




 本文探讨了电商数据分析中的指标体系搭建,强调了数据驱动在用户增长和产品优化中的重要性。通过制定核心目标,如UV、PV、DAU、MAU,将数据分析分为定制数据、指标还原和数据分析三步。重点关注CXO、运营和市场角色的需求,提出从业务出发设定指标,例如订单流转化率,并提供电商订单流的示例,包括商品详情页到购物车、购物车到提交订单等转化率,以降低流失率,提升转化效率。
本文探讨了电商数据分析中的指标体系搭建,强调了数据驱动在用户增长和产品优化中的重要性。通过制定核心目标,如UV、PV、DAU、MAU,将数据分析分为定制数据、指标还原和数据分析三步。重点关注CXO、运营和市场角色的需求,提出从业务出发设定指标,例如订单流转化率,并提供电商订单流的示例,包括商品详情页到购物车、购物车到提交订单等转化率,以降低流失率,提升转化效率。
指标是量化衡量标准、衡量目标的单位或方法,例如对电商数据分析来说,最常见的指标就是UV和PV,而针对APP来说,最常见的就是DAU,MAU。
有了指标也就知道应该从哪些角度入手开始数据分析,数据驱动已经是我们在做用户增长和产品优化的核心指导方向,我们会把数据驱动从定制数据到使用数据分成三步:
1、根据核心目标制定数据分析指标
2、指标还原到埋点方案
3、围绕核心目标开始数据分析
