



 BLIP是一个创新的视觉语言预训练框架,设计用于灵活适应各种视觉语言理解和生成任务。它使用字幕生成器处理网络噪声数据,并通过过滤器去除不准确信息。预训练的多模态、编码-解码模型在text-image检索、图像captioning、视觉问题解答、视觉推理和视觉对话等任务中表现出色。
BLIP是一个创新的视觉语言预训练框架,设计用于灵活适应各种视觉语言理解和生成任务。它使用字幕生成器处理网络噪声数据,并通过过滤器去除不准确信息。预训练的多模态、编码-解码模型在text-image检索、图像captioning、视觉问题解答、视觉推理和视觉对话等任务中表现出色。
提出BLIP,一种新的Vision-language pre-training (VLP)框架,可以灵活地转换到视觉语言理解和生成任务。
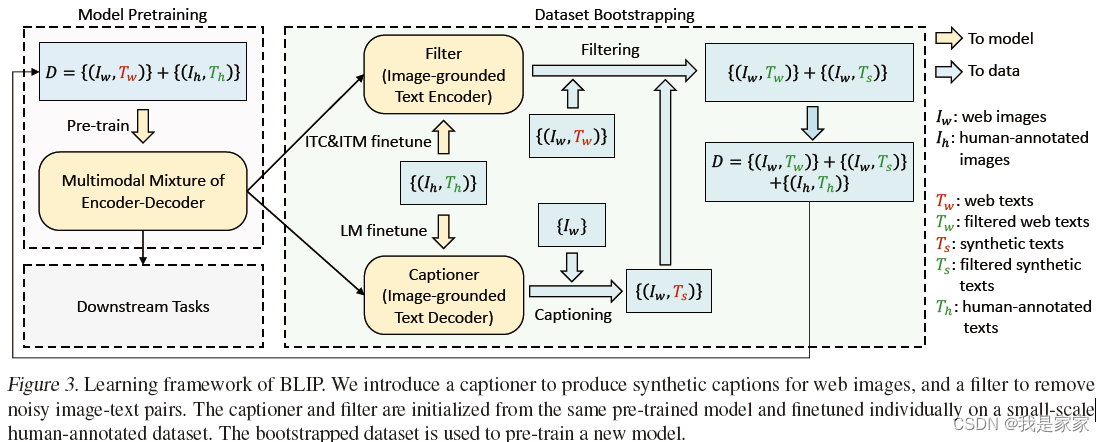
BLIP通过引导字幕有效地利用有噪声的网络数据,其中字幕生成器生成合成字幕,过滤器去除有噪声的字幕。
BLIP在很多视觉-语言任务上取得了很好地性能,例如:text-image retrieval, image captioning, visual quation answering, visual reasoning and visual dialog.
为了预训练一个统一的模型,同时具有理解和生成能力,提出编码-解码的多模态混合的多任务模型。
网络框架:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









