







一.java.util包下的集合类
1.Java集合四大接口

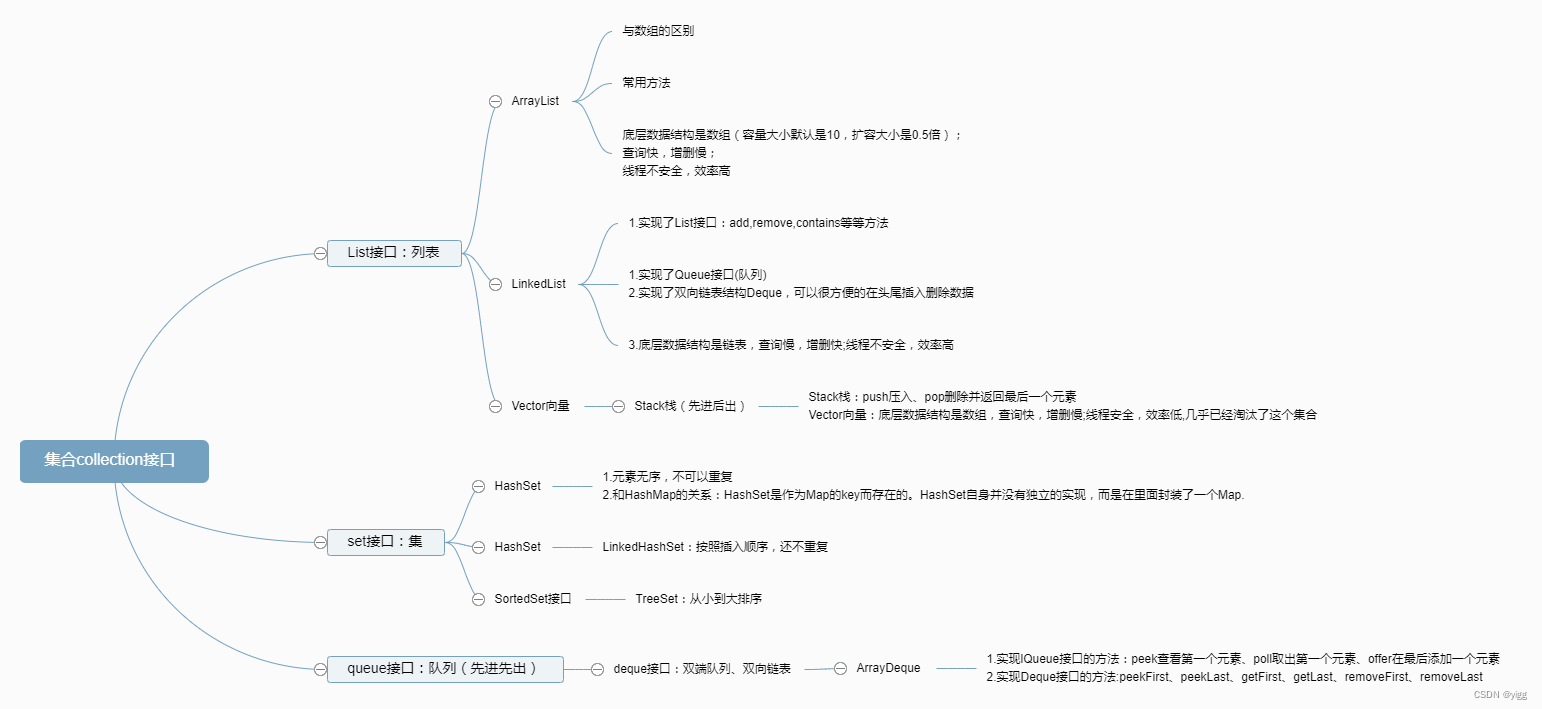
2.Collection接口
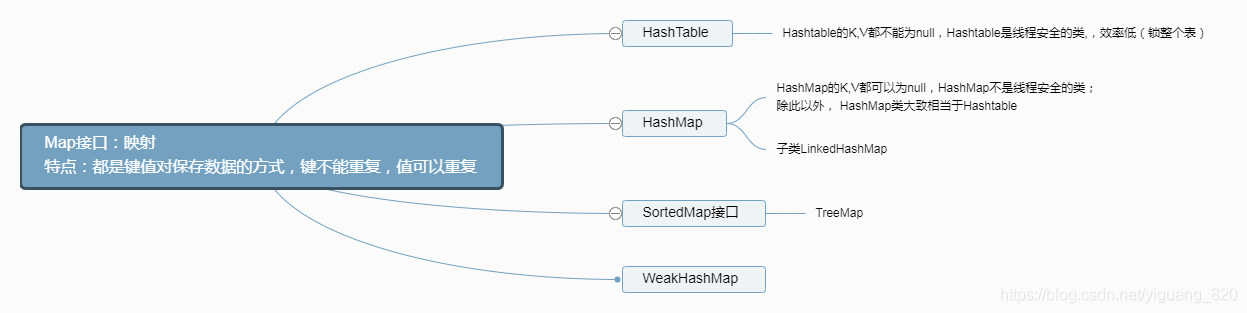
3.map接口
二.java.concurrent包下线程安全的集合类

三.常见考察点
- Java集合框架是什么?说出一些集合框架的优点?
