







 本文详细介绍了Elasticsearch的功能特性,包括集群管理、文档存储、搜索机制与聚合分析,探讨了其在数据存储和搜索方面的优势与局限性,并通过实验对比了不同数据集和属性值种类对性能的影响。
本文详细介绍了Elasticsearch的功能特性,包括集群管理、文档存储、搜索机制与聚合分析,探讨了其在数据存储和搜索方面的优势与局限性,并通过实验对比了不同数据集和属性值种类对性能的影响。
目录
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene 基础之上。无论是开源还是私有, Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库。Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。它具有以下特点:一个分布式的实时文档存储,每个字段 可以被索引与搜索;一个分布式实时分析搜索引擎;能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据。
1 技术综述
1.1 Elasticsearch主要功能
Elasticsearch主要功能分为:1 Elasticsearch集群;2 文档存储;3 搜索;4 聚合,本文重点对这四个功能进行探索。
1.2 集群
一个运行中的Elasticsearch实例称为一个节点,而集群是由一个或者多个拥有相同 cluster.name配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
每个节点包含若干分片,一个分片是一个底层的工作单元 ,它仅保存了全部数据中的一部分。一个分片是一个 Lucene 的实例,它本身就是一个完整的搜索引擎。 我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互,索引实际上是指向一个或者多个物理分的逻辑命名空间 。
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
一个分片可以是主分片或者副本分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。一个副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
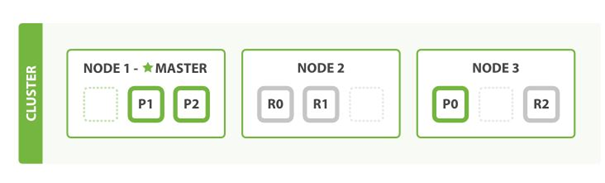
如图8.1所示,该集群拥有三个节点Node1、Node2、Node3,其中Node1中包含P1、P2主分片,Node2包含R0、R1副分片,Node3包含P0主分片和R2副分片。
当某节点别关闭或故障时,其他节点会将缺失主分片的副本提升为主分片,这个提升主分片的过程是瞬间发生的,如同按下一个开关一般。如图2.2所示,在我们关闭Node 1的同时也失去了主分片1和2,其他分片会立即将这些分片在Node 2和Node 3上对应的副本分片提升为主分片,并重新生成副本分片。
1.3 文档存储
一个对象是基于特定语言的内存的数据结构。为了通过网络发送或者存储它,我们需要将它表示成某种标准的格式。JSON 是一种以人可读的文本表示对象的方法。它已经变成 NoSQL 世界交换数据的事实标准。当一个对象被序列化成为 JSON,它被称为一个 JSON 文档 。
Elastcisearch是分布式的文档存储。它以JSON文档的形式,存储和检索复杂的数据结构。一旦一个文档被存储在Elasticsearch中,它就是可以被集群中的任意节点检索到。
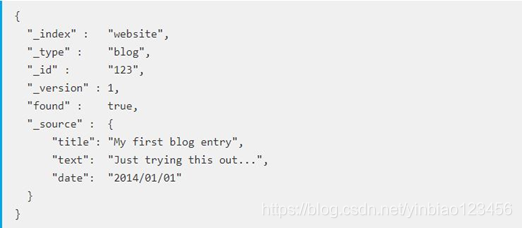
一个文档中包含有它的数据,也包含的有文档的元数据信息。文档数据一般存储在 _source 字段中,这个字段包含我们索引数据时发送给 Elasticsearch 的原始 JSON 文档。文档的元数据信息中, 三个必须的元数据元素如下:文档索引(_index),一个索引应该是因共同的特性被分组到一起的文档集合;文档类型(_type),数据可能在索引中只是松散的组合在一起,但是通常明确定义一些数据中的类别是很有用的。 例如,所有的产品都放在一个索引中,但是你有许多不同的产品类别,比如,customer,producer;文档唯一标识(_id)。一个文档的_index 、_type 和_id 唯一标识一个文档,我们可以通过唯一标识对文档进行增删改查等操作。如图8-3,这就是Elastcisearch 存储的一个文档。
1.4 搜索
在 Elasticsearch中,每个字段的所有数据都是默认被索引的。即每个字段都有为了快速检索设置的专用倒排索引。而且,不像其他多数的数据库,它能在相同的查询中使用所有这些倒排索引,并以惊人的速度返回结果。
1 多索引、多类型搜索
Elasticsearch支持多索引、多类型搜索,你想在一个或多个特殊的索引并且在一个或者多个特殊的类型中进行搜索。我们可以通过在URL中指定特殊的索引和类型达到这种效果,如下所示:
① /_search
在所有的索引中搜索所有的类型。
②/gb/_search
在 gb 索引中搜索所有的类型。
③/gb,us/_search
在 gb 和 us 索引中搜索所有的文档。
