







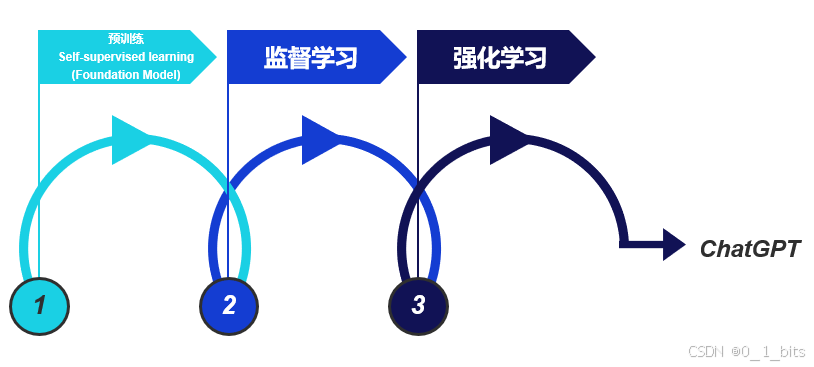
随着人工智能技术的飞速发展,ChatGPT作为其中的佼佼者,已经在各个领域展现出强大的应用潜力。那么,ChatGPT究竟是如何工作的呢?本文将从基石模型(预训练)、自监督学习、监督学习以及强化学习等多个角度,深入解析ChatGPT的运作机制,并结合实际操作步骤,带您全面了解这一先进技术的背后奥秘。
一、基石模型阶段(预训练):奠定坚实的语言基础 📚
自监督学习与基础模型
基石模型(预训练阶段)是构建ChatGPT的首要步骤,它采用了自监督学习的方法。这种方法不需要人工标注的数据,而是利用大量的互联网文本作为训练资料。通过自监督学习,模型能够自主学习语言的结构和规律,形成强大的语言理解与生成能力。
伪标签的生成
在基石模型阶段,模型的任务是预测文本中下一个词汇,这个“下一个词”被称为伪标签。由于模型是自回归的,它在每次预测时都会考虑输入文本中所有之前的词汇。这种方式不仅提高了预测的准确性,还使模型能够在生成文本时保持上下文的连贯性。
自回归模型的优势
自回归模型的一个显著特点是它能够基于已有的词汇生成新的内容。这意味着,每一个新词的生成都依赖于前面的上下文,从而确保生成的文本语法正确、语义丰富。这为之后的监督学习和强化学习奠定了坚实的基础。
二、监督学习阶段:提升模型的回答质量 🎯
微调(Fine-Tuning)的重要性
在基石模型完成预训练后,模型需要通过监督学习进行微调,以适应特定的任务需求。微调过程通过提供高质量的问答对,使模型不仅能够完成句子,还能准确回答用户的问题。这一过程中,模型的性能和回答质量得到了显著提升。
微调的优势
- 更高质量的结果:相较于简单的提示(prompting),微调能够显著提高模型生成回答的质量和准确性。
- 处理更多示例:通过微调,模型可以学习和处理比提示中更多的示例,增强其泛化能力。
- 节省令牌(Token):由于微调后的模型不需要依赖长提示,因此在生成答案时能够节省计算资源,降低延迟。
- 降低请求延迟:微调优化后的模型能够更快速地响应用户请求,提高用户体验。
三、强化学习阶段:通过人类反馈优化模型 🧠
强化学习(RL)的应用
在监督学习之后,ChatGPT进一步通过强化学习优化其生成的回答。这一阶段主要依赖人类反馈,使模型能够根据具体的反馈信息不断改进其输出结果。
强化学习的具体步骤
- 收集训练数据:包括问题和多个可能的答案,通过这些数据训练模型,使其能够生成更符合人类期望的回答。
- 奖励模型的训练:基于收集到的多种回答,训练一个奖励模型,以评估和排名这些回答的相关性和质量。
- 利用PPO优化:通过策略优化算法(如PPO),对模型进行进一步调整,使其生成的回答更加准确、相关,提升整体对话的质量。
强化学习的优势
通过强化学习,ChatGPT能够:
- 提升回答的相关性:根据人类反馈,模型能够生成更贴合用户需求的回答。
- 提高生成回答的准确性:不断优化生成过程,减少错误和偏差。
- 增强对话的连贯性:使模型在多轮对话中保持逻辑一致,提供更流畅的用户体验。
四、内容审核与安全保障:确保回答的合规与安全 🔒
在整个回答生成过程中,ChatGPT还引入了内容审核机制,以确保生成的回答符合安全和道德标准。