每种编程语言中都有集合,最初的Java版本包含几种集合类:Vector、Stack、HashTable和Array。随着集合的广泛使用,Java1.2提出了囊括所有集合接口、实现和算法的集合框架。在保证线程安全的情况下使用泛型和并发集合类,Java已经经历了很久。它还包括在Java并发包中,阻塞接口以及它们的实现。集合框架的部分优点如下:- 使用核心集合类降低开发成本,而非实现我们自己的集合类。
- 随着使用经过严格测试的集合框架类,代码质量会得到提高。
- 通过使用JDK附带的集合类,可以降低代码维护成本。
- 复用性和可操作性。
- 泛型有什么优点?
泛型大多使用在集合类中,也只有使用在集合类中才有意义
接口是泛型;比如:List接口、Set接口、Queue接口、Deque接口
类使用泛型;比如:ArrayList、HashSet、Vector、Stack、
方法使用泛型;比如:排序方法中Collections.sort()
Java1.5引入了泛型,所有的集合接口和实现都大量地使用它。泛型允许我们为集合提供一个可以容纳的对象类型。 - Java集合框架的基础接口有哪些?
- Collection为集合层级的根接口。一个集合代表一组对象,这些对象即为它的元素。Java平台不提供这个接口任何直接的实现。
- Set是一个不能包含重复元素的集合。这个接口对数学集合抽象进行建模,被用来代表集合,就如一副牌。
- List是一个有序集合,可以包含重复元素。你可以通过它的索引来访问任何元素。List更像长度动态变换的数组。
- Map是一个将key映射到value的对象.一个Map不能包含重复的key:每个key最多只能映射一个value。
- 一些其它的接口有Queue、Dequeue、SortedSet、SortedMap和ListIterator。
- Comparable接口和Comparator接口有何区别?
- Comparable和Comparator接口被用来对对象集合或者数组进行排序。
- Comparable接口被用来提供对象的自然排序,我们可以使用它来提供基于单个逻辑的排序,实现此接口的类可以使用comparaTo方法,对排序有很大的帮助
- Comparator接口被用来提供不同的排序算法,我们可以选择需要使用的Comparator来对给定的对象集合进行排序。
例如:如果集合中的对象有多个作为参考的排序的属性(比如英雄的属性有血量和伤害,即可以根据伤害,又可以根据血量排序),那么可以使用Comparator来实现自己的需要来使用哪个属性作为参考排序。
- Iterator是什么?
Iterable是什么? - Enumeration和Iterator接口的区别?
Enumeration的速度是Iterator的两倍,也使用更少的内存。Enumeration是非常基础的,也满足了基础的需要。但是,与Enumeration相比,Iterator更加安全,因为当一个集合正在被遍历的时候,它会阻止其它线程去修改集合。
迭代器取代了Java集合框架中的Enumeration。迭代器允许调用者从集合中移除元素,而Enumeration不能做到。为了使它的功能更加清晰,迭代器方法名已经经过改善。 - Iterater和ListIterator之间有什么区别?
- 我们可以使用Iterator来遍历Set和List集合,而ListIterator只能遍历List。
- Iterator只可以向前遍历,而LIstIterator可以双向遍历。
- ListIterator从Iterator接口继承,然后添加了一些额外的功能,比如添加一个元素、替换一个元素、获取前面或后面元素的索引位置。
- 为何Iterator接口没有具体的实现?
Iterator接口定义了遍历集合的方法,但它的实现则是集合实现类的责任。每个能够返回用于遍历的Iterator的集合类都有它自己的Iterator实现内部类。
这就允许集合类去选择迭代器是fail-fast还是fail-safe的。比如,ArrayList迭代器是fail-fast的,而CopyOnWriteArrayList迭代器是fail-safe的。 - 集合系列之fail-fast 与fail-safe 区别
快速失败(fail—fast)
在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
场景:Java.util包中的所有集合类都被设计为fail-fast的,Collection中所有Iterator的实现都是按fail-fast来设计的。
安全失败(fail—safe)
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception。
缺点:基于拷贝内容的优点是避免了Concurrent Modification Exception,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
场景:java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。 - Collection和Collections的区别
- java.util.Collection 是一个集合接口,它是Set、List等容器的父接口.
- java.util.Collections 是针对集合类的一个工具类,它提供了一系列的静态方法实现对各种集合的搜索、排序、线程安全化等操作。
- Collections工具类中的sort()方法如何比较元素?
