




 本文介绍了如何利用Python Django、Celery、RabbitMQ、Clickhouse和S3构建数据导出服务。在原有方案中,业务前端请求触发数据查询并存储于S3,由Celery消费MQ消息。新方案加入了数据团队,查询操作转至Clickhouse,仍使用Celery和MQ,但增加了数据交互的复杂性。目前架构存在功能重复,但考虑性能优化和削峰填谷,保留了现有设计。
本文介绍了如何利用Python Django、Celery、RabbitMQ、Clickhouse和S3构建数据导出服务。在原有方案中,业务前端请求触发数据查询并存储于S3,由Celery消费MQ消息。新方案加入了数据团队,查询操作转至Clickhouse,仍使用Celery和MQ,但增加了数据交互的复杂性。目前架构存在功能重复,但考虑性能优化和削峰填谷,保留了现有设计。
工作背景
由于线上的查询与导数任务影响了业务的数据库查询性能,于是需要大数据团队负责将这块业务梳理到数据侧进行。
主要的工作流程
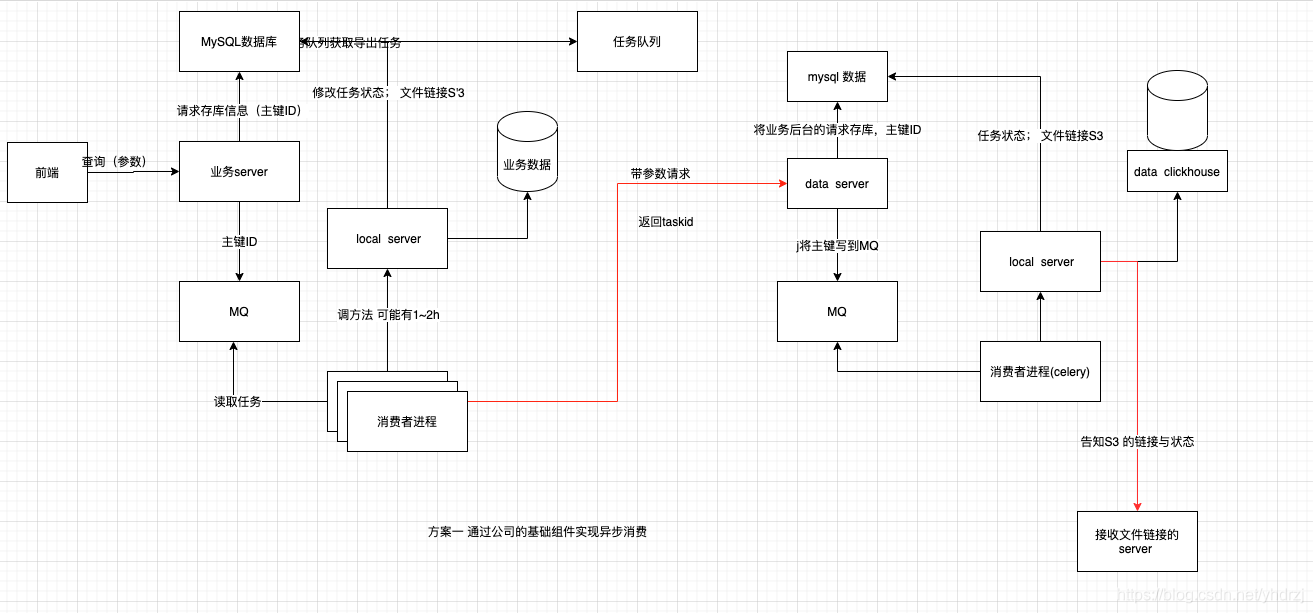
上图展示了在业务与data的接口侧的现在的技术架构图。下面对这个过程进行说明下:
原来业务的旧方案(图中的左边部分):
- 业务前端通过导出请求,将请求打到她们自己的后台服务器上,这时候,服务器会做两件事情,(1)为这个请求生成一个UUID,并将这个请求消息的相关参数存入到mysq 中,(2)将这个消息存入到MQ中。
- 消费者进程(Celery)读取MQ中的消息,并按照消息中的参数,请求查询业务数据库,将查询结果写到S3文件中。并将S3的链接与执行状态写到mysql库中。
- 前端轮询接口,查询到该任务的状态信息后,即成功消息,与S3文件链接链接。生成生成相应的下载页面。
- 页面点击下载后,通过S3的文件链接,下载S3文件。
新的加入数据团队的方案(整个图):
- 业务前端通过导出请求,将请求打到她们自己的后台服务器上,这时候,服务器会做两件事情,(1)为这个请求生成一个UUID,并将这个请求消息的相关参数存入到mysq 中,(2)将这个消息存入到MQ中。
- 消费者进程(Celery)读取MQ中的消息,并将请求转发到DATA 侧。
- DATA接收到了请求后,后续的操作与业务类似。即服务器会做两件事情,(1)为这个请求生成一个UUID,并将这个请求消息的相关参数存入到mysq 中,(2)将这个消息存入到MQ中。
- 消费者进程(Celery)读取MQ中的消息,并按照消息中的参数,请求查询Clickhouse数据库,将查询结果写到S3文件中。并将S3的链接与执行状态写到mys
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 134
134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









