







目录
__init__ 中需要将一个文件中的全部数据都读取进来,才能进行模型训练吗?
TensorFlow高效并行训练机制解析
通过合理配置数据流水线和分布式策略,可以最大化硬件利用率,减少训练时间。
TFRecord 格式的优势
TFRecord 是 TensorFlow 推荐的二进制数据格式,具有以下优点:
高效存储:数据以二进制形式存储,占用空间小,读写速度快。
并行化支持:支持分片(Sharding),将大数据集拆分成多个文件(如 data-00001-of-00010.tfrecord),便于并行读取。
序列化结构:使用 tf.train.Example 存储结构化数据,支持多种数据类型(图像、文本、数值等)。
数据流水线优化(tf.data API)
TensorFlow 的 tf.data API 是高效数据处理的基石,通过流水线化(Pipelining)和并行化机制减少训练瓶颈:
1. 并行数据读取
- 多文件并行读取:使用 tf.data.TFRecordDataset 读取多个 TFRecord 文件,通过 num_parallel_reads 参数并行读取多个文件
filenames = ["file1.tfrecord", "file2.tfrecord"]
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=4)
- 数据交错读取(Interleave):使用 interleave 函数混合多个文件的数据,同时控制并行度。
dataset = tf.data.Dataset.from_tensor_slices(filenames)
dataset = dataset.interleave(
lambda x: tf.data.TFRecordDataset(x),
cycle_length=4, # 并行读取的文件数
num_parallel_calls=tf.data.AUTOTUNE
)3. 数据预处理并行化
- 并行化 map 操作:使用 map 对数据进行解码和预处理,通过 num_parallel_calls 参数启用多线程/进程。使用 tf.data.AUTOTUNE 让 TensorFlow 自动选择最优的并行参数:
def parse_example(proto):
# 解析 TFRecord 中的 Example
return parsed_data
dataset = dataset.map(parse_example, num_parallel_calls=tf.data.AUTOTUNE)
4. 数据预取(Prefetch)
- 预取机制:在训练当前批次时,后台异步准备下一批次数据,消除 CPU 与 GPU 之间的空闲时间。用户可能需要知道如何设置prefetch的大小,通常设为tf.data.AUTOTUNE让TensorFlow自动调整。
dataset = dataset.prefetch(buffer_size=tf.data.AUTOTUNE)5. 数据乱序(Shuffle)
- 缓冲区乱序:使用 shuffle 函数打乱数据顺序,通过 buffer_size 控制随机性。较大的缓冲区提高乱序程度,但占用更多内存。
dataset = dataset.shuffle(buffer_size=10000)6. 批处理(Batching)
- 动态批处理:使用 batch 函数合并数据为批次,支持动态填充(padded_batch)处理变长数据。
dataset = dataset.batch(batch_size)
分布式训练优化
TensorFlow 支持多 GPU 和多节点训练,通过以下方式优化数据并行:
- 数据分片:
将数据集分片分配给不同的计算节点,每个节点处理不同的数据子集。
使用 tf.distribute.Strategy 自动处理数据分片:
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
dataset = strategy.distribute_datasets_from_function(dataset_fn)Torch高效并行训练机制解析
PyTorch 虽然没有与 TensorFlow 的 tf.data API 和 TFRecord 格式完全相同的机制,但它通过 torch.utils.data 模块和分布式训练库实现了类似的功能。以下是 PyTorch 中与 TensorFlow 对应的高效数据并行训练机制及实现方法
### 数据格式的替代方案: 有什么呢?
数据加载器DataLoader
PyTorch 的 DataLoader 是数据并行化的核心工具,支持多进程预加载和批处理:
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
def __init__(self, filenames):
self.filenames = filenames
# 加载数据到内存或定义动态加载逻辑
def __getitem__(self, index):
# 返回单条数据(如图像和标签)
return data, label
def __len__(self):
return len(self.filenames)
dataset = CustomDataset(filenames)
dataloader = DataLoader(
dataset,
batch_size=32,
shuffle=True,
num_workers=4, # 并行加载的进程数
pin_memory=True, # 加速数据到 GPU 的传输
persistent_workers=True # 保持工作进程存活(避免重复初始化)
)参数:
1. 置 pin_memory=True,使 DataLoader 将数据缓存在锁页内存(Page-Locked Memory),加速 CPU 到 GPU 的拷贝。
2. 内存缓存:在 Dataset 的 __init__ 中加载全部数据(适用于小数据集)。__init__ 中需要将一个文件中的全部数据都读取进来,才能进行模型训练吗?