Collections工具类的sort方法有两种重载的形式,
第一种要求传入的待排序容器中存放的对象比较实现Comparable接口以实现元素的比较;
第二种不强制性的要求容器中的元素必须可比较,但是要求传入第二个参数,参数是Comparator接口的子类型(需要重写compare方法实现元素的比较),相当于一个临时定义的排序规则,其实就是通过接口注入比较元素大小的算法,也是对回调模式的应用(Java中对函数式编程的支持)。 - 什么是工具类?怎么使用?有哪些常用的工具类?
- 集合中有Arrays、Collections工具类
命名方式上大多以util结尾
时间工具类TimeUnit时间粒度
在spring中jdbcTemplate工具类、java使用redis的时候使用redisTemplate(RedisUtil 工具类,封装了 RedisTemplate 这个类)两者的使用方式一致 - 哪些集合类提供对元素的随机访问?
ArrayList、HashMap、TreeMap和HashTable类提供对元素的随机访问。 -
List
- 实现List接口的有哪些?
ArrayList、linkedlist、vector向量、stack栈也叫堆栈 - 如何实现数组和 List 之间的转换?
- 数组转 List:使用 Arrays. asList(array) 进行转换。
- List 转数组:使用 List 自带的 toArray() 方法。
- 遍历一个List有哪些不同的方式?
- 使用for 循环、使用加强 for 循环
- 使用迭代器iterator
使用迭代器更加线程安全,因为它可以确保,在当前遍历的集合元素被更改的时候,它会抛出ConcurrentModificationException。
- 什么是链表?有什么特点?什么是双向链表?
什么是链表结构: 与数组结构相比较,数组结构,就好像是电影院,每个位置都有标示,每个位置之间的间隔都是一样的。 而链表就相当于佛珠,每个珠子,只连接前一个和后一个,不用关心除此之外的其他佛珠在哪里。
双向链表结构Deque,可以很方便的在头尾插入删除数据 - Array和ArrayList有何区别?什么时候更适合用Array?
- Array是指定大小的,而ArrayList大小是固定的。
- Array可以容纳基本类型和对象,而ArrayList只能容纳对象。
- 使用Array的情况:
- 如果列表的大小已经指定,大部分情况下是存储和遍历它们。
- 如果你要使用多维数组,使用[][]比List<List<>>更容易。
- 对于遍历基本数据类型,尽管Collections使用自动装箱来减轻编码任务,在指定大小的基本类型的列表上工作也会变得很慢。
- 使用ArrayList:Array没有提供ArrayList那么多功能,比如addAll、removeAll和iterator等。尽管ArrayList明显是更好的选择,但也有些时候Array比较好用。
-
- ArrayList与Vector的差别
- 相同点:
- 这两个类都实现了List接口(List接口继承自Collection接口),它们都是有序集合。
- 两者都是基于索引的,内部由一个数组支持。
- ArrayList和Vector两者允许null值和重复值,也可以使用索引值对元素进行随机访问。
- ArrayList和Vector的迭代器实现都是fail-fast的。
- 两者维护插入的顺序,我们可以根据插入顺序来获取元素。
- 它们两个的差别在于:
- 数据增长的问题:ArrayList和Vector都有一个初始的容量大小,当存储进去它们里面的元素个数超出容量的时候。就须要添加ArrayList和Vector的存储空间,每次添加存储空间的时候不是仅仅添加一个存储单元。是添加多个存储单元。Vector默认添加原来的一倍,ArrayList默认添加原来的0.5倍。Vector能够由我们自己来设置增长的大小,ArrayList没有提供相关的方法。
- 线程安全的问题:Vector是早期Java就有的,允许多线程操作。是线程安全的;而ArrayList是在Java2中才出现,它是线程不安全的,仅仅能使用单线程操作。
因为Vector支持多线程操作,所以在性能上就比不上ArrayList了。
相同的HashTable相比于HashMap也是支持多线程的操作而导致性能不如HashMap。
- 相同点:
- LinkedList与ArrayList有什么差别
- 两者都实现的是List接口。
- 不同之处在于:
- ArrayList是基于动态数组实现的,LinkedList是基于链表的数据结构。
- ArrayList是顺序结构,所以定位很快,指哪找哪。 就像电影院位置一样,有了电影票,一下就找到位置了。LinkedList 是链表结构,就像手里的一串佛珠,要找出第99个佛珠,必须得一个一个的数过去,所以定位慢
- ArrayList 修改,查找数据快,get訪问List内部随意元素时。ArrayList的性能要比LinkedList性能好。
- LinkedList 插入,删除数据快,LinkedList中的get方法是要依照顺序从列表的一端開始检查,直到还有一端
- LinkedList比ArrayList消耗更多的内存,因为LinkedList中的每个节点存储了前后节点的引用。
- 阐述ArrayList、Vector、LinkedList的存储性能和特性。
- ArrayList 和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector中的方法由于添加了synchronized修饰,因此Vector是线程安全的容器,但性能上较ArrayList差,因此已经是Java中的遗留容器。
- LinkedList使用双向链表实现存储(将内存中零散的内存单元通过附加的引用关联起来,形成一个可以按序号索引的线性结构,这种链式存储方式与数组的连续存储方式相比,内存的利用率更高),按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
- Vector属于遗留容器(Java早期的版本中提供的容器,除此之外,Hashtable、Dictionary、BitSet、Stack、Properties都是遗留容器),已经不推荐使用,但是由于ArrayList和LinkedListed都是非线程安全的,如果遇到多个线程操作同一个容器的场景,则可以通过工具类Collections中的synchronizedList方法将其转换成线程安全的容器后再使用(这是对装潢模式的应用,将已有对象传入另一个类的构造器中创建新的对象来增强实现)。
-
set
- 实现set接口的有哪些?
