







这里写目录标题
1.Zookeeper简介
zookeeper官网:https://zookeeper.apache.org/
- Zookeeper 是 Apache Hadoop 项目下的一个子项目,是一个树形目录服务。
- Zookeeper 翻译过来就是 动物园管理员,他是用来管 Hadoop(大象)、Hive(蜜蜂)、Pig(小 猪)的管理员。简称zk
- Zookeeper 是一个分布式的、开源的分布式应用程序的协调服务。
- Zookeeper 提供的主要功能包括:
– 配置管理
– 分布式锁
– 集群管理
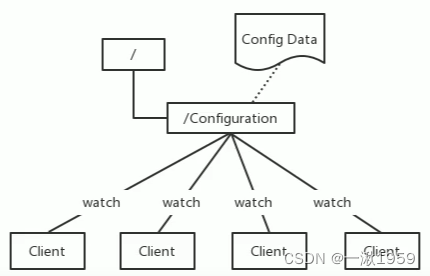
1.1 配置管理
管理一些配置来实现服务治理
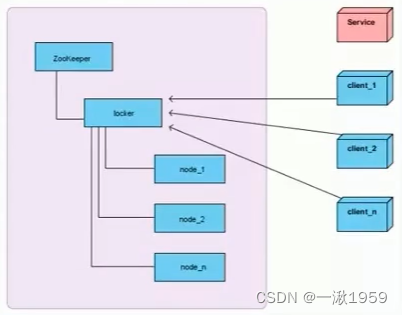
1.2 分布式锁服务
分布式多进程之前,需用有一个第三方锁(中间件等)来保证资源抢占问题
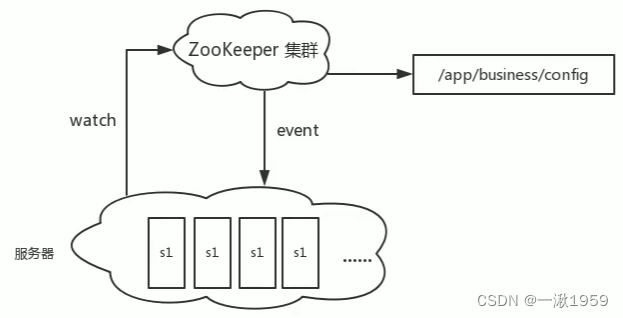
1.3 集群管理
一个集群有时会因为各种软硬件故障或者网络故障,出现某些服务挂掉而被移除集群,而某些服务器加入到集群中的情况,zookeeper会将这些服务加入/移出的情况通知给集群中的其他正常工作的服务器,以及时调整存储和计算等任务的分配和执行等。此外zookeeper还会对故宣的服务器做出诊断并尝试修复
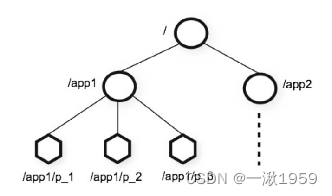
2.zookeeper的数据模型
- ZooKeeper 是一个树形目录服务,其数据模型和Unix的文件系统目录树很类似,拥有一个层次化结构。
- 这里面的每一个节点都被称为: ZNode,每个节点上都会保存自己的数据和节点信息。
- 节点可以拥有子节点,同时也允许少量(1MB)数据存储在该节点之下。
- 节点可以分为四大类:
– PERSISTENT 持久化节点 (默认)
– EPHEMERAL 临时节点(随会话结束) :-e
– PERSISTENT_SEQUENTIAL 持久化顺序节点 :-s
– EPHEMERAL_SEQUENTIAL 临时顺序节点 :-es
ZooKeeper的临时节点不允许拥有子节点。
znode,兼具文件和目录两种特点。既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分。
2.1 节点状态stat的属性
[zk: localhost:2181(CONNECTED) 9] ls -s /shangshangqian/app1
[da]
cZxid = 0x46
ctime = Tue Jul 05 22:23:34 CST 2022
mZxid = 0x4c
mtime = Tue Jul 05 22:24:28 CST 2022
pZxid = 0x49
cversion = 1
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 1
cZxid:数据节点创建时的事务ID
ctime:数据节点创建时的时间
mZxid:数据节点最后一次更新时的事务ID
mtime:数据节点最后一次更新时的时间
pZxid:数据节点的子节点最后一次被修改的事务ID
cversion:子节点的更改次数
dataVersion:节点数据的更改次数
aclVersion:节点的ACL的更改次数
ephemer alowner:如果节点是临时节点,则表示创建该节点的会话的SessionID;如果节点是持久节点,则该属性为0
dataLength:数据内容的长度
numChildren:数据节点当前的子节点个数
3.基础命令
3.1 服务端
启动 ZooKeeper 服务: ./zkServer.sh start
查看 ZooKeeper 服务状态: ./zkServer.sh status
停止 ZooKeeper 服务: ./zkServer.sh stop
重启 ZooKeeper 服务: ./zkServer.sh restart
3.2 客户端
连接ZooKeeper服务端: ./zkCli.sh –server ip:port
断开连接: quit
查看命令帮助::help
显示指定目录下节点: ls 目录
查询节点详细信息:ls –s /节点path
创建节点: create /节点path value
获取节点值: get /节点path
设置节点值: set /节点path value
基于版本设置节点值: set /节点path value version
删除单个节点:delete /节点path
基于版本删除单个节点:delete /节点path version
删除带有子节点的节点: deleteall /节点path
创建临时节点: create -e /节点path value
创建顺序节点: create -s /节点path value
4.curator
curator是Netflix公司开源的一个zookeeper客户端,后捐献给apache,curator框架在zookeeper原生API接口上进行了包装,解决了很多zooKeeper客户端非常底层的细节开发。提供zooKeeper各种应用场景(比如:分布式锁服务、集群领导选举、共享计数器、缓存机制、分布式队列等)的抽象封装,实现了Fluent风格的API接口,是最好用,最流行的zookeeper的客户端。
原生zookeeperAPI的不足:
连接对象异步创建,需要开发人员自行编码等待
连接没有自动重连超时机制
watcher一次注册生效一次
不支持递归创建树形节点
curator特点:
解决session会话超时重连
watcher反复注册
简化开发api
遵循Fluent风格的API
提供了分布式锁服务、共享计数器、缓存机制等机制
4.1 maven依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
<!--curator-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>
<!--日志-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.21</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别靠左显示5个字符宽度,%logger:日志的类名,%msg:日志消息,%n是换行符 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} --- %msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="STDOUT" />
</root>
</configuration>
4.2 CRUD安排上
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.api.BackgroundCallback;
import org.apache.curator.framework.api.CuratorEvent;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.data.Stat;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.util.List;
public class CuratorTest {
private CuratorFramework client;
