BloomTest {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("myfilter");
bloomFilter.tryInit(10, 0.01);
bloomFilter.add("张三");
bloomFilter.add("李四");
bloomFilter.add("王五");
System.out.println(bloomFilter.contains("王麻子"));//false
System.out.println(bloomFilter.contains("张三"));//true
redisson.shutdown();
}
}
布隆过滤器误报率过高如何处理
- 调整布隆过滤器参数:
- 增加位数组大小:位数组越大,误报率越低。因此,可以考虑增加位数组的大小来降低误报率。但请注意,这也会增加空间成本。
- 调整哈希函数数量:使用更多的哈希函数可以增加位数组中每个元素被标记的位数,从而降低误报率。但过多的哈希函数也会增加计算复杂度和时间成本。
- 建立白名单:
- 对于已知的不在集合中的元素,可以将其加入白名单。当查询这些元素时,可以直接从白名单中判断其不存在,避免布隆过滤器的误报。
- 使用计数布隆过滤器:
- 传统的布隆过滤器只能表示元素是否存在,而计数布隆过滤器使用计数器来记录每个位置的命中次数。这可以在一定程度上降低误报率,但也会增加空间复杂度和更新操作的复杂性。
- 多层布隆过滤器:
- 使用多个布隆过滤器串联起来,每个过滤器具有不同的误报率。当一个元素连续通过多个过滤器时,可以认为其存在的概率更高,从而降低误报率。但这种方法会增加查询的复杂性和时间成本。
- 使用其他数据结构:
- 如果误报率对应用的影响非常大,且对空间和时间成本的要求较高,可以考虑使用其他数据结构,如哈希表或红黑树等,它们具有较低的误报率,但空间和时间成本可能更高。


















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