内容审核的流程
- 输入审核:用户输入的问题首先经过内容审核,确保其不包含不当或违规内容。
- 模型生成:若输入通过审核,问题将被传递给ChatGPT模型进行回答生成;否则,系统会生成预设的回答模板。
- 输出审核:模型生成的回答同样需要经过内容审核,确保其内容安全、无偏见且符合指导原则。
- 展示给用户:通过审核的回答将展示给用户,未通过审核的内容将被替换为安全的模板答案。
这种双重审核机制不仅保障了用户的使用安全,也提升了ChatGPT在实际应用中的可靠性和可信度。
五、ChatGPT系统的整体工作流程 📊
为了更全面地理解ChatGPT的工作机制,我们将其整体流程分为两个主要部分:训练阶段和应答阶段。
1. 训练阶段
训练ChatGPT模型主要包括两个阶段:
- 基石模型(预训练)
在此阶段,利用大规模的互联网数据训练一个GPT模型(仅解码器的transformer结构)。目标是让模型能够在给定句子的基础上预测未来的词汇,确保生成的文本在语法和语义上都与互联网数据相似。基石模型完成后,模型能够完成给定的句子,但尚无法进行问答。
- 微调(Fine-Tuning)
微调阶段是一个三步过程,将预训练的基石模型转变为具备问答能力的ChatGPT模型:
- 收集训练数据并进行微调:收集包含问题和答案的训练数据,并在这些数据上对预训练模型进行微调。模型学习在输入问题的情况下生成类似训练数据的答案。
- 训练奖励模型:收集更多数据(包括问题和多个答案),训练一个奖励模型,以根据相关性和质量对这些答案进行排名。
- 利用强化学习优化模型:通过策略优化算法(如PPO),根据奖励模型的反馈进一步微调模型,使其生成的回答更加准确和相关。
2. 应答阶段
当用户向ChatGPT提出问题时,系统按照以下步骤进行处理:
🔹步骤1:用户输入完整的问题,例如:“解释一下分类算法是如何工作的。”
🔹步骤2:问题首先被发送到内容审核组件,确保其不违反安全指南并过滤不当问题。
🔹步骤3-4:如果输入通过审核,问题将被传递给ChatGPT模型进行回答生成;否则,系统会直接生成预设的模板回答。
🔹步骤5-6:模型生成的回答同样需要经过内容审核,确保其内容安全、无害、无偏见等。
🔹步骤7:如果生成的回答通过审核,将展示给用户;如果未通过审核,系统将展示一个模板答案给用户。
这一系列步骤确保了用户能够获得安全、准确且相关的回答,同时保障了系统的合规性和可靠性。
六、总结 🏆
从基石模型(预训练)到强化学习,ChatGPT通过多层次、多阶段的训练与优化,实现了强大的语言理解与生成能力。自监督学习奠定了坚实的语言基础,监督学习提升了回答的质量与准确性,强化学习则通过人类反馈不断优化模型的输出。此外,内容审核机制确保了回答的安全性和合规性。整体的工作流程不仅涵盖了模型的训练和优化,还包括了严格的内容审核,全面保障了系统的性能与安全性。
正是这些复杂而精细的运作机制,使得ChatGPT在众多人工智能应用中脱颖而出,成为引领未来的智能对话系统。
希望这篇文章能帮助您更好地理解ChatGPT的运作机制。欢迎大家关注我的后续更新,并在评论区分享您的见解和问题! 📢💬


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