hashset、linkedHashSet(按顺序插入)、treeset(按大小插入) - HashSet实现原理
对于HashSet而言,它是基于HashMap实现的,HashSet底层使用HashMap来保存所有元素。
值作为K,new object()对象作用V添加到HashMap中。所以k相同,v一定相同。这样就保证了元素不重复。
在到HashMap源码中看看是怎么插入元素的。
-
Map
- 实现map接口的有哪些?
hashmap、hashtable、linkedHashMap、treemap - 为什么Hashtable, ConcurrentHashMap 的 key和value 不能为null(并发角度分析)?而HashMap却可以?
- HashMap在高并发的情况下,会出现扩容问题,在高并发下如果两个线程同时扩容,都是在自己的线程中创建数组和转移数组就会出现问题。
- jdk1.7 HashMap的实现
数组+链表实现。使用Entry对象保存键值对。
对于HashMap,最常用使用的两个方法是:Put和Get。- put方法
新来的节点插入链表时,使用的是“头插法“,(是因为HashMap的发明者认为,后插入的Entry被查找的可能性更大)。
如果没有达到就创建一个新的结点插入;否则先扩容再插入。 - get:当通过传递key调用get方法时,它再次使用哈希算法来找到数组中的索引,然后使用equals()方法找出正确的Entry,然后返回它的值。
- 扩容:其它关于HashMap比较重要的问题是容量、负荷系数和阀值调整。
HashMap默认的初始容量是16,意思是可以储存16个Entry,负荷系数是0.75。阀值是为负荷系数乘以容量,无论何时我们尝试添加一个Entry,如果map的大小比阀值大的时候,HashMap会对map的内容进行重新哈希,且使用更大的容量。容量总是2的幂(可以保证key均匀分布),所以如果你知道你需要存储大量的key-value对,比如缓存从数据库里面拉取的数据,使用正确的容量和负荷系数对HashMap进行初始化是个不错的做法。
注意:hashmap的hash()方法不是采用取模运算,而是采用位运算
1.7扩容的步骤:- 创建一个2倍当前容量的新数组(是容量,不是size大小)
- 把原来数组中的元素重新hash放到新数组中
- 安全问题
jdk1.7HashMap安全问题,一.不是线程安全,二在并发的情况下,在扩容的时候会造成链表成环,注意在添加新元素的时候采用头插入法,所以在扩容的时候如果数组中某个链表中的节点重新hash后相同,那么会将链表翻转。具体为如线程一将key重hash的时候会将链表翻转,最后一个Entry已经到了最前面,指向旧table的倒数第二个Entry,线程二在线程一翻转前执行到了Entry<key,value> next = e.next;第一个指向了第二个。也就是第一个和第二个互相next,导致成环。总结就是数组是固定长度,链表太长就需要扩充数组长度进行rehash减少链表长度。如果两个线程同时触发扩容,在移动节点时会导致一个链表中的2个节点相互引用,从而生成环链表。 成环原因 多线程 扩容 rehash后必须相等 链表成环:https://blog.youkuaiyun.com/someone77/article/details/108087633、https://blog.youkuaiyun.com/weixin_38732825/article/details/104929759
- put方法
- jdk1.8 HashMap的实现
HashMap是使用Node数组+链表+红黑树的数据结构来实现。
(1.所以HashMap有个静态成员内部类Node用来保存结点,和红黑树的构建过程是一样的)
(2.当链表的长度超过8的时候就会转化为红黑树(不一定)。在多并发的情况下也不会像jdk1.7中的hashmap会产生链表环。)- put()方法
- 第一步:对key调用哈希方法(先求哈希码,在进行移位运算)得出哈希值,再与table的长度-1进行与运算,也即是其对应Node数组的索引(简单说就是哈希桶 )
- 第二步:如果Node数组是否为空
- 如果是空,直接作为对应哈希桶的头结点。
- 如果不为空,则找到对应哈希桶的链表,通过equels()方法比较key与桶内的链表其它节点的K是否相等
- 相等,再通过equels方法比较V值,如果也相同,就直接返回V值;如果不相等,那就覆盖V值,再返回
- 不相等,那就先插入到尾部,当链表的长度超过8的时候就会转化为红黑树(不一定)
- 第三步:再看是否达到了扩容的要求,达到了就扩容。
扩容的要求:HashMap默认的初始容量是16,意思是可以储存16个Entry,负荷系数是0.75。
扩容的步骤:先插入然后再扩容- 创建一个2倍当前容量的新数组(将原容量值<<1(相当于*2)赋值给 newCap)
- 把原来数组中的元素重新放到新数组中,不需要重新hash。只需要看看原来的hash值和旧表table的容量的二进制进行&运算,只需要看结果是不是0,如果是0的话表示索引没有变,是1的话表示索引变成“oldCap+原索引”,这样即省去了重新计算hash值的时间,并且扩容后链表元素位置不会倒置。
- 相对于1.7哪些地方得到了改进
- 加入了红黑树,查找效率更高了
- 扩容后不用重新hash了。
- 问题:为什么扩容的容量都是2的幂次方?