3. num_workers:PyTorch 没有 tf.data.AUTOTUNE,但可通过实验找到最佳值(通常设为 CPU 核心数或 GPU 数量的 4 倍)。
数据流水线优化
- (1) 并行数据加载
多进程预加载:通过 num_workers 参数指定并行加载数据的进程数,类似 TensorFlow 的 num_parallel_calls。
预取机制:PyTorch 的 DataLoader 默认在后台预取数据(通过多进程实现),无需显式调用 prefetch。
- (2) 数据预处理
动态预处理:在 Dataset 的 __getitem__ 方法中实现数据解析和增强。
GPU 加速:使用 torchvision.transforms 的 GPU 版本(需自定义实现,或使用第三方库如 kornia)。
- (3) 数据乱序(Shuffle)
通过 DataLoader 的 shuffle=True 实现缓冲区乱序。
- (4) 批处理与动态填充
静态批处理:DataLoader 的 batch_size 参数直接指定批次大小。
动态填充:使用 collate_fn 处理变长数据(如文本)
def collate_fn(batch):
# 对变长数据(如序列)进行填充
data = [item[0] for item in batch]
labels = [item[1] for item in batch]
padded_data = torch.nn.utils.rnn.pad_sequence(data, batch_first=True)
return padded_data, torch.tensor(labels)
dataloader = DataLoader(..., collate_fn=collate_fn)
数据并行
支持单机多卡和多机多卡,PyTorch 通过 torch.distributed 和 DistributedDataParallel 实现数据并行:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def train(rank, world_size):
# 初始化进程组
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# 模型和数据加载器
model = MyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
# 数据分片(每个进程加载不同的子集)
dataset = CustomDataset(...)
sampler = torch.utils.data.distributed.DistributedSampler(dataset)
dataloader = DataLoader(dataset, batch_size=32, sampler=sampler)
for data, labels in dataloader:
data, labels = data.to(rank), labels.to(rank)