最关键的步骤就是如何制定指标,指标是与业务关联最近的,也是最灵活的一个步骤,因为不同的业务指标完全不同,在电商数据分析中,业务的指标跟交易有关,软件业务的指标会跟注册有关,虽然都会归结于范交易,但是在指标体系搭建上还是略有不同,我们总结了一些可快速上手的行业通用指标,给你在开始进行网站或APP分析前一些指标体系的建议。
在指标搭建前,先说说,你想看到什么数据?
电商网站(APP)应该关注的数据看板什么样?
从实际业务出发,举例CXO,市场,运营三个核心角色,每个角色需要看的内容不同
**CXO:**想了解业务数据,只能被动的等待下属的分析报告,需要更直观的方式,掌握真实数据,及时获得洞察。
**运营:**做了大量的运营活动,无法分析效果如何,现有渠道提供的分析能力不足以支撑精细化运营,缺少体系化的数据支持。
**市场:**花出去的预算,就像泼出去的水,如何衡量效果?如何进行广告跟踪提高ROI?
(一)根据需求设定的电商数据分析指标
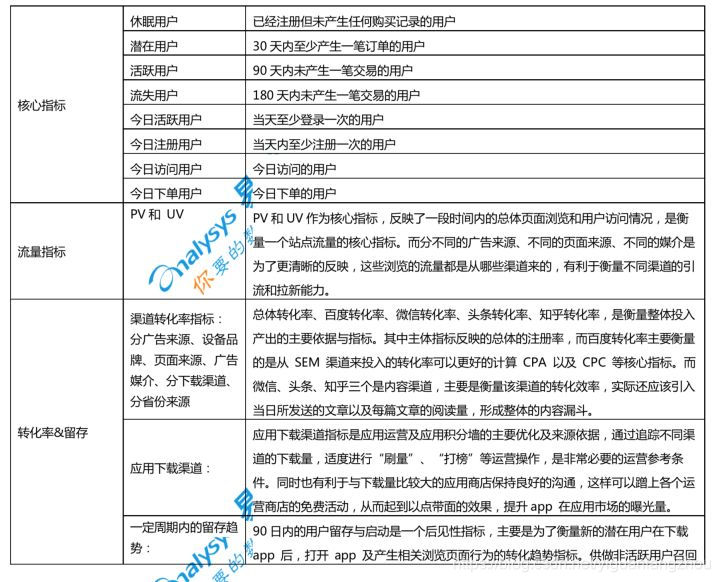
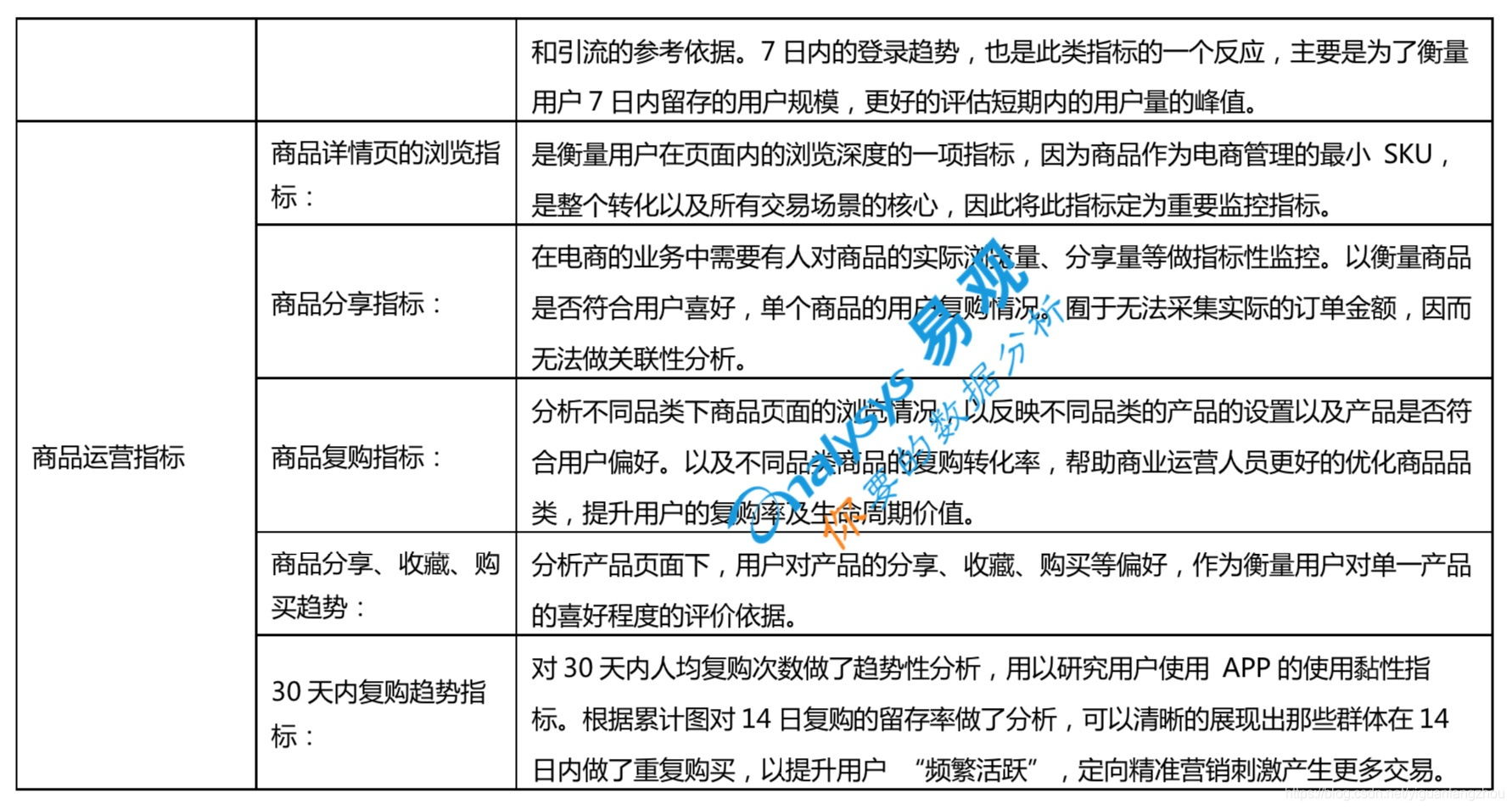
有了这些指标,等同于掌握了用户在产品上的基本行为。通过这些指标的简单组合就
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5647
5647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









