




一、简述脉冲神经网络SNN:下一代神经网络 | 机器之心 (jiqizhixin.com)
- 每个峰值由代表生物过程的微分方程表示出来,其中最重要的是神经元的膜电位。本质上,一旦神经元达到了某一电位,脉冲就会出现,随后达到电位的神经元会被重置。
- 对此,最常见的模型是 Integrate-And-Fire(LIF)模型
- SNN通常是稀疏连接的
- 脉冲训练增强了我们处理时空数据(或“真实世界感官数据”)的能力。
- 空间:神经元仅与附近的神经元连接,这样他们可以分别处理输入块(类似于CNN使用滤波器)
- 时间:脉冲训练随着时间而发生,这样我们在二进制编码中丢失的信息可以在脉冲的时间信息中重新获取。这允许我们自然地处理时间数据,无需 RNN 添加额外的复杂度。
- SNN的训练:
- 尽管我们有无监督生物学习方法,如赫布学习(Hebbian learning)和 STDP,但没有适合 SNN 的有效监督训练方法能够通过提供优于第二代网络的性能。
- 由于脉冲训练不可微,我们无法在不损失准确时间信息的前提下使用梯度下降来训练 SNN。因此,为了正确地使用 SNN 解决真实世界任务,我们需要开发一种高效的监督学习方法。
- 在正常硬件上模拟SNN需要耗费大量算力,因为它需要模拟微分方程。神经形态硬件,如 IBM TrueNorth,旨在使用利用神经元脉冲行为的离散和稀疏本质的专门硬件模拟神经元,进而解决该问题
二、LIF模型:(附带lzhikevich model原理)
-
单个神经元的简单模型:Leaky integrate and fire (LIF) model
-
神经元建模需要考虑的三个基本方面:
-
应对不同输入电流的响应
-
噪声模型
-
对发放稳定性(CV,Coefficient of Variation,变异系数)
-
-

动作电位之后的不应期:在发放了一个动作电位之后: 神经元会位置在一个reset电位几毫秒-
LIF模型的数学阐述:
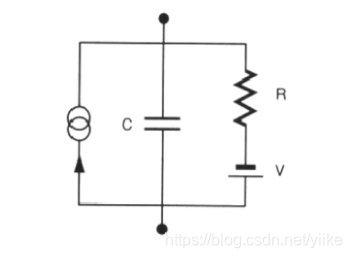
-
others:
-
电压关于时间求导:容量为1uF 的电容通过的电流
-
G L G_L GL、 E L E_L EL分别代表Leak的导纳,以及被动平衡的电压 (一般就是静息电位,-70mV)
- G L G_L GL 电导,定义是电阻的倒数
- E L E_L EL 被动平衡的电压
- 下标L:Leaky,泄露电流
-
电容 C m C_m Cm两侧是在测电流大小
-
动作电位:电流方向和正离子运动方向相同,神经元内电流方向从上个神经元的轴突,到下个神尽元的树突。
-
-
-
- 这篇帖子真牛逼!!!
- LIF模型(见上帖子笔记电路图)
-
4.1-Leaky Integrate-and-Fire (LIF) 模型
- IF模型,顾名思义,包含了以下三大特征:
- Leaky:存在欧姆漏电流。
- Integrate:一个能积累电流的部件,电容。
- Fire:当输入电流足够大的时候,膜电压会产生突变(spiking)
- 多么朴素的名字
- IF模型,顾名思义,包含了以下三大特征:
三、SNN实现
-
lzhikevich模型概述:
-
(3条消息) SNN、RNN、CNN_qq_29517403的博客-优快云博客
-
脉冲神经网络诞生的原因:
- 人工神经网络需要高性能的计算平台。
- 人工神经网络仍不能实现强人工智能,人们认为是因为其与生物大脑仍存在巨大差距。
-
SNNs的特点:
- 采用了生物神经元模型如IF,LIF等,比之前ANNs的神经元更接近生物。
- 信息的传递是基于脉冲进行。所以网络的输入要进行额外编码,例如频率编码和时间编码等,转现在的数据(例如图片的像素)转换成脉冲,编码技术我们以后再讨论。
- 基于脉冲的脉冲的编码,能蕴含更多的信息
- SNNs网络的能耗更低,每个神经元单独工作,部分神经元在没接受到输入时,将不会工作。
-
SNNs的学习算法
-
首先一点非常重要,脉冲神经网络不能直接利于ANNs的基于反向传播的方式进行网络训练,因为脉冲神经元模型处理的是信息是离散的脉冲,不能直接求导。
-
将现有的ANNs映射到SNNs中
这种方法是当前比较主流的构建SNNs的方法,因为它能有效的将ANNs与SNNs结合起来,利用了ANNs和SNNs各自的优点,ANNs训练简单,SNNs的能耗低。 -
SNNs转ANNs
对生物神经元模型进行处理,换成一个能求导的模型,或者对传递的脉冲信息进行转换。然后就可以将反向传播用于SNNs的训练。
-
STDP类的算法,它里面有很多小分支,STDP这东西就类似一种思想,例如两篇文章都用了STDP算法,但他们的数学公式可能是存在差异。从原理上,该种算法就是根据前后神经元的脉冲发放关系然后对他们之间的权重进行调整。该种算法比较接近人脑,现在研究他的人比较多。但这种算法一般是无监督的(也有少部分人将其改成有的监督),收敛比较难。(之前看过相关论文,感觉它是几种算法中最接近生物的学习规则)
-
-

















 9496
9496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