outputs = ddp_model(data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if __name__ == "__main__":
world_size = 4 # GPU 数量
mp.spawn(train, args=(world_size,), nprocs=world_size)
多机多卡:
# 单节点启动(4 GPU)
torchrun --nproc_per_node=4 train.py
# 多节点启动
torchrun --nnodes=2 --nproc_per_node=8 --rdzv_id=123 --rdzv_backend=c10d --rdzv_endpoint=192.168.1.1:29500 train.py
问题:
__init__ 中需要将一个文件中的全部数据都读取进来,才能进行模型训练吗?
PyTorch 中处理数据的两种典型方式:
1. 懒加载(Lazy Loading)
原理:在 __init__ 中仅存储数据路径或元信息,在 __getitem__ 中按需加载单条数据。
优点:节省内存,适合大规模数据集。
import os
from PIL import Image
from torch.utils.data import Dataset
class LazyLoadDataset(Dataset):
def __init__(self, data_dir):
self.data_dir = data_dir
self.filenames = os.listdir(data_dir) # 仅存储文件名,不加载数据
def __getitem__(self, index):
# 按需加载单条数据(如从文件读取)
img_path = os.path.join(self.data_dir, self.filenames[index])
image = Image.open(img_path).convert("RGB")
label = 0 # 假设标签需要其他方式获取(如文件名解析)
return image, label
def __len__(self):
return len(self.filenames)2. 预加载(Preloading)
原理:在 __init__ 中一次性将所有数据加载到内存。
优点:训练速度快(无需频繁 IO 操作),适合小数据集。
(预加载(Preloading) 指的是在 Dataset 的 __init__ 方法中一次性将所有文件的数据读取到内存中。其速度与文件大小直接相关:文件总数据量越大,预加载时间越长,但后续训练时的数据访问速度会更快(因为无需频繁的磁盘 I/O), 所以可以将每个文件做的小一点)。
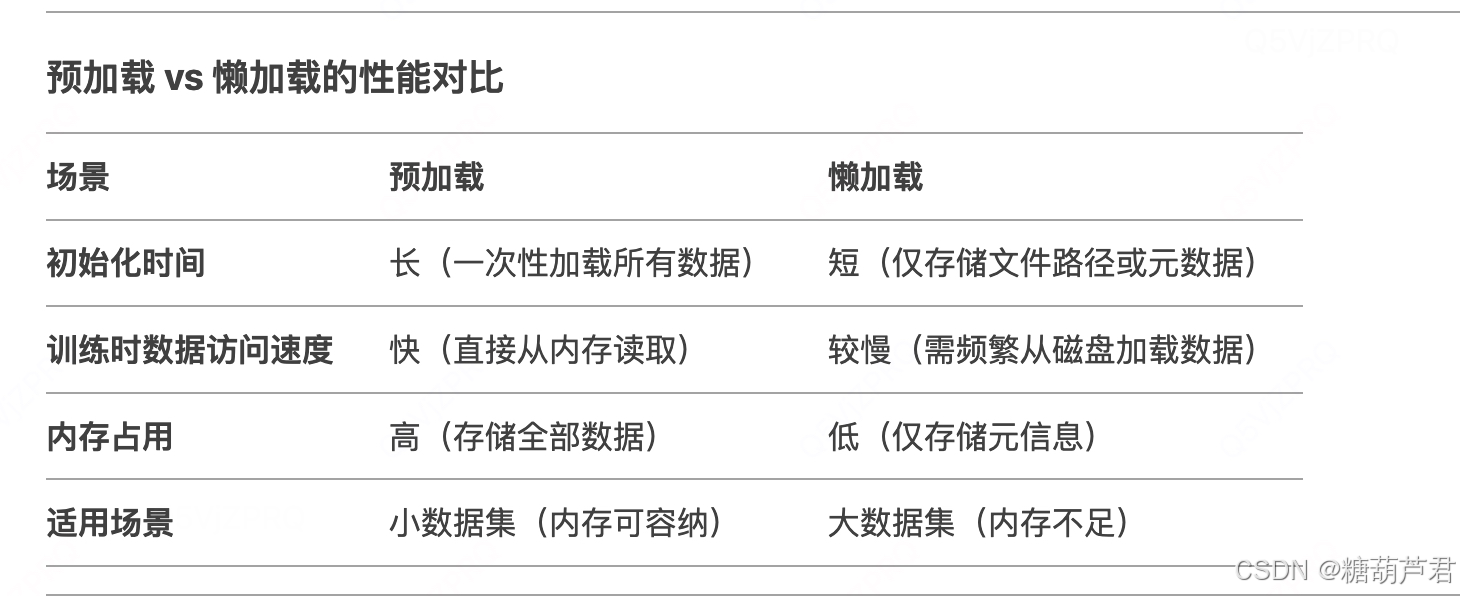
速度与文件大小的关系:
预加载时间:与数据集总大小(文件数量 × 单文件大小)成正比。例如:
100 张 1MB 的图片 → 总数据量 100MB,加载时间较短。