/**
* 建立连接
*/
@Before
public void testConnect() {
/*
*
* @param connectString 连接字符串。zk server 地址和端口 "192.168.149.135:2181,192.168.149.136:2181"
* @param sessionTimeoutMs 会话超时时间 单位ms
* @param connectionTimeoutMs 连接超时时间 单位ms
* @param retryPolicy 重试策略
* @param namespace 本次会话的最前缀地址 /shangshangqian
*/
/* //重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000,10);
//1.第一种方式
CuratorFramework client = CuratorFrameworkFactory.newClient("192.168.149.135:2181",
60 * 1000, 15 * 1000, retryPolicy);*/
//重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
//2.第二种方式
//CuratorFrameworkFactory.builder();
client = CuratorFrameworkFactory.builder()
.connectString("120.77.39.136:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.namespace("shangshangqian")
.build();
//开启连接
client.start();
}
//==============================create=============================================================================
/**
* 创建节点:create 持久 临时 顺序 数据
* 1. 基本创建 :create().forPath("")
* 2. 创建节点 带有数据:create().forPath("",data)
* 3. 设置节点的类型:create().withMode().forPath("",data)
* 4. 创建多级节点 /app1/p1 :create().creatingParentsIfNeeded().forPath("",data)
*/
@Test
public void testCreate() throws Exception {
//2. 创建节点 带有数据
//如果创建节点,没有指定数据,则默认将当前客户端的ip作为数据存储
String path = client.create().forPath("/app2", "hehe".getBytes());
System.out.println(path);
}
@Test
public void testCreate2() throws Exception {
//1. 基本创建
//如果创建节点,没有指定数据,则默认将当前客户端的ip作为数据存储
String path = client.create().forPath("/app1");
System.out.println(path);
}
@Test
public void testCreate3() throws Exception {
//3. 设置节点的类型
//默认类型:持久化
String path = client.create().withMode(CreateMode.EPHEMERAL).forPath("/app3");
System.out.println(path);
}
@Test
public void testCreate4() throws Exception {
//4. 创建多级节点 /app1/p1
//creatingParentsIfNeeded():如果父节点不存在,则创建父节点
String path = client.create().creatingParentsIfNeeded().forPath("/app4/p1");
System.out.println(path);
}
//===========================get================================================================================
/**
* 查询节点:
* 1. 查询数据:get: getData().forPath()
* 2. 查询子节点: ls: getChildren().forPath()
* 3. 查询节点状态信息:ls -s:getData().storingStatIn(状态对象).forPath()
*/
@Test
public void testGet1() throws Exception {
//1. 查询数据:get
byte[] data = client.getData().forPath("/app1");
System.out.println(new String(data));
}
@Test
public void testGet2() throws Exception {
// 2. 查询子节点: ls
List<String> path = client.getChildren().forPath("/");
System.out.println(path);
}
@Test
public void testGet3() throws Exception {
Stat status = new Stat();
System.out.println(status);
//3. 查询节点状态信息:ls -s
client.getData().storingStatIn(status).forPath("/app1");
System.out.println(status);
}
//===========================set================================================================================
/**
* 修改数据
* 1. 基本修改数据:setData().forPath()
* 2. 根据版本修改: setData().withVersion().forPath()
* * version 是通过查询出来的。目的就是为了让其他客户端或者线程不干扰我。
*
* @throws Exception
*/
@Test
public void testSet() throws Exception {
client.setData().forPath("/app1", "itcast".getBytes());
}
@Test
public void testSetForVersion() throws Exception {
Stat status = new Stat();
//3. 查询节点状态信息:ls -s
client.getData().storingStatIn(status).forPath("/app1");
int version = status.getVersion();//查询出来的 3
