







 本文详细介绍了Hadoop的起源、架构及其分布式文件系统HDFS,涵盖了Hadoop的环境搭建、存储路径修改、免密操作等内容,并提供了通过Web界面和Java操作HDFS的示例。
本文详细介绍了Hadoop的起源、架构及其分布式文件系统HDFS,涵盖了Hadoop的环境搭建、存储路径修改、免密操作等内容,并提供了通过Web界面和Java操作HDFS的示例。
目录:
- Hadoop简介
- Hadoop架构
- Hadoop目录说明
- Hadoop文件系统HDFS介绍
- Hadoop环境搭建:伪分布式模式
- Hadoop修改存储路径和免密
- web界面访问HDFS与java操作HDFS
一.Hadoop简介
请参考自己下载的Hadoop版本对应的文档:Hadoop快速入门中文文档
1.Hadoop的由来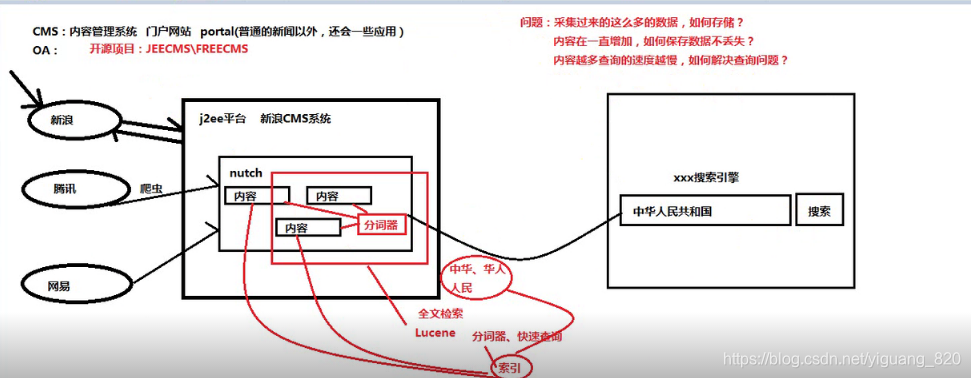
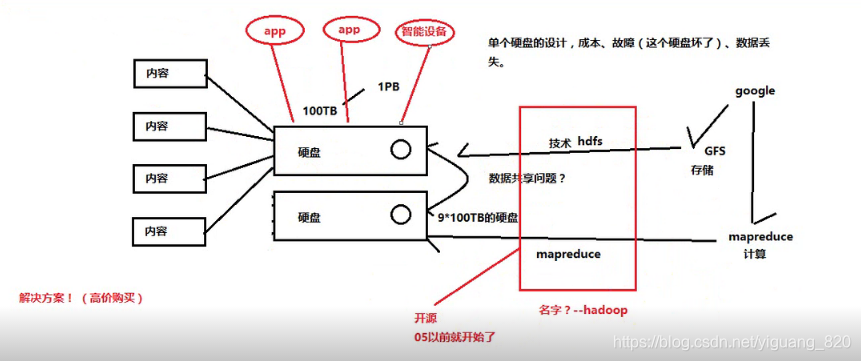
硬盘和服务器的关系:一个服务器可以有多个硬盘,就像抽屉一样,拉开一个个抽屉,将硬盘放进去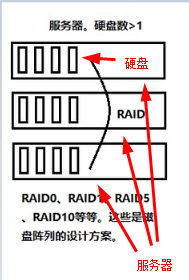
2.简介
- 官网:http://hadoop.apache.org/
- Hadoop是一个分布式系统基础架构,有Apache基金会开发。用户可以不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。
- Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了储存,MapReduce为海量的数据提供了计算。
- Hadoop可运行于一般的商用服务器上,具有高容错、高可靠性、高扩展性等特点
特别适合写一次,读多次的场景 - 适合
- 大规模数据
- 流式数据(写一次,读多次)
- 商用硬件(一般硬件)
- 不适合
- 低延时的数据访问
- 大量的小文件
- 频繁修改文件(基本就是写1次)
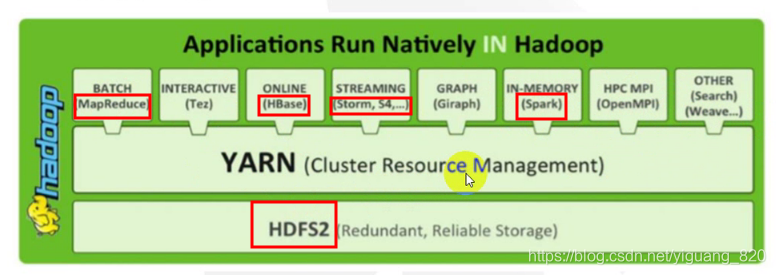
二.Hadoop架构