因为经过扩容后的原结点的哈希桶会根据容量的大小发生变化(也是跟2有关,是经过一系列移位运算得来的),然后均匀分布在所有的哈希桶中,时间和空间都是最优的。
- put()方法
- jdk1.8 HashMap的源码
测试代码:public class Test1 { public static void main(String[] args) throws InterruptedException { Map<String,Object> map = new HashMap<String,Object>(); System.out.println(1); map.put("aa", "1"); System.out.println(2); map.put("bb", "2"); System.out.println(3); map.put("cc", "3"); System.out.println(4); map.put("dd", "4"); System.out.println(5); map.put("ee", "5"); System.out.println(6); map.put("ff", "6"); System.out.println(7); map.put("gg", "7"); System.out.println(8); map.put("hh", "8"); System.out.println(9); System.out.println("会扩容,数据放入后才考虑扩容"); map.put("ii", "9"); System.out.println(10); System.out.println("会扩容,数据放入后才考虑扩容"); map.put("jj", "10"); System.out.println(11); map.put("kk", "11"); System.out.println(12); map.put("ll", "12"); System.out.println(13); map.put("mm", "13"); System.out.println(14); map.put("nn", "14"); System.out.println(15); map.put("oo", "15"); System.out.println(16); map.put("pp", "16"); System.out.println(17); map.put("qq", "17"); System.out.println(18); map.put("rr", "18"); System.out.println(19); map.put("ss", "19"); System.out.println(20); map.put("tt", "20"); System.out.println("over"); } } put()方法 1.数组长度初始化为16,阈(yu)值为12 2.put数据 3.如果数组的node节点个数大于阈值就扩容 4.如果node节点个数不大于阈值,但是某个链的数据等于8时 5.当第九个节点进来时,先放在链的末尾; 再进行判断,如果链的长度大于8(扩容或者链转tree) 1.如果节点数组的长度小于64(树的最小容量)就扩容 1.创建一个节点数组old指向原节点数组table 2.新容量为old容量的2倍(32) 3.新边界值也为原边界值的2倍(24) 4.创建一个新的结点数组new,容量为新容量值 5.table指向new(也就是空的) 6.将old数组数据放到新table中(可能这九个节点还是在同一个数组的槽中,那么这个链的长度是9,所以存在一个链的长度大于8) 7.返回table 2.如果节点数据的长度大于或等于64,那就不扩容,直接将链表转为tree 结果:放在数组的第一个node中,链表长度为9了.aa->bb->cc->dd->ee->ff->gg->hh->ii 6.插入第10个节点 1.一直遍历到链表的最后一个结点,然后将新节点先放在链的末尾; 2.再进行判断,如果链的长度大于8,(扩容或者链转tree) 3.同上,节点数组的长度小于64,需要扩容 1.创建一个节点数组old指向原节点数组table,如同将old复制了一份旧数组table 2.新容量为old容量的2倍(64) 3.新边界值也为原边界值的2倍(48) 4.创建一个新的结点数组new,容量为新容量值,也就是table为新数组 5.table指向new(也就是空的) 6.将old数组数据放到新table中(可能这九个节点还是在同一个数组的槽中,那么这个链的长度是9,所以存在一个链的长度大于8) 7.返回table 结果:数组的第一个node的链表为bb->dd->ff->hh->jj,一共5节点,第33node的链表为aa->cc->ee->gg-ii,一共5个节点 7.插入第11个节点,kk 结果:数组的第一个node的链表为bb->dd->ff->hh->jj,一共5节点,第33node的链表为aa->cc->ee->gg-ii->kk,一共6个节点 8.插入第12个节点 9.插入节点...... 10.插入第16个节点:pp 结果:数组的第一个node的链表为bb->dd->ff->hh->jj->ll->nn->pp,一共8节点,第33node的链表为aa->cc->ee->gg-ii->kk->mm->oo,一共8个节点 11.