④/g*,u*/_search
在任何以 g 或者 u 开头的索引中搜索所有的类型。
⑤/gb/user/_search
在 gb 索引中搜索 user 类型。
⑥/gb,us/user,tweet/_search
在 gb 和 us 索引中搜索 user 和 tweet 类型。
⑦/_all/user,tweet/_search
在所有的索引中搜索 user 和 tweet 类型。
注:Elasticsearch 6.0以后不再支持多类型搜索
2 分页
Elasticsearch支持查询结果分页,这和 SQL 使用 LIMIT 关键字返回单个 page 结果的方法相同。Elasticsearch通过 接受 from 和 size 参数实现分页:size,显示应该返回的结果数量,默认是 10;from,显示应该跳过的初始结果数量,默认是 0。例如,如果每页展示 5条结果,可以用”GET /_search?size=5&from=5”得到第2页的结果。
在分布式系统中,对结果集排序的成本会随分页的深度成指数上升,考虑到分页过深以及一次请求太多结果的情况,web搜索引擎通常对任何查询都不会返回超过1000个结果。如果搜索结果超过默认的10000个,就需考虑使用Elasticsearch的深度索引。
3 基本的搜索方式
Elasticsearch常用的查询方式为精确值查询和匹配查询,其中,匹配查询功能更加强大,使用范围也更加广泛。
3.1 精确值查询
当进行精确值查找时, 我们会使用过滤器(filters)。过滤器很重要,因为它们执行速度非常快,不会计算相关度(直接跳过了整个评分阶段)而且很容易被缓存。例如,图2-4是一个索引为my_store、类型为products、价格为20的过滤搜索。

3.2匹配查询
匹配查询 match 是Elasticsearch的核心查询方式, 它既能处理全文字段,又能处理精确字段。无论需要查询什么字段, match 查询都应该会是首选的查询方式。match 查询主要的应用场景就是进行全文搜索,我们以下面一个简单例子来说明全文搜索是如何工作的,图8-5是一个单词的匹配查询:

Elasticsearch 执行上面这个match查询的步骤是:
① 检查字段类型 。
标题 title 字段是一个 string 类型( analyzed )已分析的全文字段,这意味着查询字符串本身也应该被分析。
② 分析查询字符串 。
将查询的字符串 QUICK! 传入标准分析器中,输出的结果是单个项 quick 。因为只有一个单词项,所以 match 查询执行的是单个底层 term 查询。
③ 查找匹配文档 。
用term查询在倒排索引中查找quick然后获取一组包含该项的文档,本例的结果是文档:1、2 和 3 。
④ 为每个文档评分 。
用 term 查询计算每个文档相关度评分 _score。
查询结果如图8-6所示:

Elasticsearch还支持多词查询的全文检索,match 查询让多词查询变得简单,例如,图8-7是对“title”为“BROWN DOG!”的全文检索:

上面这个查询返回四个文档,其中,文档 4 最相关,因为它包含词 "brown" 两次以及 "dog" 一次;文档 2、3 同时包含 brown 和 dog 各一次,而且它们 title 字段的长度相同,所以具有相同的评分;文档 1 也能匹配,尽管它只有 brown 没有 dog 。如图2-8所示:

此外,Elasticsearch还可以利用词的相似度(word proximity)、部分匹配(partial matching)以及语言感知(language awareness)进行搜索。
1.5 聚合
通过搜索,我们可以查询到与查询条件匹配的文档集合,例如,查询红色的小汽车。如果我们要分析和总结全套的数据集而不是寻找单个文档,就需要通过聚合,聚合会使我们会得到一个数据集的概览,例如,小汽车总共有哪些?汽车的平均价格是多少?按照汽车的品牌,汽车的平均销量是多少?聚合允许我们向数据提出一些复杂的问题,虽然功能完全不同于搜索,但是由于使用相同的数据结构,聚合的执行速度就像搜索一样快,几乎是实时的。
Elasticsearch聚合功能的实例很多,例如,汽车经销商可能会想知道哪个颜色的汽车销量最好,用聚合可以轻易得到结果,如图8-9所示:

其运行结果如图8-10所示,图中③代表汽车的颜色,④代表改颜色的汽车文档数量:

聚合和搜索可以一起使用,即对我们的查询结果数据进行聚合和分析,例如,我们可以显示满足查询条件的各颜色汽车销量。
2 参考文献
<< Elasticsearch Reference[6.2]>>
<< Elasticsearch: 权威指南>>
3 Elasticsearch部署
软件版本:
jdk1.8.0_144.tar.gz
elasticsearch-6.2.4.tar.gz
node-v8.11.1-linux-x64.tar.xz (安装elasticsearch-head时,需安装node)
elasticsearch-head-master.zip(https://github.com/mobz/elasticsearch-head)
1 安装JDK
2 安装Elasticsearch(单节点)