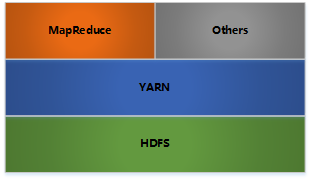
- HDFS: 分布式文件存储
- YARN: 分布式资源管理
- MapReduce: 分布式计算
- Others: 利用YARN的资源管理功能实现其他的数据处理方式
-
内部各个节点基本都是采用Master-Woker架构
三.Hadoop目录说明
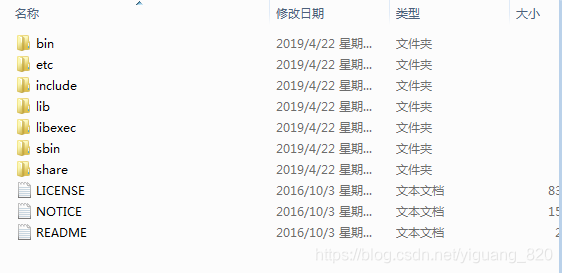
- bin:Hadoop最基本的管理脚本和使用脚本,这些脚本是sbin目录下管理脚本的基础实现,用户可以用这些脚本管理和使用Hadoop。
- etc:Hadoop配置文件所在的目录,包括core-site.xml、hdfs-site.xml、mapred-site.xml等从Hadoop1.0继承而来的配置文件和yarn-site.xml等Hadoop2.0新增的文件。
- include:对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是C++定义的,通常用于C++程序访问HDFS或者变成MR程序。
- lib:该目录提供了对外编程的静态库和动态库,与include目录下的头文件结合使用。
- libexec:各个服务所对应你的shell配置文件所在目录,可用于配置日志输出目录、启动参数(比如JVM参数)等基本信息。
- sbin:Hadoop管理脚本所在目录,主要包括HDFS和YARN中各类服务的启动/关闭脚本。
- share:Hadoop各个模块编译后的jar包所在目录。
四.HDFS介绍
1.Hadoop和HDFS的关系:
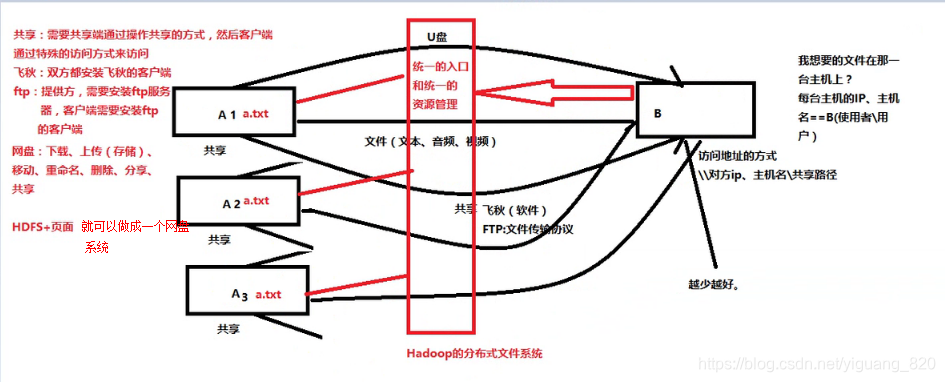
- HDFS(Hadoop Distributed File System)Hadoop分布式文件系统
- 对外部客户机而言,HDFS就像一个传统的分组文件系统,可以创建、删除、移动或重命名文件等等。很多时候,我们就叫它DFS(Distributed File System)
五.Hadoop环境搭建
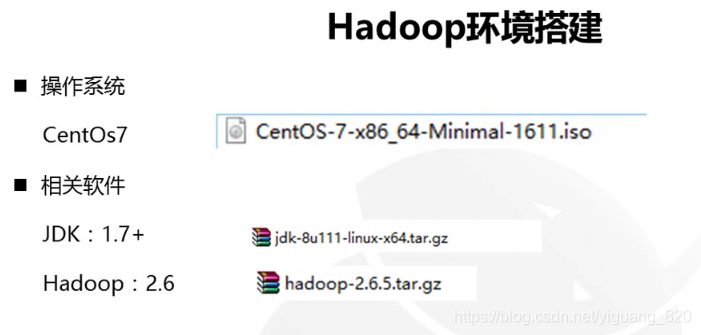
步骤:
- 安装虚拟机
- 安装jdk

