







梯度累加
目的
梯度累积是一种训练神经网络的技术,主要用于在内存有限的情况下处理较大的批量大小(batch size)。通常,较大的批量可以提高训练的稳定性和效率,但受限于GPU或TPU的内存,无法一次性加载大批量数据。
梯度累积通过多次前向传播和反向传播累积梯度,然后一次性更新模型参数,从而模拟大批量训练的效果。
总结:
-
显存限制:GPU/TPU显存有限,无法一次性加载大批量数据。
-
训练稳定性:大批量训练通常更稳定(梯度噪声更小),但需要更多显存。
-
资源优化:允许在低显存设备上训练更大模型或使用更大等效批量。
原理
在标准的训练过程中,每个批次(batch)的数据会进行一次前向传播计算损失,然后反向传播计算梯度,并立即更新模型参数。而梯度累积则是在多个小批次(mini-batches)上进行前向和反向传播,但不立即更新参数,而是将梯度累积起来,直到达到预设的累积步数(accumulation steps)后,才用累积的梯度更新参数。这样,等效的批量大小就是每个小批量的样本数乘以累积步数。
优点:
能够突破显存限制,允许使用更大的等效批量,提高训练效率,
缺点:
能引入的梯度噪声,因为梯度是多次小批量累积的结果,可能会影响模型收敛的稳定性。
代码
