










文章转自公众号老刘说NLP
我们今天继续来关注RAG相关进展,目前热点集中于多模态RAG以及GraphRAG,关于这两块,我们已经讲了很多了。现在来看下最新的两个工作。
对了,对于大模型评估这块,社区成员有个工作《A Survey on LLM-as-a-Judge》(https://arxiv.org/abs/2411.15594),讨论了LLM-as-a-Judge的相关研究,并且围绕how to build a reliable evaluator进行了相关的探讨分析,一句话结论的话,就是现在用大模型做评估器任重而道远,无论是如何提升可靠性,还是如何评估评估器方面,都需要继续完善,现有的评估器还是存在明显的不可靠和偏见,想用大模型做内容评估的,可以参考。
从文中的两个RAG的进展,我们可以从中找到一些思路。
一、mR2AG多模态RAG打榜思路用于VQA
多模态RAG的思路,可以看看《mR2AG: Multimodal Retrieval-Reflection-Augmented Generation for Knowledge-Based VQA》(https://arxiv.org/pdf/2411.15041,是个打榜的思路。
几个看点:
一个是针对VQA这个任务,目前的几种方式,如下:
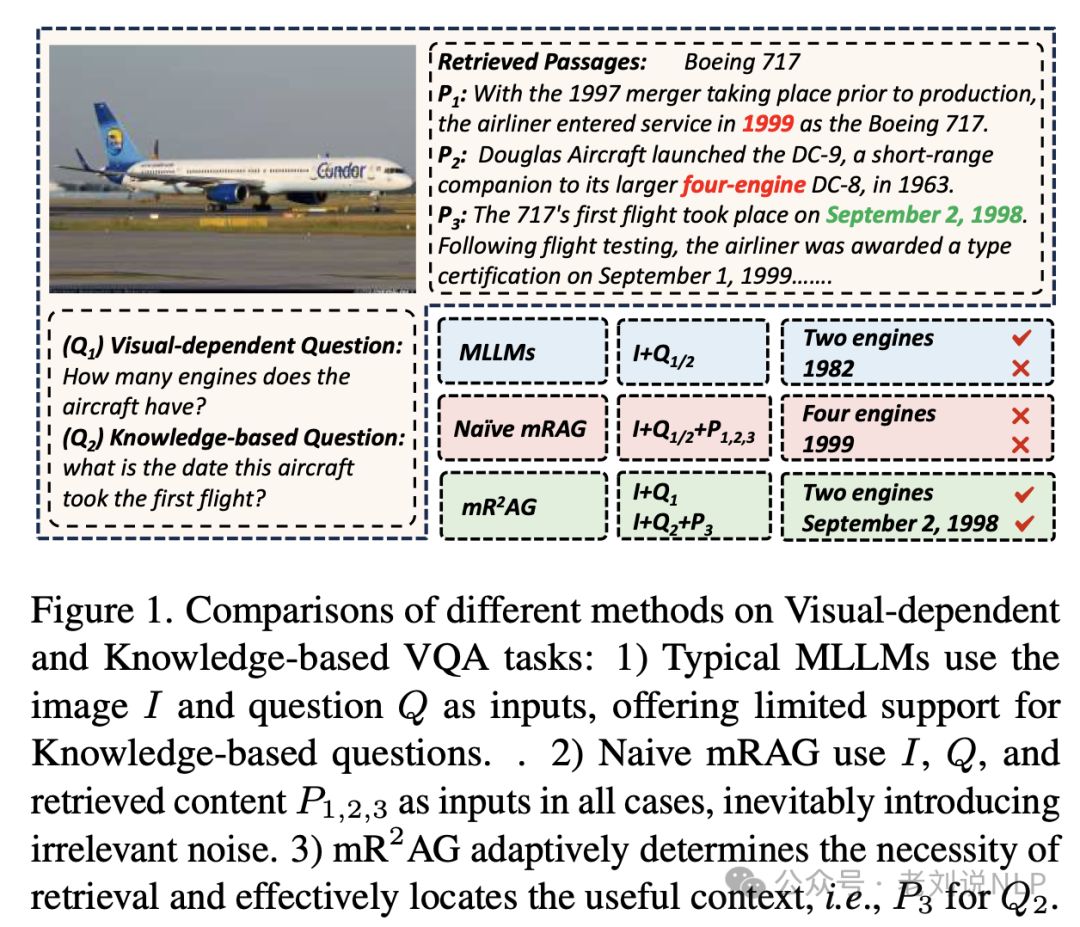
典型的MLLMs使用图像I和问题Q作为输入,对于基于知识的问题提供有限的支持;简单的mRAG在所有情况下使用I、Q和检索到的内容P1、2、3作为输入,不可避免地引入了不相关的噪声;
mR2AG自适应地确定检索的必要性,并有效地定位有用的上下文,即对于Q2的P3。
所以看第二点,其实现思路,思想都在名称里《multimodal Retrieval-Reflection- Augmented Generation (mR2AG)》,如下图:
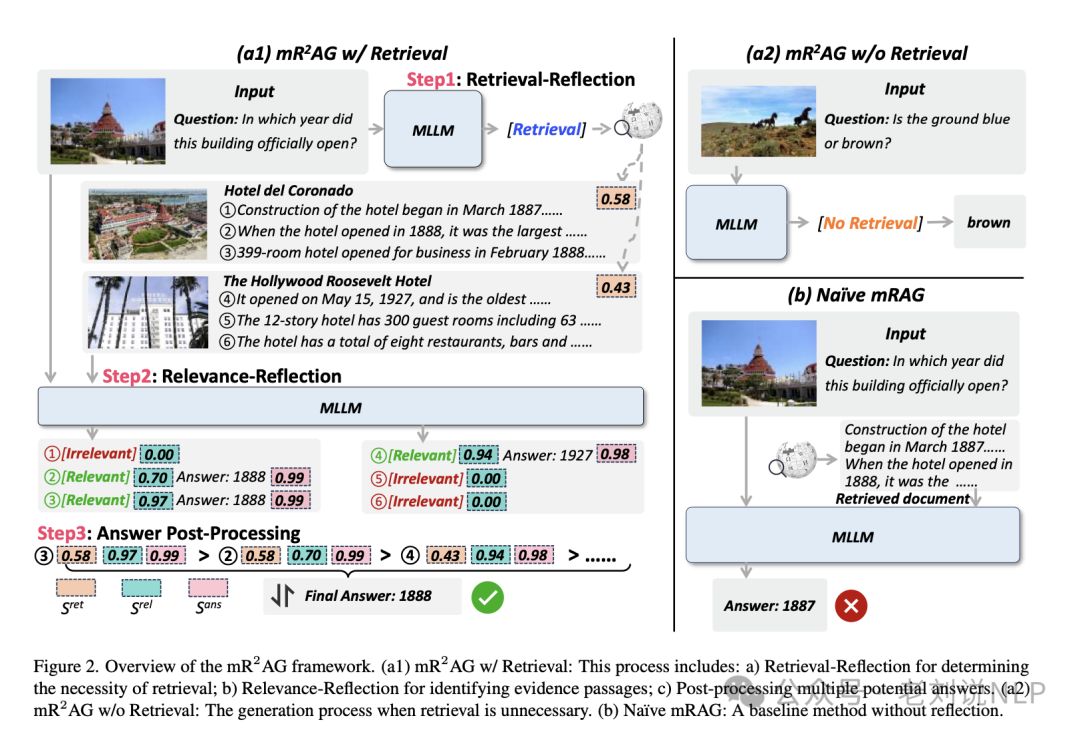
首先,检索-反思阶段,通过定义两个特殊标记[检索]/[不检索],模型根据输入的图像和问题生成检索反射预测。如果预测结果为[不检索],则直接生成答案;如果预测结果为[检索],则调用检索器以辅助进一步的生成过程。
其次,相关性-反思阶段,将每个检索到的文章分成多个自然段落,并使用两个相关性反射标记[相关]/[不相关]来判断每个段落是否包含与问题相关的证据。如果段落被标记为[相关],则继续生成答案。
其中判断是否相关,还是依赖于大模型自身能力,依旧走的蒸馏GPT4的路线,蒸馏方式简单快速:

