







range分区
range分区,分区字段必须是整型或者转换为整型
按照字段的区间划分数据的归属,典型的就是按照时间维度的月份分区
对于range分区,分区字段必须是整型或者转换为整型,如果分区字段是日期类型的字段,那么就必须将日期类型的字段转换成整型类型
对于日期类型的转换,优化器只支持year(),to_days,to_seconds,unix_timestamp()函数的转换,其他的并不支持,
也就是说,在按日期字段分区的时候,如果不是使用上述几个函数转换的,查询优化器将无法对相关查询进行优化。
语法:
create table <table> (
// 字段
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1
partition by range (分区字段) (
partition <分区名称> values less than (Value),
partition <分区名称> values less than (Value),
...
partition <分区名称> values less than maxvalue
);
range:表示按范围分区
分区字段:表示要按照哪个字段进行分区,可以是一个字段名,也可以是对某个字段进行表达式运算如year(create_time),使用range最终的值必须是数字
分区名称: 要保证不同,也可以采用 p0、p1、p2 这样的分区名称,
less than : 表示小于
Value : 表示要小于某个具体的值,如 less than (10) 那么分区字段的值小于10的都会被分到这个分区
maxvalue: 表示一个最大的值
demo1:
假如一个大型超市有40多家门店,该表保存40家超市的职员记录。这40家超市的的编号从1到40,若果你想将其分成4个小分区,那么你可以采用range分区,创建的数据库表如下:
#方式1
CREATE TABLE `employees_range_max` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`ename` varchar(30) NOT NULL DEFAULT '' COMMENT '员工名称',
`ecode` varchar(30) NOT NULL DEFAULT '' COMMENT '员工编号',
`store_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '所属门店',
`create_time` datetime(6) DEFAULT NULL COMMENT '添加时间',
PRIMARY KEY (`id`,`store_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='员工表'
partition by range(store_id)(
partition p0 values less than(11),
partition p1 values less than(21),
partition p2 values less than(31),
partition p3 values less than MAXVALUE
);
【注意:MAXVALUE 表示最大的可能的整数值】
分区文件(截图):

#方式2:
CREATE TABLE `employees_range` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`ename` varchar(30) NOT NULL DEFAULT '' COMMENT '员工名称',
`ecode` varchar(30) NOT NULL DEFAULT '' COMMENT '员工编号',
`store_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '所属门店',
`create_time` datetime(6) DEFAULT NULL COMMENT '添加时间',
PRIMARY KEY (`id`,`store_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='员工表'
partition by range(store_id)(
partition p0 values less than(11),
partition p1 values less than(21),
partition p2 values less than(31),
partition p3 values less than (41)
);
【注意:超过分区range范围的数据,将无法插入数据】
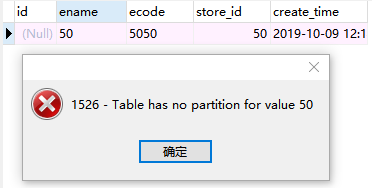
分区文件(截图):

demo2:
假如一个大型超市有40多家门店,该表保存40家超市的职员记录。你想把员工按时间方式保存,可以将create_time作为key:
CREATE TABLE `employees_range_date` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`ename` varchar(30) NOT NULL DEFAULT '' COMMENT '员工名称',
`ecode` varchar(30) NOT NULL DEFAULT '' COMMENT '员工编号',
`store_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '所属门店',
`create_time` datetime(6) NOT NULL COMMENT '添加时间',
PRIMARY KEY (`id`,`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='员工表'
partition by range(YEAR(create_time))(
partition p0 values less than (2017),
partition p1 values less than (2018),
partition p2 values less than (2019),
partition p3 values less than (2020)
);
分区文件(截图):

1.新增分区:
#注意,当分区中有maxvalue时 无法直接添加分区,需要重置分区删除分区【删除分区会删除数据】
alter table employees_range add partition (partition p4 values less than (51));
alter table employees_range add partition (partition p5 values less than (61));
2.分区合并、重建分区
#将p0和p1合并
alter table employees_range
REORGANIZE PARTITION p0,p1,p2,p3,p4,p5 INTO
(
partition p1 values less than (21),
partition p2 values less than (31),
partition p3 values less than (41),
partition p4 values less than (51),
partition p5 values less than (61)
);
截图(合并之后没有p0区):

3.删除分区(删除了一个分区,也同时删除了该分区中所有的数据)
alter table employees_range drop partition p4;
4.移除表的分区
alter table employees_range remove partitioning;

















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