在put第17个数据:qq 的时候,会将链表转为真正的tree(真正的转了,也没有扩容操作) 结果:第33个(数组为32)的node的链表转为tree 问题1:hash函数 HashMap中的hash函数:https://www.cnblogs.com/zhengwang/p/8136164.html static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } 第一步:key求hashcode,是一个int值 第二步:将第一步的值无符号右移16位,那么只剩下高位(相对而言)了 第三步:将第一步和第二步的结果进行异或运算,低位与高位异或,那么这两部分都利用起来了,hash冲突的概率降低了 (n - 1) & hash 第四步:然后再将hash值与table的长度-1进行&运算,那么值一定小于等于n-1,那么也就一定落在table数组中 问题2:扩容数据如何填充? if (oldTab != null) { // 遍历旧table数组的所有Node<K,V> for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); // Node<K,V>属于数组走下面流程 else { // preserve order // 不需要重新计算的链表 Node<K,V> loHead = null, loTail = null; // 需要重新计算的新链表 Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; // 将元素的hash值与旧表的容量进行与运算,会将旧链表的数据保持不变或者放到两个链表中,一个旧的,一个新的。(比如put第9个数据"ii",扩容后,旧链表还是还是一个链表中;而put第10个数据"jj",扩容后,旧链表的数据就放到两个链表中了) // 例.当数组扩容到64时,旧数组长度为32,二进制为100000。 // "aa"的hash值为3104,二进制为110000100000,进行&运算,为1,放到新链表 // "bb"的hash值为3136,二进制为110001000000,进行&运算,为0,放到旧链表 // "cc"的hash值为3168,二进制为110001100000,进行&运算,为1,放到新链表 // "dd"的hash值为3200,二进制为110010000000,进行&运算,为0,放到旧链表 // "ee"的hash值为3232,二进制为110010100000,进行&运算,为1,放到新链表 // ...... // 最后旧链表的在新table数组的index位置不变,新链表的index为旧链表的index+旧table数组的长度 if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } 问题3:链表如何转红黑树? 问题4:为什么用红黑树,而不用二叉查找树、b树、b+树? 红黑树是变体平衡的二叉查找树,相对于二叉查找树而言,它是相对平衡的,查找效率要比二叉查找树高。 相对于b树、b+树来说,b树、b+树应用于索引文件存储,存储在硬盘中,高度不宜太高,一般是4到5层,以免产生过多的io;而红黑树就没有这个限制,在内存中使用,查找效率更高 总结1:源码分析:https://blog.youkuaiyun.com/Palpitate_fx/article/details/123768423 - Map接口提供了哪些不同的集合视图?3种
- Set keyset():返回map中包含的所有key的一个Set视图。集合是受map支持的,map的变化会在集合中反映出来,反之亦然。当一个迭代器正在遍历一个集合时,若map被修改了(除迭代器自身的移除操作以外),迭代器的结果会变为未定义。集合支持通过Iterator的Remove、Set.remove、removeAll、retainAll和clear操作进行元素移除,从map中移除对应的映射。它不支持add和addAll操作。
- Collection values():返回一个map中包含的所有value的一个Collection视图。这个collection受map支持的,map的变化会在collection中反映出来,反之亦然。当一个迭代器正在遍历一个collection时,若map被修改了(除迭代器自身的移除操作以外),迭代器的结果会变为未定义。集合支持通过Iterator的Remove、Set.remove、removeAll、retainAll和clear操作进行元素移除,从map中移除对应的映射。它不支持add和addAll操作。
- Set<Map.Entry<K,V>> entrySet():返回一个map中包含的所有映射的一个集合视图。这个集合受map支持的,map的变化会在collection中反映出来,反之亦然。当一个迭代器正在遍历一个集合时,若map被修改了(除迭代器自身的移除操作,以及对迭代器返回的entry进行setValue外),迭代器的结果会变为未定义。集合支持通过Iterator的Remove、Set.remove、removeAll、retainAll和clear操作进行元素移除,从map中移除对应的映射。它不支持add和addAll操作。
- 遍历hashMap的5种方法遍历hashMap的5种方法_吕维尧的博客-优快云博客_遍历hashmap
先获得key的set集合,然后通过key获得value。
1.使用Iterator 遍历HashMap EntrySet
2.使用Iterator 遍历HashMap KeySet
3.使用For-each 循环迭代 HashMap
4.使用Lambda 表达式遍历HashMap
5.使用Stream API 遍历HashMap - HashMap和HashTable有何不同?
- 如何决定选用HashMap还是TreeMap?
- 对于在Map中插入、删除和定位元素这类操作,HashMap是最好的选择。然而,假如你需要对一个有序的key集合进行遍历,TreeMap是更好的选择。
- 基于你的collection的大小,也许向HashMap中添加元素会更快,将map换为TreeMap进行有序key的遍历。
-
队列和栈
- 在 Queue 中 poll()和 remove()有什么区别?
- 相同点:都是返回第一个元素,并在队列中删除返回的对象。
- 不同点:如果没有元素 poll()会返回 null,而 remove()会直接抛出 NoSuchElementException 异常。
- 队列和栈是什么,列出它们的区别?