最后,答案后处理阶段,这个是有意思的点,对于一个文章中可能存在的多个证据段落,通过层次化的后处理步骤对候选答案进行排序,综合考虑条目级、段落级和答案级的分数。
具体的,条目级别阶段检索分数衡量查询图像与候选维基百科条目的相似性。段落级别阶段生成相关性-反射标记的概率量化模型判断作为证据得分;答案级别阶段,计算生成答案序列中每个标记的概率,并使用几何平均归一化序列长度变化的影响,得出答案分;

这三个层次的分考虑了答案生成过程中的每一步,分别在入口、段落和答案层面评估候选答案的可靠性。通过计算这三个分数的乘积来整合它们的效果,这作为对候选答案进行排名的最终标准。模型根据这一标准输出得分最高的答案,但是,这样一来,需执行多次生成操作,是耗时的,所以,本质上,这个是投票思路。
二、G-RAG方案结合实体链接用于材料科学场景
关于GraphRAG进展,《G-RAG: Knowledge Expansion in Material Science》(https://arxiv.org/abs/2411.14592),这个跟之前的GraphRAG的区别在于实体链接,使得使用实体提取器从文本中提取特定实体,然后将识别出的实体用于查询外部检索器,后者从维基百科知识库中获取相关的MatIDs及其对应的信息,从而保证准确性。
所以,重复下,这个工作的核心,就是实体链接的步骤,链接到图数据库,然后召回拿更多信息,即使用实体提取器(如Span Parser)从文本中提取特定实体,然后查询外部维基百科知识库以获取相关信息,思路如下:
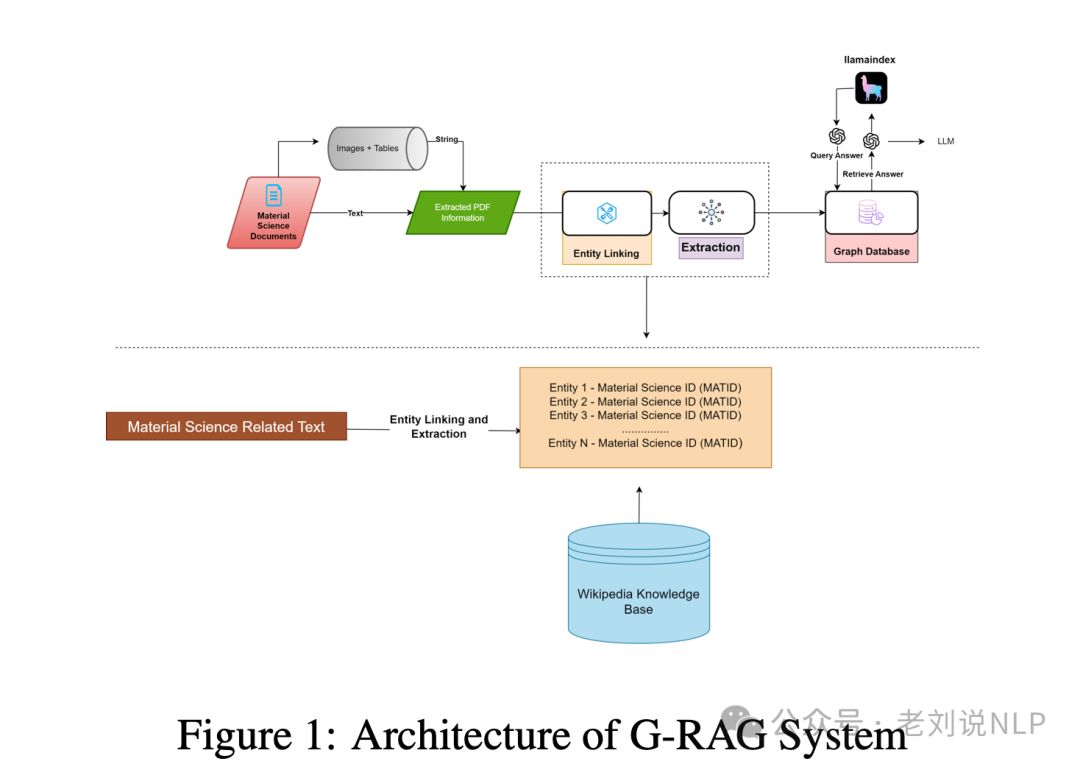
为了做这个事情,文档解析思路,将内容分类为文本、图表和表格。对于图表提取,使用Phi-3.5 Vision Instruct模型,表格数据提取使用Microsoft的Table Transformer,这个用于建库。

对于图片的分类归属,也有分类链接;
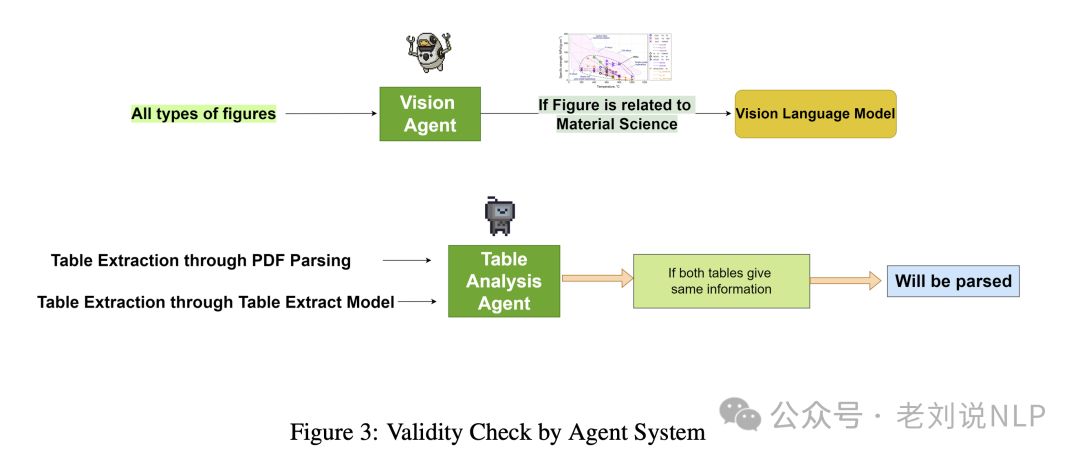
解析之后,在检索阶段,则进行实体链接和关系抽取,这块的思路是,将文本中的模糊提及映射到知识库中的特定命名实体,关系提取(RE)识别和分类文本中提到的实体之间的语义关系。

至于为什么要进行关系抽取,初衷是关系抽取之后,能够用于提升实体链接准确性,因为可以补充外部特征;另外,在进行检索阶段,可以利用这个关系,将相关的内容进行召回。
参考文献
1、https://arxiv.org/pdf/2411.15041
2、https://arxiv.org/abs/2411.14592


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









