







 本文介绍了消息中间件的核心作用,并详细对比了ActiveMQ、RocketMQ、RabbitMQ和Kafka四种常见消息中间件的优缺点。重点讨论了Kafka的高吞吐量特性以及为提高并发能力的partition设计。还分析了消息丢失的可能性及其解决方案,强调了配置的重要性。
本文介绍了消息中间件的核心作用,并详细对比了ActiveMQ、RocketMQ、RabbitMQ和Kafka四种常见消息中间件的优缺点。重点讨论了Kafka的高吞吐量特性以及为提高并发能力的partition设计。还分析了消息丢失的可能性及其解决方案,强调了配置的重要性。
我们使用消息中间件核心就是为了 解耦,异步,削峰平谷。我知道有4种,虽然之前项目都是用的kafka。
1、ActiveMq:较早的开源中间件,单机吞吐量万级,有性能瓶颈,适合吞吐量小的项目架构。
2、RocketMq:阿里开源的中间件。
优点:分布式架构,单机吞吐量十万级,支持高可用,高并发,每年双十一就可了解他的高可用了,那么大吞吐量都能支撑。
缺点:虽然开源,但是阿里有一套API没有开源,里面包含更好的一些优化,比如上游系统应用和下游mq解耦等,如果你新项目要实现,你需要修改大量代码。
3、RabbitMq:市面上很常见的中间件,轻量级的有路由器功能的中间件。
producer->路由器->队列->consumer,从而一对一还是广播,或者延时,死信队列等。
优点:前人踩过的坑很多,然后社区就比较丰富了,还有使用时候管理界面也是比较丰富。他的最大优点就是时效性高,因为RabbitMq是认为队列就是一个管道,所以不能在管道中停留太久。
缺点:性能有瓶颈,适合吞吐量小的架构。同样因为他认为是一个管道,所以他的消息堆积太多就会降低性能。
4、apache kafka。
优点:最大有点就是吞吐量高,他本身是为大数据准备的。单机吞吐量TPS 百万级/秒,也是分布式架构,高并发,高可用,一段数据多个结点存储,少量机器宕机,不影响数据的使用。
缺点:时效性低。
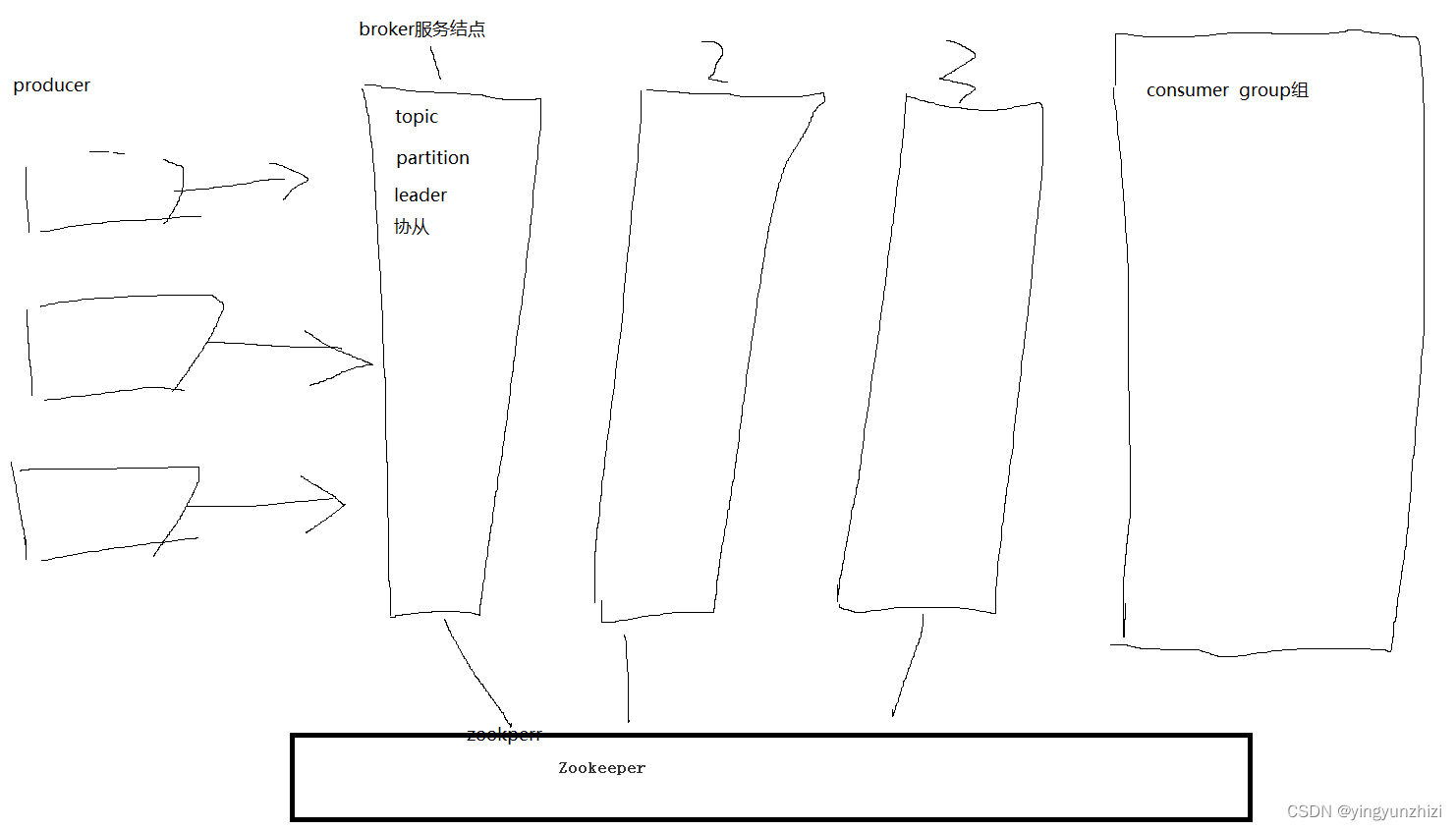
为了提高并发能力,一个topic以多个partition的方式分布到多个broker结点上,生产者producer发布消息后,他要发布到哪个partition,他是先到zookeeper上找到partition的主leader的位置,只将消息发布到主leader,从follower是同步主leader中的信息,kafka一般是pull的方式,等消费者根据他自己的速率来pull消息。
消息丢失:
a:生产者消息丢失,一般是producer发布消息后,leader接受了消息就确认发送成功了,但是如果这个时候leader挂了,你没有备份数据,数据就丢了。
解决:配置,必须至少要有一个从follower同步完数据才确认发送成功,否则让producer重新发送。
b:消息队列丢失消息,这个其实就是producer发布消息后,leader结点挂了,然后从follower还未同步完数据,然后zookeepr(为kafka存储和管理集群信息)讲follower改成主leader,但是没有数据,数据就丢失了。
解决:配置,一个leader,至少有2个从follower,然后要至少有一个follower和leader保持连接,这配置可以和上面生产者producer的联合使用。
c:消费者丢失消息,消费者从leader中pull消息时候,程序挂了,那你后面就不知道从哪里开始pull,kafka他也任务你已经处理完成了。
解决:offset可以解决,他是记录你partition消费数据的位置下标,比如有100小数据消费,你消费了50条,那你offset就会记录=49,从0开始的,然后下一次pull时候就从50开始pull。
将offset改成手动提交,你之前是自动提交,你消费了多少提交位置多少,否则kafka认为你处理好了

















 2152
2152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