System.out.println(version);
client.setData().withVersion(version).forPath("/app1", "hehe".getBytes());
}
//===========================delete================================================================================
/**
* 删除节点: delete deleteall
* 1. 删除单个节点:delete().forPath("/app1");
* 2. 删除带有子节点的节点:delete().deletingChildrenIfNeeded().forPath("/app1");
* 3. 必须成功的删除:为了防止网络抖动。本质就是重试。 client.delete().guaranteed().forPath("/app2");
* 4. 回调:inBackground
* @throws Exception
*/
@Test
public void testDelete() throws Exception {
// 1. 删除单个节点
client.delete().forPath("/app1");
}
@Test
public void testDelete2() throws Exception {
//2. 删除带有子节点的节点
client.delete().deletingChildrenIfNeeded().forPath("/app4");
}
@Test
public void testDelete3() throws Exception {
//3. 必须成功的删除
client.delete().guaranteed().forPath("/app2");
}
@Test
public void testDelete4() throws Exception {
//4. 回调
client.delete().guaranteed().inBackground(new BackgroundCallback(){
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("我被删除了~");
System.out.println(event);
}
}).forPath("/app1");
}
@After
public void close() {
if (client != null) {
client.close();
}
}
}
4.3 Watcher
Curator的Watcher封装主要分三种:
- NodeCache:给指定一个节点注册监听器
- PathChildrenCache:监听某个节点的所有子节点们
- TreeCache:监听某个节点自己和所有子节点们
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.api.BackgroundCallback;
import org.apache.curator.framework.api.CuratorEvent;
import org.apache.curator.framework.recipes.cache.*;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.data.Stat;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.util.List;
public class CuratorWatcherTest {
private CuratorFramework client;
/**
* 建立连接
*/
@Before
public void testConnect() {
/*
*
* @param connectString 连接字符串。zk server 地址和端口 "192.168.149.135:2181,192.168.149.136:2181"
* @param sessionTimeoutMs 会话超时时间 单位ms
* @param connectionTimeoutMs 连接超时时间 单位ms
* @param retryPolicy 重试策略
*/
/* //重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000,10);
//1.第一种方式
CuratorFramework client = CuratorFrameworkFactory.newClient("192.168.149.135:2181",
60 * 1000, 15 * 1000, retryPolicy);*/
//重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
//2.第二种方式
//CuratorFrameworkFactory.builder();
client = CuratorFrameworkFactory.builder()
.connectString("120.77.39.136:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.namespace("shangshangqian")
.build();
//开启连接
client.start();
}
@After
public void close() {
if (client != null) {
client.close();
}
}
/**
* 演示 NodeCache:给指定一个节点注册监听器
*/
@Test
public void testNodeCache() throws Exception {
//1. 创建NodeCache对象
final NodeCache nodeCache = new NodeCache(client,"/app1");
//2. 注册监听
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("节点变化了~");
//获取修改节点后的数据
byte[] data = nodeCache.getCurrentData().getData();
System.out.println(new String(data));
}
});
//3. 开启监听.如果设置为true,则开启监听是,加载缓冲数据
nodeCache.start(true);
while (true){
}
}
/**
* 演示 PathChildrenCache:监听某个节点的所有子节点们
*/
@Test
public void testPathChildrenCache() throws Exception {
//1.创建监听对象
PathChildrenCache pathChildrenCache = new PathChildrenCache(client,"/app2",true);
//2. 绑定监听器
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
System.out.println("子节点变化了~");
System.out.println(event);
//监听子节点的数据变更,并且拿到变更后的数据
//1.获取类型
PathChildrenCacheEvent.Type type = event.getType();