- 栈和队列两者都被用来预存储数据。
- java.util.Queue是一个接口,它的实现类在Java并发包中。队列允许先进先出(FIFO)检索元素,但并非总是这样。Deque接口允许从两端检索元素。栈与队列很相似,但它允许对元素进行后进先出(LIFO)进行检索。
- Stack是一个扩展自Vector的类,而Queue是一个接口。
-
List、Set、Map
- List与Map的差别
List是存储单列数据的集合,Map是存储key和value这样双列数据的集合。
List中存储的数据是有顺序的,而且可以重复。Map其中存储的数据是没有顺序的,它存储的key是不能反复的,value是可以重复的。
List继承Collection接口,Map不是。Map没有父类 - List、Set、Map是否继承自Collection接口?
List、Set 是,Map 不是。Map是键值对映射容器,与List和Set有明显的区别,而Set存储的零散的元素且不允许有重复元素(数学中的集合也是如此),List是线性结构的容器,适用于按数值索引访问元素的情形。 - List、Map、Set三个接口。存取元素时各有什么特点
- 首先List和Set都是单列元素的集合。它们有一个共同的父接口Collection。
- List内的元素讲究有序性。内部元素可反复。可是Set恰恰相反。它讲究的是无序性,元素不可反复(用对象的equals()方法来区分元素是否重复)。Set的add方法有一个boolean的返回值,每当add一个新元素的时候都会调用equals方法进行逐一比較,当新元素与全部的已存在元素的都不反复的时候add成功返回true。否则返回false。
- Map与List和Set不同,它是双列存储的(键和值一一相应)。它在存储元素调用的是put方法,每次存储时,要存储一份key和value。不能存储反复的key,这个反复的规则也是利用equals进行比較。取数据的时候则能够依据key获取value。另外还是以获得全部key的集合和全部value的集合。还能够获得key和value组成的Map.Entry对象的集合。
- Set和Map容器都有基于哈希存储和排序树的两种实现版本,基于哈希存储的版本理论存取时间复杂度为O(1),而基于排序树版本的实现在插入或删除元素时会按照元素或元素的键(key)构成排序树从而达到排序和去重的效果。
- TreeMap和TreeSet在排序时如何比较元素?
TreeSet要求存放的对象所属的类必须实现Comparable接口,该接口提供了比较元素的compareTo()方法,当插入元素时会回调该方法比较元素的大小。TreeMap要求存放的键值对映射的键必须实现Comparable接口从而根据键对元素进行排序。 - 在迭代一个集合的时候,如何避免ConcurrentModificationException?
在遍历一个集合的时候,我们可以使用并发集合类来避免ConcurrentModificationException,比如使用CopyOnWriteArrayList,而不是ArrayList。 -
并发集合包
- 并发集合类是什么?
Java1.5并发包(java.util.concurrent)包含线程安全集合类,一部分类为:CopyOnWriteArrayList、CopyOnWriteArraySet、 ConcurrentHashMap。在对这些类遍历的时候如果出现对其进行增删改的操作,并不会报异常,其允许并发修改。 - ConcurrentHashMap的key和value都不能为null
- 什么是ConcurrentHashMap?为什么ConcurrentHashMap是线程安全的?
- ConcurrentHashMap的由来:HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。因为所有访问HashTable的线程都必须竞争同一把锁。
那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,ConcurrentHashMap就出现了。 - JDK1.7版本的CurrentHashMap的实现原理
- 在JDK1.7中ConcurrentHashMap采用了Segment数组+数组+链表的方式实现。
- Segment(分段锁)
ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁 - ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。
Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
- get方法
- 为输入的key做hash算法,得到hash值
- 通过hash值,定位到对应的segment对象
- 再次通过hash值,定位到segment当中数组的链表
- 再遍历链表获取到key的值
- put方法
- 为输入的key做hash算法,得到hash值
- 通过hash值,定位到对应的segment对象
- 获得可重入锁
- 再次通过hash值,定位到segment当中数组的具体位置
- 插入或者覆盖hashEntry对象
- 释放锁
- JDK1.8版本的CurrentHashMap的实现原理
- JDK8中ConcurrentHashMap参考了JDK8 HashMap的实现,采用了数组+链表+红黑树的实现方式来设计,内部大量采用CAS操作,这里我简要介绍下CAS。
Java8 ConcurrentHashMap结构基本上和Java8的HashMap一样,不过保证线程安全性。 - CAS是compare and swap的缩写,即我们所说的比较交换。cas是一种基于锁的操作,而且是乐观锁。在java中锁分为乐观锁和悲观锁。悲观锁是将资源锁住,等一个之前获得锁的线程释放锁之后,下一个线程才可以访问。而乐观锁采取了一种宽泛的态度,通过某种方式不加锁来处理资源,比如通过给记录加version来获取数据,性能较悲观锁有很大的提高。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存地址里面的值和A的值是一样的,那么就将内存里面的值更新成B。CAS是通过无限循环来获取数据的,若果在第一轮循环中,a线程获取地址里面的值被b线程修改了,那么a线程需要自旋,到下次循环才有可能机会执行。 - JDK8中彻底放弃了Segment转而采用的是Node,其设计思想也不再是JDK1.7中的分段锁思想。
- Node:保存key,value及key的hash值的数据结构。其中value和next都用volatile修饰,保证并发的可见性。
- JDK8中ConcurrentHashMap参考了JDK8 HashMap的实现,采用了数组+链表+红黑树的实现方式来设计,内部大量采用CAS操作,这里我简要介绍下CAS。
- 总结
- 其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树。
- 数据结构:取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
- 保证线程安全机制:JDK1.7采用segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。JDK1.8采用CAS+Synchronized保证线程安全。
- 锁的粒度:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
- 链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
- 查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。
- ConcurrentHashMap的由来:HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。因为所有访问HashTable的线程都必须竞争同一把锁。
- BlockingQueue是什么?