解压Elasticsearch压缩包,并对elasticsearch.yml文件进行修改
tar -zxvf elasticsearch-6.2.4.tar.gz
vi elasticsearch-6.2.4/config/elasticsearch.yml
内容修改如下:
cluster.name: es6.2
node.name: node-1
node.master: true
node.data: true
network.host: 0.0.0.0
因为elasticsearch不能使用root用户运行,创建一个es用户,并启动es
adduser es
chown -R es:es elasticsearch-6.2.4
su es
cd elasticsearch-6.2.4
./bin/elasticsearch
此时报错信息如下:
[2018-02-14T23:40:16,908][ERROR][o.e.b.Bootstrap ] [node-1] node validation exception
[4] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: max number of threads [1024] for user [elsearch] likely too low, increase to at least [4096]
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[4]: system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
[1]、[2] 解决办法:
vi /etc/security/limits.d/90-nproc.conf
修改配置如下:
* soft nproc 4096
root soft nproc unlimited
es soft nofile 65536
es hard nofile 65536
[3]解决办法:
vi /etc/sysctl.conf
添加如下配置:
vm.max_map_count = 262144
使配置生效
sysctl –p
[4]解决办法:
Centos 6.5不支持SecComp,而ES6.2.4默认bootstrap.system_call_filter为true, 在elasticsearch.yml增加如下配置:
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
启动ES
./bin/elasticsearch
使用http://IP:9200查看节点信息,若正常访问则表明服务启动成功
3 搭建集群
在elasticsearch.yml增加配置:
discovery.zen.ping.unicast.hosts: ["100.0.26.117", "100.0.26.118", "100.0.26.119"]
discovery.zen.minimum_master_nodes: 2
最终第一个节点的配置如下:
cluster.name: es6.2
node.name: node-1
node.master: true
node.data: true
network.host: 0.0.0.0
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
discovery.zen.ping.unicast.hosts: ["100.0.26.117", "100.0.26.118", "100.0.26.119"]
discovery.zen.minimum_master_nodes: 2
其他节点配置cluster.name必须一致且node.name不能一样,其他可以根据需求做改动。
启动各个节点
./bin/elasticsearch
控制台显示启动成功之后,访问http://IP:9200/_cat/nodes,若配置的节点都在,则集群部署成功,有问题则具体问题具体解决。
4 安装head插件
解压node-v8.11.1-linux-x64.tar.xz 之前确保系统已安装xz,若无则先安装
yum install xz
tar xvf node-v8.11.1-linux-x64.tar.xz
配置node环境变量
export JAVA_HOME=/home/soft/jdk1.8.0_144
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export NODE_PATH=/home/soft/node-v8.11.1-linux-x64
export PATH=$PATH:$JAVA_HOME/bin:$NODE_PATH/bin
source /etc/profile
下载head插件需要的依赖
cd /home/soft/elasticsearch-head-master
npm install
修改Gruntfile.js配置,在keepalive: true下增加hostname:'*'
vi Gruntfile.js
connect: {
server: {
options: {
port: 9100,
base: '.',