//2.判断类型是否是update
if(type.equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)){
System.out.println("数据变了!!!");
byte[] data = event.getData().getData();
System.out.println(new String(data));
}
}
});
//3. 开启
pathChildrenCache.start();
while (true){
}
}
/**
* 演示 TreeCache:监听某个节点自己和所有子节点们
*/
@Test
public void testTreeCache() throws Exception {
//1. 创建监听器
TreeCache treeCache = new TreeCache(client,"/app2");
//2. 注册监听
treeCache.getListenable().addListener(new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {
System.out.println("节点变化了");
System.out.println(event);
}
});
//3. 开启
treeCache.start();
while (true){
}
}
}
5.应用案例
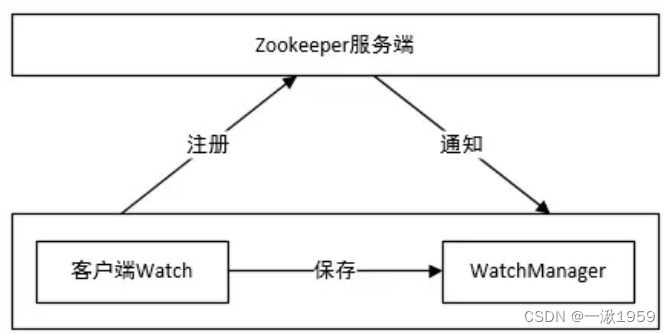
Watcher
Watcher实现由三个部分组成:
- Zookeeper服务端
- Zookeeper客户端
- 客户端的ZKWatchManager对象
客户端首先将Watcher注册到服务端,同时将Watcher对象保存到客户端的Watch管理器中。当ZooKeeper服务端监听的数据状态发生变化时,服务端会主动通知客户端,接着客户端的Watch管理器会触发相关Watcher来回调相应处理逻辑,从而完成整体的数据发布/订阅流程。
- Watcher通知状态(KeeperState)
KeeperState是客户端与服务端连接状态发生变化时对应的通知类型。路径为org.apache.zookeeper.Watcher.Event.KeeperState,是一个枚举类,其枚举属性如下:
| 枚举属性 | 说明 |
|---|---|
| centered SyncConnected | 客户端与服务器正常连接时 |
| Disconnected | 客户端与服务器断开连接时 |
| Expired | 会话session失效时 |
| AuthFailed | 身份认证失败时 |
- Watcher事件类型(EventType)
EventType是数据节点(znode)发生变化时对应的通知类型。EventType变化时KeeperState永远处于SyncConnected通知状态下;当KeeperState发生变化时,EventType永远为None。其路径org.apache.zookeeper.Watcher.Event.EventType,是一个枚举类,枚举属性如下:
| 枚举属性 | 说明 |
|---|---|
| None | 无 |
| NodeCreated | Watcher监听的数据节点被创建时 |
| NodeDeleted | Watcher监听的数据节点被删除时 |
| NodeDataChanged | Watcher监听的数据节点内容发生变更时(无论内容数据是否变化) |
| NodeChildrenChanged | Watcher监听的数据节点的子节点列表发生变更时 |
注:客户端接收到的相关事件通知中只包含状态及类型等信息,不包括节点变化前后的具体内容,变化前的数据需业务自身存储,变化后的数据需调用get等方法重新获取;
watcher 有三种方式,调用客户端 API 可以分别通过 getData、exists、getChildren 实现
| 注册方式 | Created | ChildrenChanged | Changed | Deleted |
|---|---|---|---|---|
| zk.exists(“/node-x”,watcher) | 可监控 | 可监控 | 可监控 | |
| zk.getData(“/node-x”,watcher) | 可监控 | 可监控 | ||
| zk.getChildren(“/node-x”,watcher) | 可监控 | 可监控 |
注:基础watcher的使用方式可以分两种:使用连接对象中的watcher 和 自定义watcher对象 ,以exists为例
@Test
public void watcherExists1() throws KeeperException, InterruptedException {
// arg1:节点的路径
// arg2:使用连接对象中的watcher
zooKeeper.exists("/watcher1", true);
Thread.sleep(50000);
System.out.println("结束");
}
@Test
public void watcherExists2() throws KeeperException, InterruptedException {
// arg1:节点的路径
// arg2:自定义watcher对象
zooKeeper.exists("/watcher1", new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("自定义watcher");
System.out.println("path=" + event.getPath());
System.out.println("eventType=" + event.getType());
}
});
Thread.sleep(50000);
System.out.println("结束");
}
5.1 配置中心案例
工作中有这样的一个场景: 数据库用户名和密码信息放在一个配置文件中,应用读取该配置文件,配置文件信息放入缓存。
若数据库的用户名和密码改变时候,还需要重新加载缓存,比较麻烦,通过ZooKeeper可以轻松完成,当数据库发生变化时自动完成缓存同步。
设计思路:
- 连接zookeeper服务器
- 读取zookeeper中的配置信息,注册watcher监听器,存入本地变量
- 当zookeeper中的配置信息发生变化时,通过watcher的回调方法捕获数据变化事件
- 重新获取配置信息
import java.util.concurrent.CountDownLatch;
import com.itcast.watcher.ZKConnectionWatcher;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.EventType;
import org.apache.zookeeper.ZooKeeper;
public class MyConfigCenter implements Watcher {
// zk的连接串
private String IP = "192.168.188.133:2181";
// 计数器对象
private CountDownLatch countDownLatch = new CountDownLatch(1);
// 连接对象
private static ZooKeeper zooKeeper;
