







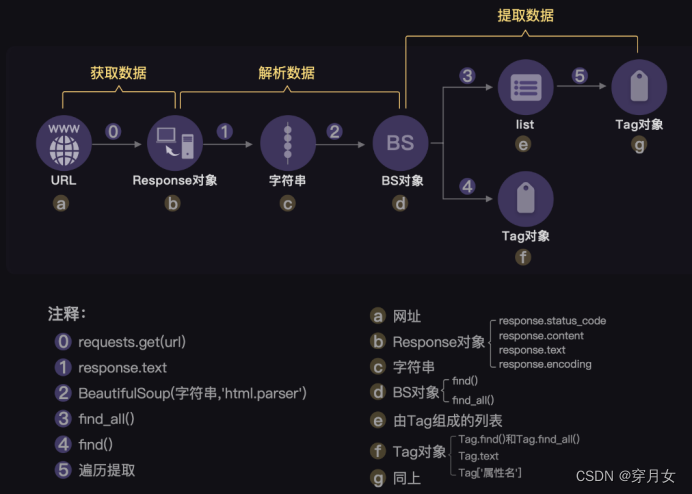
爬虫4步骤
第0步:获取数据。爬虫程序会根据我们提供的网址,向服务器发起请求,然后返回数据。
第1步:解析数据。爬虫程序会把服务器返回的数据解析成我们能读懂的格式。
第2步:提取数据。爬虫程序再从中提取出我们需要的数据。
第3步:储存数据。爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析。
问题
1. 数据爬取返回404
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.16.1</center>
</body>
</html>
原因:服务器识别到我们在爬取数据,所以返回404
解决:模拟浏览器访问服务器chrome://version/
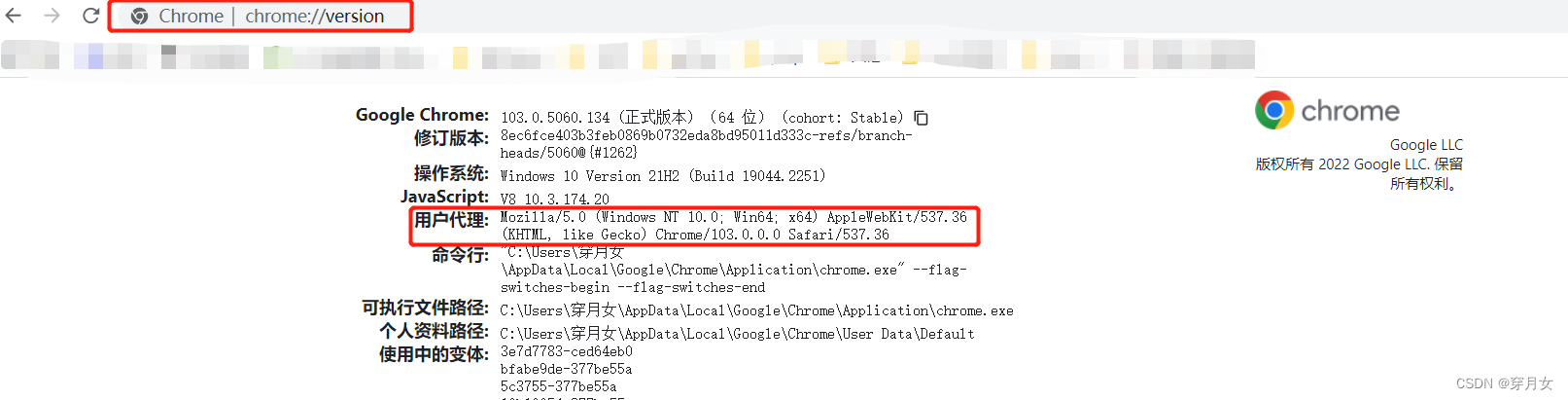
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"}
res = requests.get(url, headers=header)示例
import requests
from bs4 import BeautifulSoup
url = 'http://www.xiachufang.com/explore/'
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"}
#获取数据
res = requests.get(url, headers=header)
#解析数据
soup = BeautifulSoup(res.text, 'html.parser')
#提取数据
items = soup.find_all(class_="info pure-u")
for item in items:
title = item.find(class_="name").text.strip()
url = item.find(class_="name").find('a')['href']
shicai = item.find(class_="ing ellipsis").text
print(title, url, shicai)
















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