keepalive: true,
hostname: '*'
}
}
}
修改保存后启动head 服务
npm run start
浏览器打开http://head_IP:9100,此时发现页面能正常打开,但是提示集群健康值:未连接,这个问题需要修改ES配置导致
修改elasticsearch.yml,增加如下配置:
http.cors.enabled: true
http.cors.allow-origin: "*"
重启ES
再次浏览器打开http://head_IP:9100,显示还是未连接,如下图:

注意图片上用红框标注的,修改localhost为ES的IP地址,然后点击“连接”按钮。
4 Elasticsearch代码实例
4.1 Maven依赖
在maven工程中,pom.xml文件添加以下依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.1.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.1.1</version>
<scope>compile</scope>
</dependency>
注:具体的项目可根据本地Elasticsearch版本,替换pom文件中Elasticsearch jar版本
4.2 插入数据
通过ES客户端向ES插入数据的代码如下:
public void testSend2Es() throws Exception{
JSONObject dataObject=new JSONObject();
dataObject.put("FILE_TASK_ID", 1);
dataObject.put("ISVALID", 1);
String index=" stru_image_task ";
String type="doc";
HttpHost httpHost=new HttpHost("10.3.64.97",9200,"http");
RestClientBuilder restClientBuilder= RestClient.builder(httpHost);
//构造ES客户端
RestHighLevelClient client=new RestHighLevelClient(restClientBuilder);
try{
//发送数据
IndexRequest request = new IndexRequest(index,type).source(dataObject.toString(), XContentType.JSON);
IndexResponse indexResponse = client.index(request);
//解析发送结果
ReplicationResponse.ShardInfo shardInfo=indexResponse.getShardInfo();
if (shardInfo.getFailed() > 0) {
for (ReplicationResponse.ShardInfo.Failure failure : shardInfo.getFailures()) {
String reason = failure.reason();
logger.info("ES insert failure reason is :" + reason );
}
}
}catch (Exception e){
e.printStackTrace();
throw new MessageException(MessageException.UNDEFINED_EXCEPTION );
}finally {
//关闭客户端
try {
if (client != null) {
client.close();
}
} catch (IOException e) {
e.printStackTrace();
throw new MessageException(MessageException.UNDEFINED_EXCEPTION );
}
}
}
4.3 查询数据
通过ES客户端查询stru_image_task索引下的5条数据。
public void getDataFromEs2() throws Exception{
String index="stru_image_task";
String type="doc";
RestHighLevelClient client=null;
try{
HttpHost httpHost=new HttpHost("10.3.64.97",9200,"http");
RestClientBuilder restClientBuilder= RestClient.builder(httpHost);
//构造ES客户端
client=new RestHighLevelClient(restClientBuilder);
SearchRequest searchRequest = new SearchRequest(index);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//查询所有数据
//searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//按条件查询
BoolQueryBuilder boolQueryBuilder= QueryBuilders.boolQuery();
JSONObject queryItemJson1=new JSONObject();
queryItemJson1.put("filedName","SUB_TASK_ID");
queryItemJson1.put("filedValue",180910663969L);
JSONObject queryItemJson2=new JSONObject();
queryItemJson2.put("filedName","SUB_TASK_ID");
queryItemJson2.put("filedValue",180910661282L);
List<JSONObject> dataJsonList=new ArrayList<>();
dataJsonList.add(queryItemJson1);
dataJsonList.add(queryItemJson2);
for (int i=0;i<dataJsonList.size();i++){
JSONObject queryItem=(JSONObject)dataJsonList.get(i);
boolQueryBuilder.must(QueryBuilders.matchPhraseQuery(queryItem.getString("filedName"),queryItem.get("filedValue")));
}
searchSourceBuilder.query(boolQueryBuilder);
//查询数据量5条
searchSourceBuilder.size(5);
searchRequest.source(searchSourceBuilder );
SearchResponse searchResponse = client.search(searchRequest);
//解析查询结果,并将结果放入resultJsonList
Iterator<SearchHit> iterator=searchResponse.getHits().iterator();
List resultJsonList=new ArrayList<>();
while(iterator.hasNext()) {
SearchHit searchHitItem=iterator.next();
Map<String, Object> soureMap=searchHitItem.getSourceAsMap();
JSONObject resultItemJson=new JSONObject(soureMap);
resultJsonList.add(resultItemJson);
}
}catch (Exception e){
e.printStackTrace();
throw new MessageException(MessageException.UNDEFINED_EXCEPTION );
}finally {
try {
if (client != null) {
client.close();
}
} catch (IOException e) {
e.printStackTrace();
throw new MessageException(MessageException.UNDEFINED_EXCEPTION );
}
}
}
5 性能分析
Elasticsearch是现在主流的搜索引擎,支持PB级数据存储存储和拥有ms级的搜索响应时间,对于数据存储具有很好的可拓展性和较为优良的写入速度,对数据搜索效率更加高效、并支持多种搜索方式,但当频繁的更新索引_mapping时,对写入速度影响较大。
根据Elasticsearch特性,我们从Elasticsearch存储及查询两个方面进行实验论证,实验由8核 @3.40G Hz、8G内存的pc完成,每条Json数据由11KB xml文件生成,Elasticsearch版本为6。
5.1 论证过程
此处对Elasticsearch不同大小数据集的数据写入速度及磁盘占用进行实验对比,表为1百万条、1千万和5五千万条Json数据进行结果对比。
| 性能 数据量 | 1百万条Json | 1千万条Json | 5千万条Json |
| 磁盘占用 | 123MB | 1219MB | 6237MB |
| 数据写入速度 | 1.23百万条/小时 | 1.23百万条/小时 | 1.25百万条/小时 |
由于属性值种类数量不同,将导致结果集大小不同。此处对数据集中数据属性值种类不同进行实验对比,SubTagName属性为Json深层属性分,别将SubTagName属性值设为4种和1万多种, 数据集设为1千万条数据,其中实验从返回值数量和多属性搜索方面进行性能分析。
| 属性值种类(千万数据量) 响应时间 | 4种SubTagName | 1千万种SubTagName |
| 查询 SubTagDescript属性为cat目标总量的响应时间 | 10~15ms(12ms) | 10~15ms(12ms) |