// 用于本地化存储配置信息
private String url;
private String username;
private String password;
@Override
public void process(WatchedEvent event) {
try {
// 捕获事件状态
if (event.getType() == EventType.None) {
if (event.getState() == Event.KeeperState.SyncConnected) {
System.out.println("连接成功");
countDownLatch.countDown();
} else if (event.getState() == Event.KeeperState.Disconnected) {
System.out.println("连接断开!");
} else if (event.getState() == Event.KeeperState.Expired) {
System.out.println("连接超时!");
// 超时后服务器端已经将连接释放,需要重新连接服务器端
zooKeeper = new ZooKeeper(IP, 6000,
new MyConfigCenter());
} else if (event.getState() == Event.KeeperState.AuthFailed) {
System.out.println("验证失败!");
}
// 当配置信息发生变化时
} else if (event.getType() == EventType.NodeDataChanged) {
initValue();
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
// 构造方法
private MyConfigCenter() {
try {
// 创建连接对象
zooKeeper = new ZooKeeper(IP, 5000, this);
// 阻塞线程,等待连接的创建成功
countDownLatch.await();
initValue();
}catch (Exception e){
e.printStackTrace();
}
}
// 连接zookeeper服务器,读取配置信息
private void initValue() {
try {
// 读取配置信息
this.url = new String(zooKeeper.getData("/config/url", true, null));
this.username = new String(zooKeeper.getData("/config/username", true, null));
this.password = new String(zooKeeper.getData("/config/password", true, null));
} catch (Exception ex) {
ex.printStackTrace();
}
}
public static void main(String[] args) {
try {
MyConfigCenter myConfigCenter = new MyConfigCenter();
for (int i = 1; i <= 20; i++) {
Thread.sleep(5000);
System.out.println("url:"+myConfigCenter.getUrl());
System.out.println("username:"+myConfigCenter.getUsername());
System.out.println("password:"+myConfigCenter.getPassword());
System.out.println("########################################");
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
5.2 生成分布式唯一ID
在过去的单库单表型系统中,通常可以使用数据库字段自带的auto_increment属性来自动为每条记录生成一个唯一的ID。但是分库分表后,就无法在依靠数据库的auto_increment属性来唯一标识一条记录了。此时我们就可以用zookeeper在分布式环境下生成全局唯一ID。
设计思路:
- 连接zookeeper服务器
- 指定路径生成临时有序节点
- 取序列号及为分布式环境下的唯一ID
子节点的顺序自增是根据父节点的version决定
package com.chinaentropy.website.common.utils;
/**
* @author Suqi
* @version 1.0
* @date 2022/7/6 15:36
* @desc 生成分布式唯一ID
*/
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
import java.util.concurrent.CountDownLatch;
public class GloballyUniqueId implements Watcher {
// zk的连接串
private String IP = "ip:2181";
// 计数器对象
private CountDownLatch countDownLatch = new CountDownLatch(1);
// 用户生成序号的节点
private String defaultPath = "/uniqueId";
// 连接对象
private ZooKeeper zooKeeper;
@Override
public void process(WatchedEvent event) {
try {
// 捕获事件状态
if (event.getType() == Event.EventType.None) {
if (event.getState() == KeeperState.SyncConnected) {
System.out.println("连接成功");
countDownLatch.countDown();
} else if (event.getState() == KeeperState.Disconnected) {
System.out.println("连接断开!");
} else if (event.getState() == KeeperState.Expired) {
System.out.println("连接超时!");
// 超时后服务器端已经将连接释放,需要重新连接服务器端
zooKeeper = new ZooKeeper(IP, 6000,
new GloballyUniqueId());
} else if (event.getState() == KeeperState.AuthFailed) {
System.out.println("验证失败!");
}
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
// 构造方法
private GloballyUniqueId() {
try {
//打开连接
zooKeeper = new ZooKeeper(IP, 5000, this);
// 阻塞线程,等待连接的创建成功
countDownLatch.await();