- 安装Hadoop
- Hadoop的安装模式
- 单节点安装
所有服务运行在一个JVM中,适合调试、单元测试。
只能本地电脑使用,外部人不能使用。 - 伪集群
所有服务运行在一台机器中,每个服务都在独立的JVM中,适合做简单、抽样测试。
可以对外提供入口、出口地址,外部的人可以通过这个配置访问hadoop,但是只有一台服务器。所有的服务全部都在一台服务器当中。 - 多节点集群
服务运行在不同的机器中,适合生产环境。
需要提供一个入口、出口地址。但是有多台服务器同时存在。服务可以分布到各台主机上。外部的人,也是通过统一的配置来访问。 - 问题:地址,我们在进行web项目测试的时候,比如:http://192.168.200.10:8080 这就是一个地址,它由
http:协议,192.168.200.10 ip,8080:端口 组成,那么hadoop所需要提供的地址是怎么样的呢?
hadoop的地址:hdfs://主机名:9000 (一定是主机名,而不是ip,具体见hadoop安装的3.2配制Hadoop的入口和出口)
- 单节点安装
- Hadoop安装(linux下安装)
- 上传tar.gz的文件
- 解压
- 配置
- 第一步:关联jdk

- 第二步:配置hadoop的入口、出口

- 第三步:设置hdfs的副本数

什么是副本: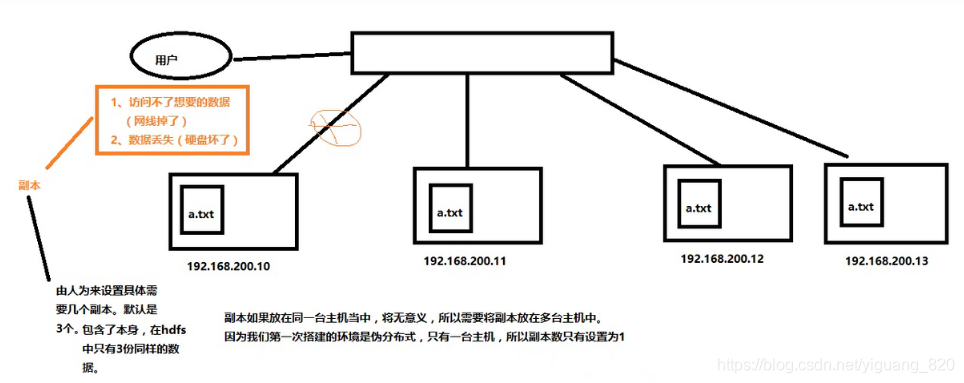
- 第一步:关联jdk
- 第四步:启动
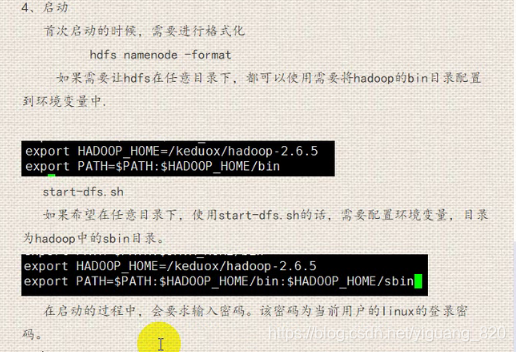
- Hadoop的安装模式
六.Hadoop修改存储路径和免密
- 修改储存路径