| 查询 SubTagDescript属性为cat目标总量 并返回前5个目标的响应时间 | 20-40ms (30ms) | 12-25ms(18ms) |
| 查询 SubTagName属性为cat目标总量,并返回前500个目标的响应时间 | 40-78ms (58ms) | 30-53ms(40ms) |
| 查询parentID=51且 SubTagName属性为cat的目标总量的响应时间(两个属性同时搜索) | 10~25ms(18ms) | 14-25ms (20ms) |
此处对Elasticsearch不同大小数据集查询效率进行实验对比,SubTagDescript属性与SubTagName属性为Json深层属性,其中实验从返回值数量和多属性搜索方面进行性能分析,表为1千万和5五千万条Json数据对比结果。
| 响应时间 数据量 | 1千万条Json | 5千万条Json |
| 查询 SubTagDescript属性为cat目标总量的响应时间 | 10~15ms(12ms) | 10~18ms(15ms) |
| 查询 SubTagDescript属性为cat目标总量 并返回前5个目标的响应时间 | 12-25ms(18ms) | 12-35ms (20ms) |
| 查询 SubTagName属性为cat目标总量,并返回前500个目标的响应时间 | 30-53ms(40ms) | 40-65ms(56ms) |
| 查询 SubTagName属性为cat目标总量,并返回前1000个目标的响应时间 | 无 | 60-85ms (70ms) |
| 查询parentID=51、SubTagDescript为tricycle且 SubTagName属性为cat的目标总量的响应时间(三个属性同时搜索) | 13-27ms(20ms) | 15-35ms(22ms) |
此处对Elasticsearch通过不断插入有新属性(filed)的数据,使ES不断更新mapping和保存新数据,从而查看Elasticsearch的存储效率。实验分别在8G的pc和16G的服务器上进行,结果如表3.4所示:
| 性能 测试机型 | 8G的PC | 256G的服务器 |
| 插入效率 | 低于4000条/时 | 4000条/时 |
| 出现超时(30s)时,ES中的属性种类数量 | 2020种 | 8100种 |
| 出现超时(30s)时,ES中的数据数量 | 2353条 | 10615条 |
由实验可知,①当属性变动较小时,Elasticsearch的存储数据速度基本稳定,磁盘的占用量随数据集的大小呈线性增长。查询响应时间普遍为100ms以下,查询响应时间受返回结果集大小影响最大,其次查询到的结果集大小也会对响应时间有影响,其他情况对响应时间影响较小。②当属性频繁的增加时,Elasticsearch的存储数据速度很缓慢,随属性的增加,出现存储超时(30s)的概率增大。
5.2 结论
根据Elasticsearch特性及实验论证可知,Elasticsearch优点:当属性变动较小时,Elasticsearch对于数据的存储及查询都有良好的表现,由于Elasticsearch查询耗时是ms级的,Elasticsearch完全可以满足作为Hbase的二级索引,甚至可直接对海量数据的存储及查询。其不足之处:①当属性频繁的增加时,Elasticsearch的存储数据速度很缓慢,随属性的增加,出现存储超时(30s)的概率增大②当作为Hbase的二级索引时,会存在数据冗余问题,可将数据部分属性存入Elasticsearch,这样减少数据冗余同时并提高查询效率。根据Elasticsearch以上特性,我们应该通过划分索引等方式,使单个索引的属性种类在1000以内,避免属性过多导致的效率问题。
6 本章小结
HDFS具有高容错性、适合批量处理、适合大数据处理、流式文件访问等优点,但也有不适合低延迟数据访问、不适合小文件存取、不适合并发写入的问题。虽然Hive与Hbase底层都是基于HDFS进行数据存储,但它们的特点差别还是比较大的。Hive提供 HQL(Hive SQL)查询功能,将 SQL 语句转换为 MapReduce 任务运行,使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据,但是Hive查询效率很低,Hive 适合用来做海量离线数据统计分析以及日志分析,常常被用作数据仓库。Hbase是Hadoop生态圈中具有实时查询系统的组件,其具有随机写入、数据快速随机访问能力,Hbase在数据的实时查询效率上Hive和HDFS是无法与其相比的。
Elasticsearch 是一个开源的搜索引擎,其优秀的搜索效率是Hbase、Hive组件所不具有的。由于Elasticsearch拥有自己独有的数据存储方式,而非使用HDFS,故Elasticsearch不像Hbase、Hive可以与Hadoop生态圈组件完美的契合,Elasticsearch拓展性不如Hbase、Hive。由于Elasticsearch具有优秀的搜索功能,故Elasticsearch也常作为Hbase的二级索引使用。

















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