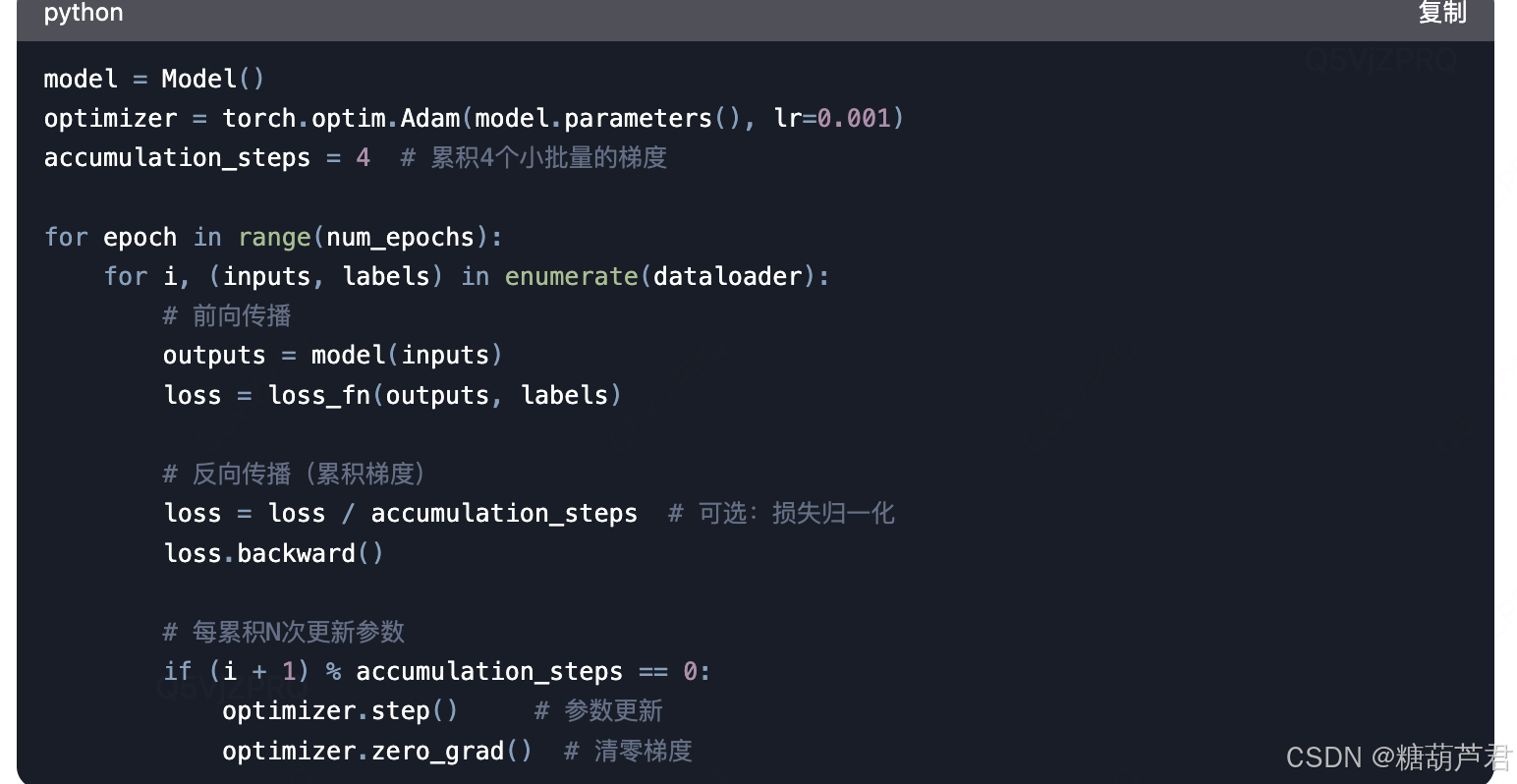
- loss.backward是计算梯度的过程,如果不调用optimizer.zero_grad()的话,每一步的梯度不会清零。所以上述代码会进行accumulation_steps的梯度累计,所以会将loss进行归一化防止梯度过大。
optimizer.step()通过累加的梯度对网络参数进行更新。 - 学习率需要相应的进行适配
实践
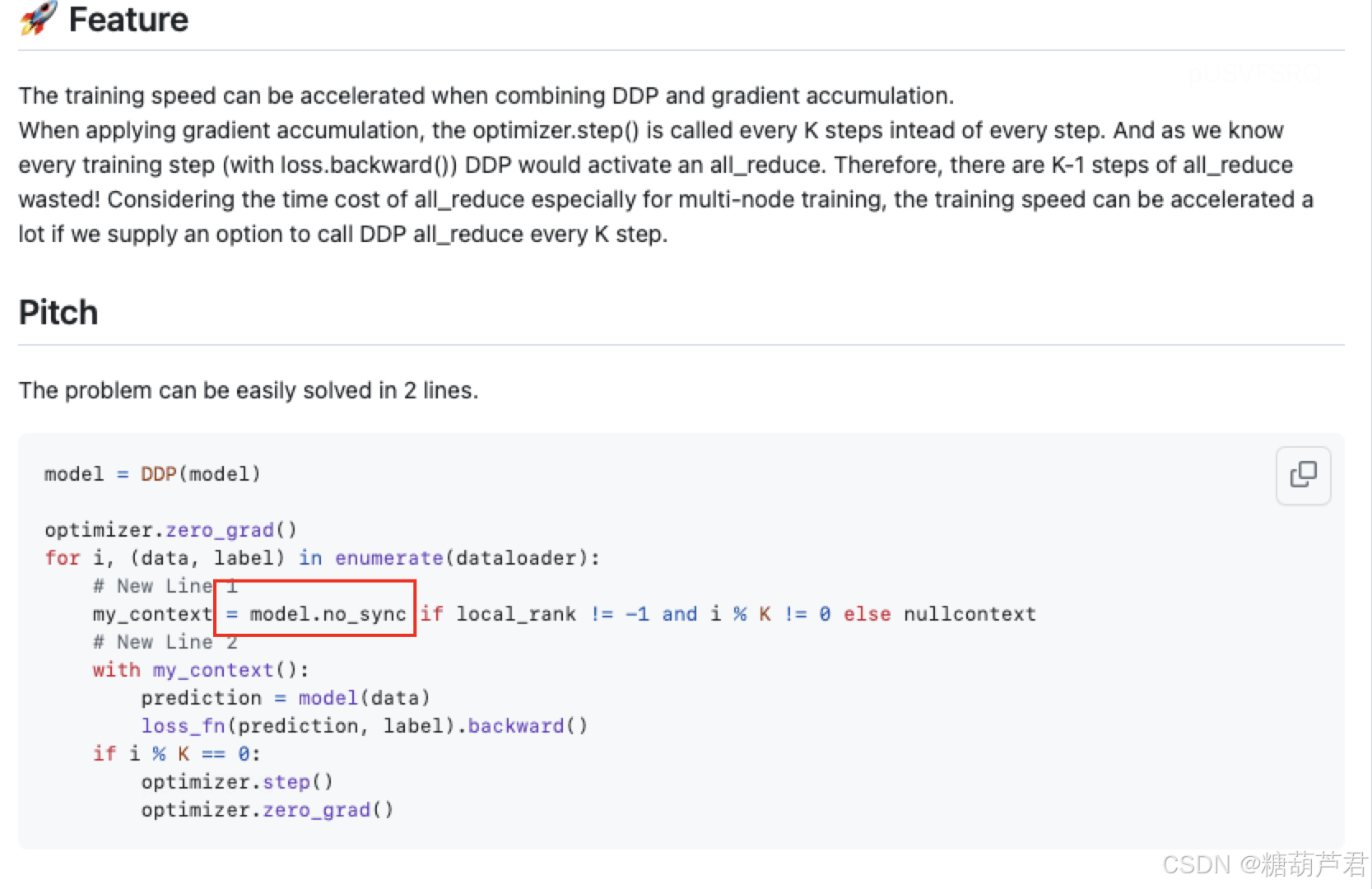
和DDP的结合:
每个loss.backward()都会进行多卡数据的整合计算,如果不需要进行网络更新的话,那么其实不需要进行all_reduce 操作,所以有k-1次的reduce是浪费的,以下代码实现每k步在进行网络参数更新时才进行reduce操作。
混合精度+梯度累加 + 梯度缩放: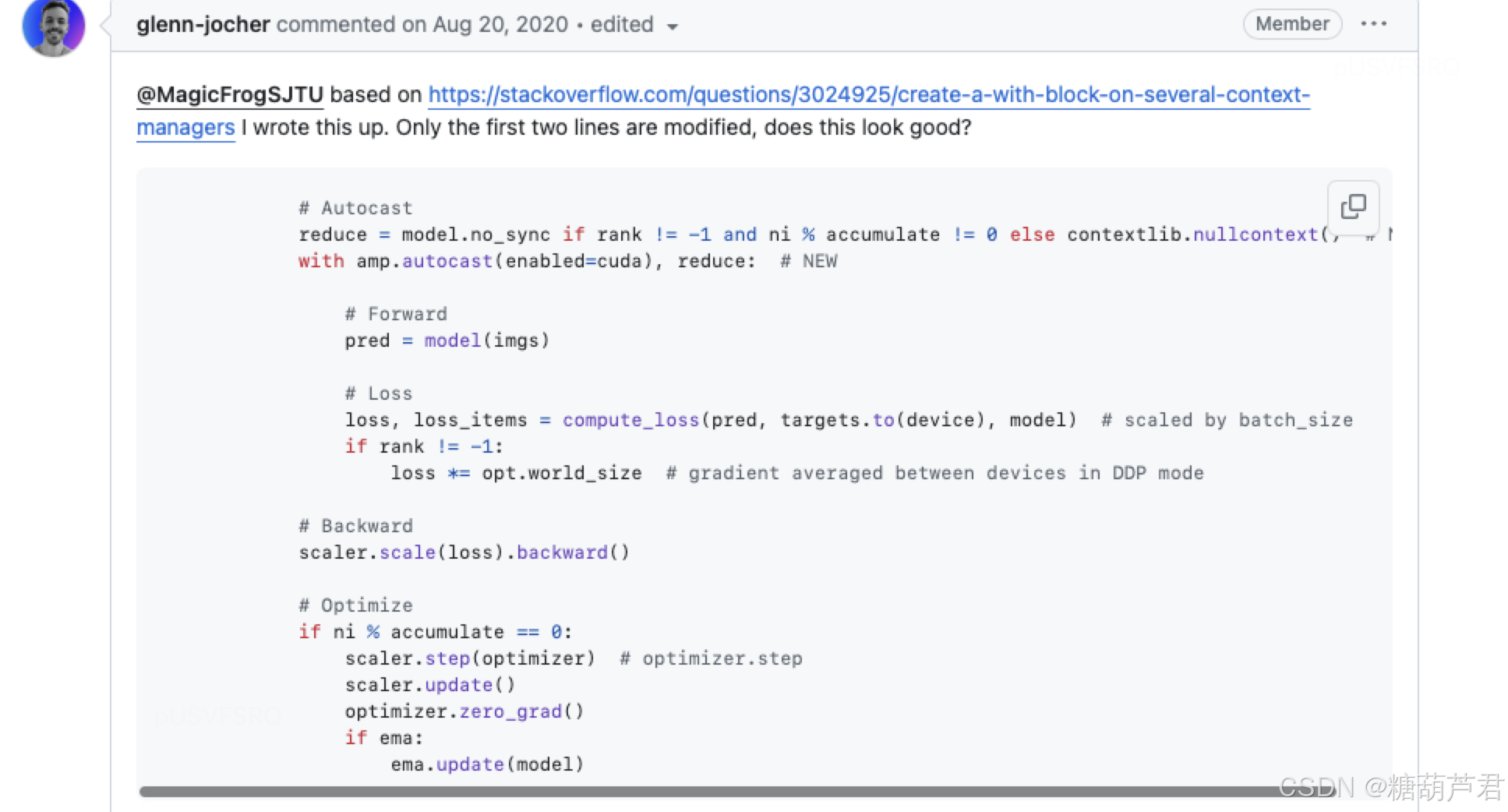
梯度检查点(Gradient Checkpointing)
大模型的参数量巨大,通常在计算梯度时,我们需要将所有前向传播时的激活值保存下来,这消耗大量显存。
还有另外一种延迟计算的思路,丢掉前向传播时的激活值,在计算梯度时需要哪部分的激活值就重新计算哪部分的激活值,这样做倒是解决了显存不足的问题,但加大了计算量同时也拖慢了训练。用时间换空间
梯度检查点(Gradient Checkpointing)在上述两种方式之间取了一个平衡,这种方法采用了一种策略选择了计算图上的一部分激活值保存下来,其余部分丢弃,这样被丢弃的那一部分激活值需要在计算梯度时重新计算。
前向传播过程中计算节点的激活值并保存,计算下一个节点完成后丢弃中间节点的激活值,反向传播时如果有保存下来的梯度就直接使用,如果没有就使用保存下来的前一个节点的梯度重新计算当前节点的梯度再使用。可以减少不必要激活值的存储。
如果使用的是Huggingface的代码,那么只需要调用
model.gradient_checkpointing_enable()就可以实现
但是要检查代码里如果有涉及gradient_checkpointing的部分要保证参数值一致。
参考:
- https://github.com/ultralytics/yolov5/issues/790
- https://cloud.tencent.com/developer/article/2338646

















 65
65

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