10 万张 1MB 的图片 → 总数据量 100GB,加载时间可能长达数分钟甚至小时级。
训练速度:预加载后,数据已驻留内存,训练时的数据访问延迟极低(无磁盘 I/O 开销)。
方案: 那就将数据分成比较小的文件,然后进行预加载。
class PreloadDataset(Dataset):
def __init__(self, data_dir):
self.data = []
self.labels = []
filenames = os.listdir(data_dir)
for filename in filenames:
img_path = os.path.join(data_dir, filename)
image = Image.open(img_path).convert("RGB")
self.data.append(image)
self.labels.append(0) # 假设标签已知
def __getitem__(self, index):
return self.data[index], self.labels[index]
def __len__(self):
return len(self.data)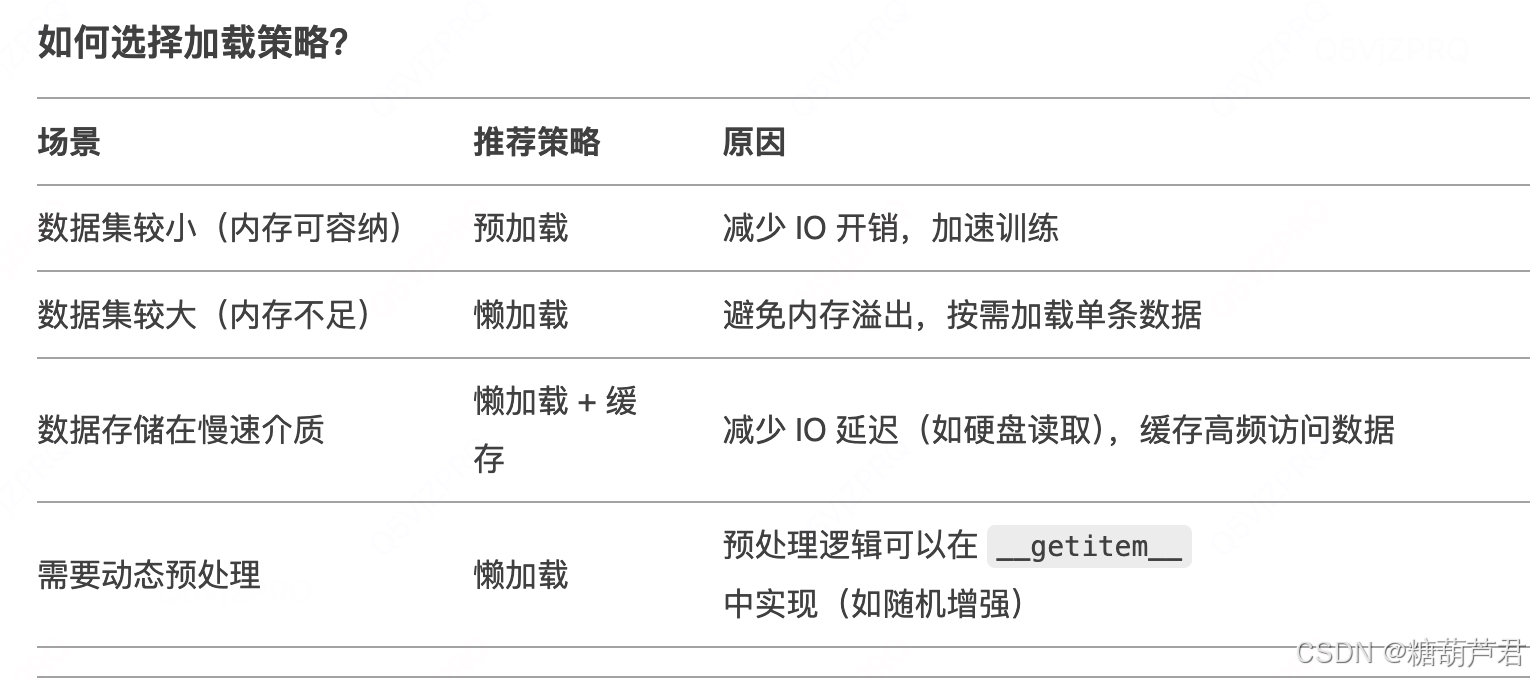
实践:
确认是预加载还是懒加载?-对比
不同数据存储方式-对比
实践下来当数据文件很大时,即使将数据分区醉的比较小,但是采用预加载的方式,还是避免不了gpu等待的时间:
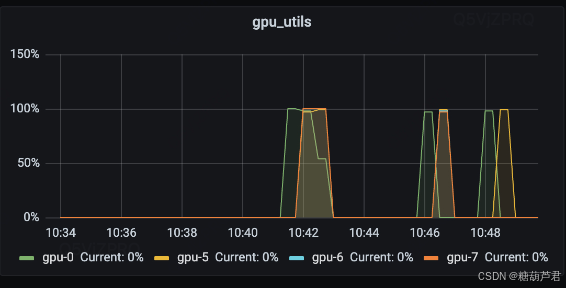
降低gpu等待时间
对于小批量数,可以完全载入内存的数据集来说,我们一般的实践是通过定义 torch.utils.data.Dataset 这个类类实现,但是对于好几TB甚至更大的数量来说,我们显然无法直接加载到内存,因此我们需要使用 torch.utils.data.IterableDataset 来实现。这个类适用于处理大数据或者流式数据。
torch.utils.data — PyTorch 2.6 documentation
class ShardedIterableDataset(IterableDataset):
def __init__(self, data, num_workers, worker_id):
self.data = data
self.num_workers = num_workers
self.worker_id = worker_id
def __iter__(self):
# 根据worker_id分配数据片段
for idx, item in enumerate(self.data):
if idx % self.num_workers == self.worker_id:
yield item
# 在DataLoader中通过worker_init_fn设置分片
def worker_init_fn(worker_id):
dataset.worker_id = worker_id
dataloader = DataLoader(