- 设置免密
- 免密的原因

- 加密分类
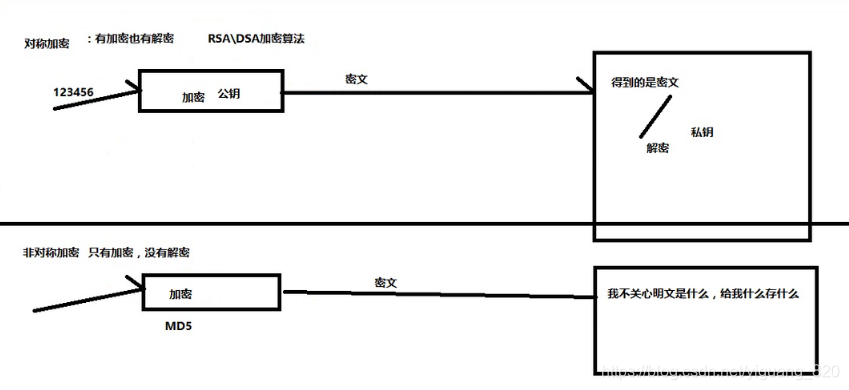
- 免密操作

- 实例
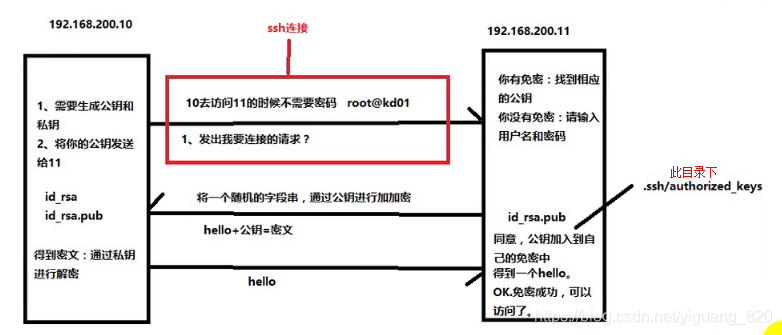
- 免密的原因
七.界面访问hdfs与java操作HDFS
1.web界面访问hdfs
2.Java操作HDFS :
示例:Java 将 hdfs:192.168.200.10:9000/user/yiguang/aaa.txt,复制存储在windows中e:/
- 在HDFS中创建目录user/yiguang/,并在其目录下创建文件aaa.txt
#第一步:在hdfs中创建文件目录/user/yiguang [root@kd01 ~]# hdfs dfs -mkdir /user [root@kd01 ~]# hdfs dfs -mkdir /user/yiguang #第二步:创建/test/aaa.txt文件,写入的内容为:我们一起学习hadoop。 [root@kd01 test]# touch aaa.txt [root@kd01 /]# hdfs dfs -cat /aaa.txt 我们一起学习hadoop。 #第三步:将aaa.txt上传到hdfs中 [root@kd01 /]# hdfs dfs -put /test/aaa.txt hdfs://kd01:9000/user/yiguang/ - 创建maven项目
- 加入以下pom依赖:注意版本对应
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.3</version> </dependency> </dependencies> - 编写代码
package test; import java.io.FileOutputStream; import java.io.IOException; import java.net.URI; import org.apache.commons.compress.utils.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class HadoopTest { public static void main(String[] args) throws IOException { //1.连接 FileSystem fs=FileSystem.get(URI.create("hdfs://192.168.200.10:9000"), new Configuration()); //2.拿数据 FSDataInputStream fsd=fs.open(new Path("/user/yiguang/aaa.txt")); //3.处理 FileOutputStream fos=new FileOutputStream("e://bbb.txt"); //4.提供了一个工具类 IOUtils.copy(fsd, fos ,4096); //5.关闭 fos.close(); fsd.close(); fs.close(); } } - 运行,查看
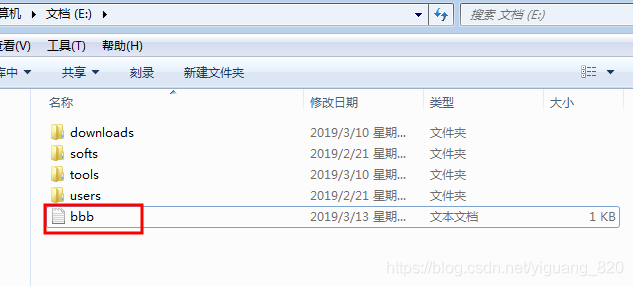
注意:问题补充:在上述内容操作过程中需要注意的问题


















 1887
1887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