} catch (Exception ex) {
ex.printStackTrace();
}
}
// 生成id的方法
private String getUniqueId() {
String path = "";
try {
//创建临时有序节点
path = zooKeeper.create(defaultPath, new byte[0], Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
} catch (Exception ex) {
ex.printStackTrace();
}
// /uniqueId0000000001
return path.substring(9);
}
public static void main(String[] args) {
GloballyUniqueId globallyUniqueId = new GloballyUniqueId();
for (int i = 1; i <= 5; i++) {
String id = globallyUniqueId.getUniqueId();
System.out.println(id);
}
}
}
5.3 分布式锁
分布式锁有多种实现方式,比如通过数据库、redis都可实现。作为分布式协同工具ZooKeeper,当然也有着标准的实现方式。下面介绍在zookeeper中如何实现排他锁。
设计思路:
- 每个客户端往/Locks下创建临时有序节点/Locks/Lock_000000001
- 客户端取得/Locks下子节点,并进行排序,判断排在最前面的是否为自己,如果自己的锁节点在第一位,代表获取锁成功
- 如果自己的锁节点不在第一位,则监听自己前一位的锁节点。例如,自己锁节点Lock_000000001
- 当前一位锁节点(Lock_000000002)的逻辑
- 监听客户端重新执行第2步逻辑,判断自己是否获得了锁
本demo是源码封装的缩写,实际开发都会用Curator直接方便使用
可以看到逻辑比较清晰,N个线程同时在path下创建临时顺序节点,编号最小的获取锁,没抢到锁的会调用wait()方法等待被监听器唤醒,监听器wacher里,该监听器会在前一个(节点编号较小)的节点被删除后触发
Java Api版本
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public class MyLock {
// zk的连接串
private String IP = "ip:2181";
// 计数器对象
private CountDownLatch countDownLatch = new CountDownLatch(1);
//ZooKeeper配置信息
private ZooKeeper zooKeeper;
private static final String LOCK_ROOT_PATH = "/Locks";
private static final String LOCK_NODE_NAME = "Lock_";
private String lockPath;
// 打开zookeeper连接
MyLock() {
try {
zooKeeper = new ZooKeeper(IP, 5000, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.None) {
if (event.getState() == Event.KeeperState.SyncConnected) {
System.out.println("连接成功!");
countDownLatch.countDown();
}
}
}
});
countDownLatch.await();
} catch (Exception ex) {
ex.printStackTrace();
}
}
//获取锁
public void acquireLock() throws Exception {
//创建锁节点
createLock();
//尝试获取锁
attemptLock();
}
//创建锁节点
private void createLock() throws Exception {
//判断Locks是否存在,不存在创建
Stat stat = zooKeeper.exists(LOCK_ROOT_PATH, false);
if (stat == null) {
zooKeeper.create(LOCK_ROOT_PATH, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
// 创建临时有序节点
lockPath = zooKeeper.create(LOCK_ROOT_PATH + "/" + LOCK_NODE_NAME, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println("节点创建成功:" + lockPath);
}
//监视器对象,监视上一个节点是否被删除
private final Watcher watcher = new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDeleted) {
synchronized (this) {
notifyAll();
}
}
}
};
//尝试获取锁
private void attemptLock() throws Exception {
// 获取Locks节点下的所有子节点
List<String> list = zooKeeper.getChildren(LOCK_ROOT_PATH, false);
// 对子节点进行排序
Collections.sort(list);
// /Locks/Lock_000000001
int index = list.indexOf(lockPath.substring(LOCK_ROOT_PATH.length() + 1));
if (index == 0) {
System.out.println("获取锁成功!");
} else {
// 上一个节点的路径
String path = list.get(index - 1);
Stat stat = zooKeeper.exists(LOCK_ROOT_PATH + "/" + path, watcher);
if (stat == null) {
attemptLock();
} else {
synchronized (watcher) {
watcher.wait();
}
attemptLock();
}
}
}
//释放锁
public void releaseLock() throws Exception {
//删除临时有序节点
zooKeeper.delete(this.lockPath,-1);
zooKeeper.close();
System.out.println("锁已经释放:"+this.lockPath);
}
public static void main(String[] args) {
try {
MyLock myLock = new MyLock();
myLock.createLock();
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
public class TicketSeller {
private void sell(){