dataset=ShardedIterableDataset(data, num_workers=2, worker_id=0),
num_workers=2,
worker_init_fn=worker_init_fn
)-
IterableDataset的特性:-
通过
__iter__方法返回一个迭代器。 -
每个工作进程(Worker)会复制该迭代器,默认导致所有进程遍历完整数据集(即数据重复)。
-
需要注意的是,IterableDataset需要配合数据分片来使用,否则每个worker会读取同一份数据造成重复。
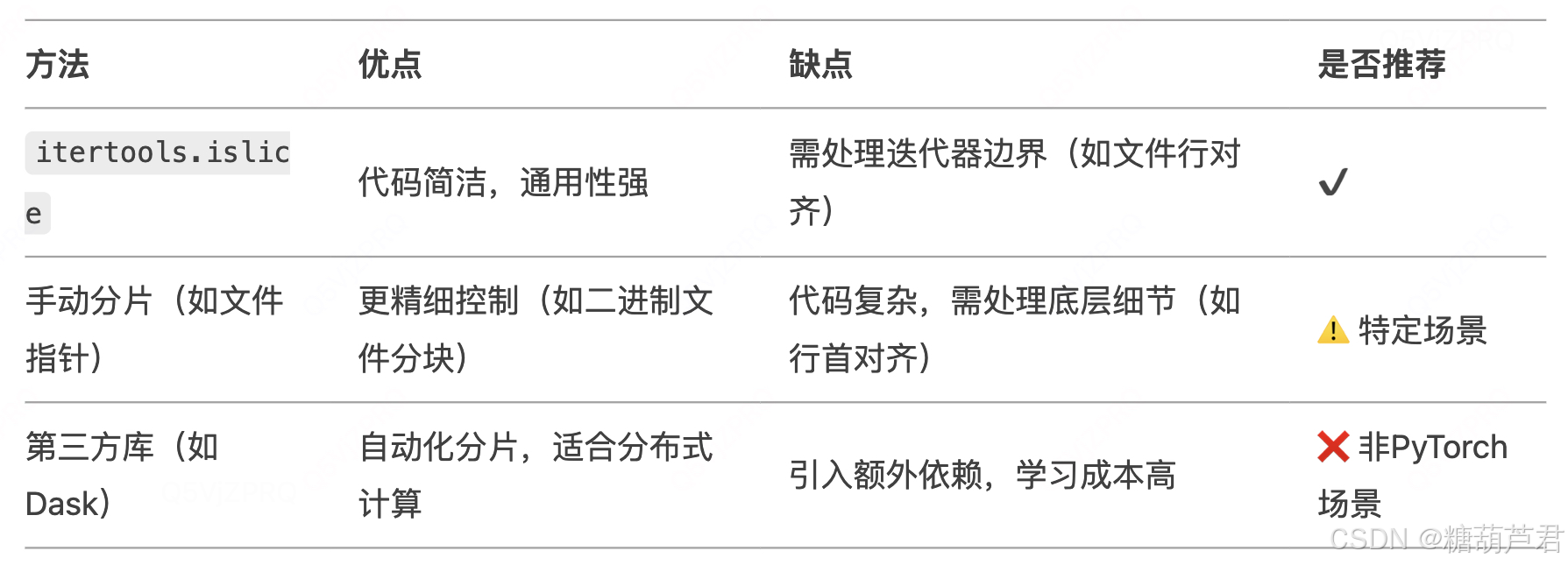
分片的作用:
- 通过
itertools.islice或类似方法,将原始迭代器的不同子集分配给不同 Worker。 -
每个 Worker 只处理自己分片的数据,确保全局数据无重复。
from torch.utils.data import IterableDataset
import itertools
class ShardedIterableDataset(IterableDataset):
def __init__(self, data_iter, num_workers, worker_id):
self.data_iter = data_iter # 原始数据迭代器(如文件逐行读取)
self.num_workers = num_workers
self.worker_id = worker_id
def __iter__(self):
# 分片逻辑:每个Worker只取属于自己的数据块
return itertools.islice(self.data_iter, self.worker_id, None, self.num_workers)
def worker_init_fn(worker_id):
# 在DataLoader初始化时,为每个Worker设置其ID
dataset.worker_id = worker_id
# 创建DataLoader
dataset = ShardedIterableDataset(
data_iter=stream_large_file(), # 原始迭代器(如逐行读取文件)
num_workers=4,
worker_id=0 # 初始值会被worker_init_fn覆盖
)
dataloader = DataLoader(
dataset,
batch_size=128,
num_workers=4,
worker_init_fn=worker_init_fn #通过 worker_init_fn 传递分片参数
)使用其他数据分片方式也是有效的:
结果:
验证果然有效
文件存储格式有哪些更高效的方式?配合读取
参考
- IterableDataset 实现:https://www.cnblogs.com/TianyuSu/p/16494316.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