Java.util.concurrent.BlockingQueue是一个队列,在进行检索或移除一个元素的时候,它会等待队列变为非空;当在添加一个元素时,它会等待队列中的可用空间。BlockingQueue接口是Java集合框架的一部分,主要用于实现生产者-消费者模式。我们不需要担心等待生产者有可用的空间,或消费者有可用的对象,因为它都在BlockingQueue的实现类中被处理了。Java提供了集中BlockingQueue的实现,比如ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue,、SynchronousQueue等。 -
其他
- 我们如何对一组对象进行排序?
如果我们需要对一个对象数组进行排序,我们可以使用Arrays.sort()方法。
如果我们需要排序一个对象集合,我们可以使用Collections.sort()方法。
两个类都有用于自然排序(使用Comparable)或基于标准的排序(使用Comparator)的重载方法sort()。
Collections内部使用数组排序方法,所有它们两者都有相同的性能,只是Collections需要花时间将列表转换为数组。 - Collections.sort排序内部原理
内部实现换成了TimSort排序,Timsort是结合了合并排序和插入排序而得出的排序算法,它在现实中有很好的效率。
1.数组个数小于32的情况使用二分插入排序
2.数组大于32时,先算出一个合适的大小,再将输入按其升序和降序特点进行分区。 - hashCode()和equals()方法有何重要性?
HashMap使用Key对象的hashCode()和equals()方法去决定key-value对的索引。当我们试着从HashMap中获取值的时候,这些方法也会被用到。如果这些方法没有被正确地实现,在这种情况下,两个不同Key也许会产生相同的hashCode()和equals()输出,HashMap将会认为它们是相同的,然后覆盖它们,而非把它们存储到不同的地方。同样的,所有不允许存储重复数据的集合类都使用hashCode()和equals()去查找重复,所以正确实现它们非常重要。equals()和hashCode()的实现应该遵循以下规则:
(1)如果o1.equals(o2),那么o1.hashCode() == o2.hashCode()总是为true的。
(2)如果o1.hashCode() == o2.hashCode(),并不意味着o1.equals(o2)会为true。 - 哪些集合类是线程安全的?
Vector、HashTable、Properties和Stack是同步类,所以它们是线程安全的,可以在多线程环境下使用。Java1.5并发API包括一些集合类,允许迭代时修改,因为它们都工作在集合的克隆上,所以它们在多线程环境中是安全的。 - 我们如何从给定集合那里创建一个synchronized的集合?
我们可以使用Collections.synchronizedCollection(Collection c)根据指定集合来获取一个synchronized(线程安全的)集合。 - 大写的O是什么?举几个例子?
大写的O描述的是,就数据结构中的一系列元素而言,一个算法的性能。Collection类就是实际的数据结构,我们通常基于时间、内存和性能,使用大写的O来选择集合实现。比如:例子1:ArrayList的get(index i)是一个常量时间操作,它不依赖list中元素的数量。所以它的性能是O(1)。例子2:一个对于数组或列表的线性搜索的性能是O(n),因为我们需要遍历所有的元素来查找需要的元素。 - 与Java集合框架相关的有哪些最好的实践?
- 根据需要选择正确的集合类型。比如,如果指定了大小,我们会选用Array而非ArrayList。如果我们想根据插入顺序遍历一个Map,我们需要使用TreeMap。如果我们不想重复,我们应该使用Set。
- 一些集合类允许指定初始容量,所以如果我们能够估计到存储元素的数量,我们可以使用它,就避免了重新哈希或大小调整。
- 基于接口编程,而非基于实现编程,它允许我们后来轻易地改变实现。
- 总是使用类型安全的泛型,避免在运行时出现ClassCastException。
- 使用JDK提供的不可变类作为Map的key,可以避免自己实现hashCode()和equals()。
- 尽可能使用Collections工具类,或者获取只读、同步或空的集合,而非编写自己的实现。它将会提供代码重用性,它有着更好的稳定性和可维护性。

















 3138
3138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