System.out.println("售票开始");
// 线程随机休眠数毫秒,模拟现实中的费时操作
int sleepMillis = 5000;
try {
//代表复杂逻辑执行了一段时间
Thread.sleep(sleepMillis);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("售票结束");
}
private void sellTicketWithLock() throws Exception {
MyLock lock = new MyLock();
// 获取锁
lock.acquireLock();
sell();
//释放锁
lock.releaseLock();
}
public static void main(String[] args) throws Exception {
TicketSeller ticketSeller = new TicketSeller();
for(int i=0;i<10;i++){
ticketSeller.sellTicketWithLock();
}
}
}
Curator Api版本 InterProcessMutex
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
import java.util.concurrent.CountDownLatch;
/**
* @author Suqi
* @version 1.0
* @date 2022/7/6 17:42
* @desc
*/
public class InterprocessLock {
static CountDownLatch countDownLatch = new CountDownLatch(10);
public static void main(String[] args) {
CuratorFramework zkClient = getZkClient();
String lockPath = "/lock";
InterProcessMutex lock = new InterProcessMutex(zkClient, lockPath);
//模拟100个线程抢锁
for (int i = 0; i < 10; i++) {
new Thread(new TestThread(i, lock)).start();
}
}
static class TestThread implements Runnable {
private Integer threadFlag;
private InterProcessMutex lock;
public TestThread(Integer threadFlag, InterProcessMutex lock) {
this.threadFlag = threadFlag;
this.lock = lock;
}
@Override
public void run() {
try {
lock.acquire();
System.out.println("第"+threadFlag+"线程获取到了锁");
//等到1秒后释放锁
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}finally {
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
private static CuratorFramework getZkClient() {
String zkServerAddress = "120.77.39.136:2181";
ExponentialBackoffRetry retryPolicy = new ExponentialBackoffRetry(1000, 3, 5000);
CuratorFramework zkClient = CuratorFrameworkFactory.builder()
.connectString(zkServerAddress)
.sessionTimeoutMs(5000)
.connectionTimeoutMs(5000)
.retryPolicy(retryPolicy)
.build();
zkClient.start();
return zkClient;
}
}
6.搭建Zookeeper集群
6.1 搭建要求
真实的集群是需要部署在不同的服务器上的,但是在我们测试时同时启动很多个虚拟机内存会吃不消,所以我们通常会搭建伪集群,也就是把所有的服务都搭建在一台虚拟机上,用端口进行区分。
我们这里要求搭建一个三个节点的Zookeeper集群(伪集群)。
6.2 准备工作
重新部署一台虚拟机作为我们搭建集群的测试服务器。
(1)安装JDK 【此步骤省略】。
(2)Zookeeper压缩包上传到服务器
(3)将Zookeeper解压 ,建立/usr/local/zookeeper-cluster目录,将解压后的Zookeeper复制到以下三个目录
/usr/local/zookeeper-cluster/zookeeper-1
/usr/local/zookeeper-cluster/zookeeper-2
/usr/local/zookeeper-cluster/zookeeper-3
[root@localhost ~]# mkdir /usr/local/zookeeper-cluster
[root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-1
[root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-2
[root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-3
(4)创建data目录 ,并且将 conf下zoo_sample.cfg 文件改名为 zoo.cfg
mkdir /usr/local/zookeeper-cluster/zookeeper-1/data
mkdir /usr/local/zookeeper-cluster/zookeeper-2/data
mkdir /usr/local/zookeeper-cluster/zookeeper-3/data
mv /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
mv /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
mv /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
(5) 配置每一个Zookeeper 的dataDir 和 clientPort 分别为2181 2182 2183
修改/usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
clientPort=2181
dataDir=/usr/local/zookeeper-cluster/zookeeper-1/data
修改/usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
clientPort=2182
dataDir=/usr/local/zookeeper-cluster/zookeeper-2/data
修改/usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
clientPort=2183
dataDir=/usr/local/zookeeper-cluster/zookeeper-3/data
6.3 配置集群
(1)在每个zookeeper的 data 目录下创建一个 myid 文件,内容分别是1、2、3 。这个文件就是记录每个服务器的ID
echo 1 >/usr/local/zookeeper-cluster/zookeeper-1/data/myid
echo 2 >/usr/local/zookeeper-cluster/zookeeper-2/data/myid
echo 3 >/usr/local/zookeeper-cluster/zookeeper-3/data/myid
(2)在每一个zookeeper 的 zoo.cfg配置客户端访问端口(clientPort)和集群服务器IP列表。
集群服务器IP列表如下
vim /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
server.1=192.168.149.135:2881:3881
server.2=192.168.149.135:2882:3882
server.3=192.168.149.135:2883:3883
解释:server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
6.4 启动集群
启动集群就是分别启动每个实例。
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh start
启动后我们查询一下每个实例的运行状态
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
7.一致性协议:zab协议
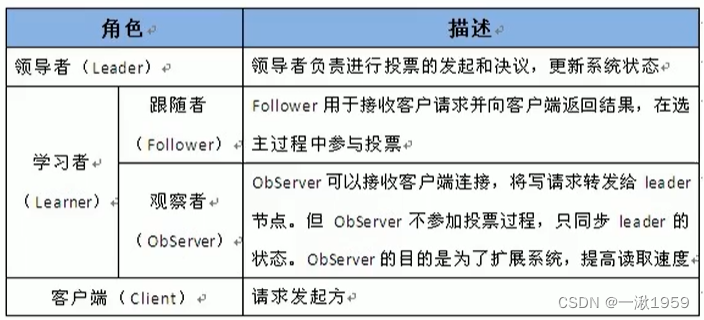
zab协议 的全称是 Zookeeper Atomic Broadcast (zookeeper原子广播)。zookeeper 是通过 zab协议来保证分布式事务的最终一致性
基于zab协议,zookeeper集群中的角色主要有以下三类,如下表所示:
zab广播模式工作原理,通过类似两阶段提交协议的方式解决数据一致性:
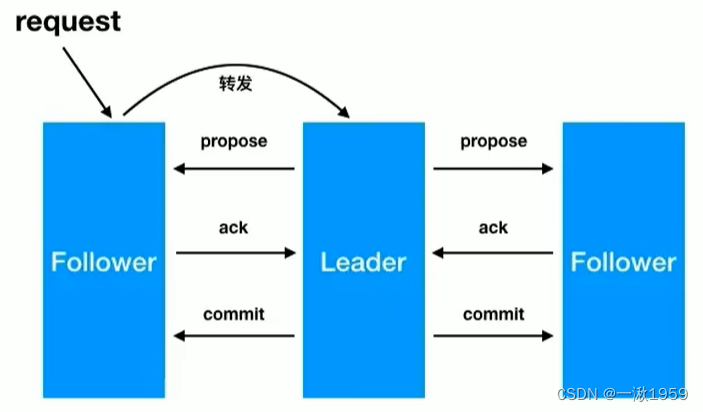
- leader从客户端收到一个写请求
- leader生成一个新的事务并为这个事务生成一个唯一的ZXID
- leader将这个事务提议(propose)发送给所有的follows节点
- follower节点将收到的事务请求加入到历史队列(history queue)中,并发送ack给leader
- 当leader收到大多数follower(半数以上节点)的ack消息,leader会发送commit请求
- 当follower收到commit请求时,从历史队列中将事务请求commit
7.1 observer角色及其配置
observer角色特点:
- 不参与集群的leader选举
- 不参与集群中写数据时的ack反馈
为了使用observer角色,在任何想变成observer角色的配置文件中加入如下配置:
peerType=observer
并在所有server的配置文件中,配置成observer模式的server的那行配置追加:observer,例如:
server.3=192.168.188.133:2289:3389:observer
8.zookeeper的leader选举
8.1 服务器状态
looking:寻找leader状态。当服务器处于该状态时,它会认为当前集群中没有leader,因此需要进入leader选举状态。
leading: 领导者状态。表明当前服务器角色是leader。
following: 跟随者状态。表明当前服务器角色是follower。
observing:观察者状态。表明当前服务器角色是observer。
8.2 服务器启动时期的leader选举
在集群初始化阶段,当有一台服务器server1启动时,其单独无法进行和完成leader选举,当第二台服务器server2启动时,此时两台机器可以相互通信,每台机器都试图找到leader,于是进入leader选举过程。选举过程如下:
- 每个server发出一个投票。由于是初始情况,server1和server2都会将自己作为leader服务器来进行投票,每次投票会包含所推举的服务器的myid和zxid,使用(myid, zxid)来表示,此时server1的投票为(1, 0),server2的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
- 集群中的每台服务器接收来自集群中各个服务器的投票。
- 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行pk,pk规则如下:
- 优先检查zxid。zxid比较大的服务器优先作为leader。
- 如果zxid相同,那么就比较myid。myid较大的服务器作为leader服务器。
对于Server1而言,它的投票是(1, 0),接收Server2的投票为(2, 0),首先会比较两者的zxid,均为0,再比较myid,此时server2的myid最大,于是更新自己的投票为(2, 0),然后重新投票,对于server2而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
- 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于server1、server2而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出了leader
- 改变服务器状态。一旦确定了leader,每个服务器就会更新自己的状态,如果是follower,那么就变更为following,如果是leader,就变更为leading。
8.3 服务器运行时期的Leader选举
在zookeeper运行期间,leader与非leader服务器各司其职,即便当有非leader服务器宕机或新加入,此时也不会影响leader,但是一旦leader服务器挂了,那么整个集群将暂停对外服务,进入新一轮leader选举,其过程和启动时期的Leader选举过程基本一致。
假设正在运行的有server1、server2、server3三台服务器,当前leader是server2,若某一时刻leader挂了,此时便开始Leader选举。选举过程如下:
- 变更状态。leader挂后,余下的服务器都会将自己的服务器状态变更为looking,然后开始进入leader选举过程。
- 每个server会发出一个投票。在运行期间,每个服务器上的zxid可能不同,此时假定server1的zxid为122,server3的zxid为122,在第一轮- 投票中,server1和server3都会投自己,产生投票(1, 122),(3, 122),然后各自将投票发送给集群中所有机器。
- 接收来自各个服务器的投票。与启动时过程相同
- 处理投票。与启动时过程相同,此时,server3将会成为leader。
- 统计投票。与启动时过程相同。
- 改变服务器的状态。与启动时过程相同。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









