







目录
10 Zookeeper的如何保证数据一致性/zk底层原理(ZAB)
13 为什么用zookeeper充当注册中心/zookeeper的好处
0 zookeeper的默认端口号:2181
1 Linux下ZooKeeper的安装
2 什么是Zookeeper?
-
Why(与我何干?):在分布式系统中,不同的计算机或服务需要协同工作,它们之间需要一种机制来共享状态和协调任务。Zookeeper提供了这样的机制,确保系统的一致性和可靠性。
-
What(定义、概念解释):Zookeeper是一个为分布式应用提供一致性服务的软件,它能够处理诸如数据同步、状态共享、配置管理等任务。它基于一种称为ZAB(Zookeeper Atomic Broadcast)协议的一致性算法。
-
How(步骤流程方法):Zookeeper的工作原理基于一个分层的命名空间,类似于文件系统。客户端可以通过这个命名空间来创建、读取、更新和删除节点(znodes)。每个znode可以存储数据,并且可以有子节点。Zookeeper通过watch机制来通知客户端关于znode状态的变化,从而实现事件驱动的通信。客户端和服务端通过发送ping心跳包来保活。
-
How Good(好处和改变):Zookeeper的好处在于它提供了一个高性能、高可用、且易于使用的协调服务。它使得开发者可以专注于业务逻辑,而不必过多地担心底层的分布式协调问题。此外,Zookeeper的一致性和可靠性保证了分布式系统的稳定性。
3 ZooKeeper节点存储znode
Zookeeper提供一个多层级的节点命名空间(节点称为znode)。与文件系统不同的是,这些节点可以同时拥有数据和子节点,而文件系统中只有文件节点可以存放数据而目录节点不行。Zookeeper为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,这种特性使得Zookeeper不能用于存放大量的数据,每个节点的存放数据上限为1M。
在zookeeper中,每个znode都可以存放数据,也可以存放子节点,znode存放的数据类型是xxxx:xxx的形式,比如127.0.0.1:6000

上面这张图中,/在linux里面是根目录,在zookeeper里面是根节点,每个节点本身可以存放数据,也可以有子节点。注意:节点和数据是可以同时存在的,他们并不会互相冲突。
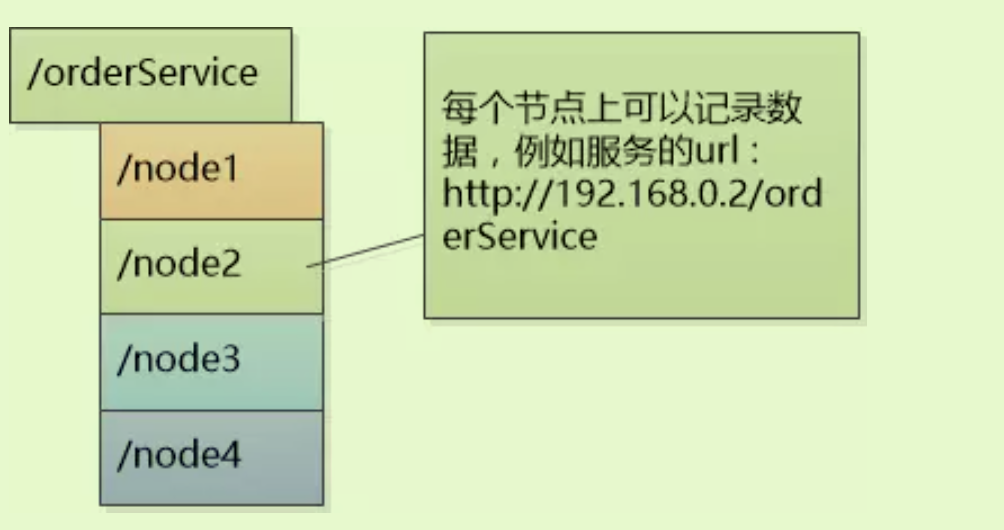
znode节点分为以下几种:
-
持久节点:当服务关闭时,节点仍然会存在zookeeper服务器中。
-
临时节点:服务关闭时,节点会被自动删除
-
有序节点:比如说我们创建一个节点server,假如说系统中有server1和server2两个节点,那么它的名字就会是server3。
-
临时有序节点:临时节点和有序节点的结合。
4 zk客户端常用命令
注意:zk的所有路径都得从根目录开始写起
-
ls:获取当前路径下的节点,比如:
ls /master -
get:查看节点内容,比如查看根节点下面节点的内容:
get /,可以看到如下内容: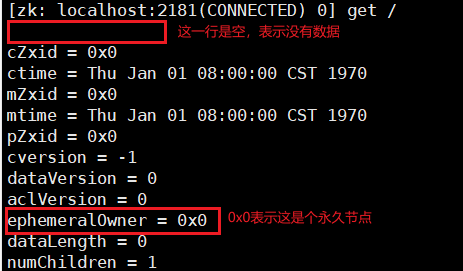
-
creat:创建节点:
创建一个名为/path的znode 节点,包含数据data:create /path data,创建一个节点,必须保证路径下的每个祖先节点都存在,比如create /sl/sl1/sl2 10必须得保证根目录/下sl,sl1,都存在,然后才能创建sl2 -
delete:删除节点,比如
delete /path //删除名为/path的znode -
exists:检查节点是否存在,比如:
exists /path //检查是否存在名为/path的节点 -
set: 设置节点值,比如:
set /path data //设置名为/path的节点数据为data -
getData:返回节点数据信息,比如:
getData /path //返回名为/path节点的数据信息 -
getChildren:返回节点的子节点列表,比如:
getChildren /path //返回/path节点的所有子节点列表注意: zookeeper不允许局部写入或者读取znode节点的数据,也就是你读取数据不能读数据的一半
5 zookeeper的监视与通知机制
5.1 watch基于事件的应用
zookeeper有watch事件,是一次性触发的,当watch监视的数据发生变化时,zkserver会通知设置了该watch的client,即watcher. 同样:其watcher监听的数据发送了某些变化,那就一定会有对应的事件类型和状态类型。
事件类型:(znode节点相关的)
EventType:NodeCreated //节点创建
EventType:NodeDataChanged //节点的数据变更
EventType:NodeChildrentChanged //子节点下的数据变更
EventType:NodeDeleted //节点的删除
状态类型:(是跟客户端实例相关的)
KeeperState:Disconneced //连接失败
KeeperState:SyncConnected //连接成功
KeeperState:AuthFailed //认证失败
KeeperState:Expired //会话过期
5.2 watch底层机制
ZooKeeper 提供了分布式数据的发布/订阅功能。
这让我想到一种模式,观察者模式(发布订阅模式):一个典型的发布/订阅模型系统定义了一种一对多的订阅关系,能够让多个订阅者同时监听某一个主题对象,当这个主题自身状态变化时,会通知所有订阅者,使它们能够做出相应的处理。那 ZooKeeper 是不是也是使用了这个经典的模式呢?
在 ZooKeeper 中,引入了 Watcher 机制来实现这种分布式的通知功能。ZooKeeper 允许客户端向服务端注册一个 Watcher 监听,当服务器的一些特定事件触发了这个 Watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能。
ZooKeeper 的 Watcher 机制主要包括客户端线程、客户端 WatchManager 和 ZooKeeper 服务器三部分。
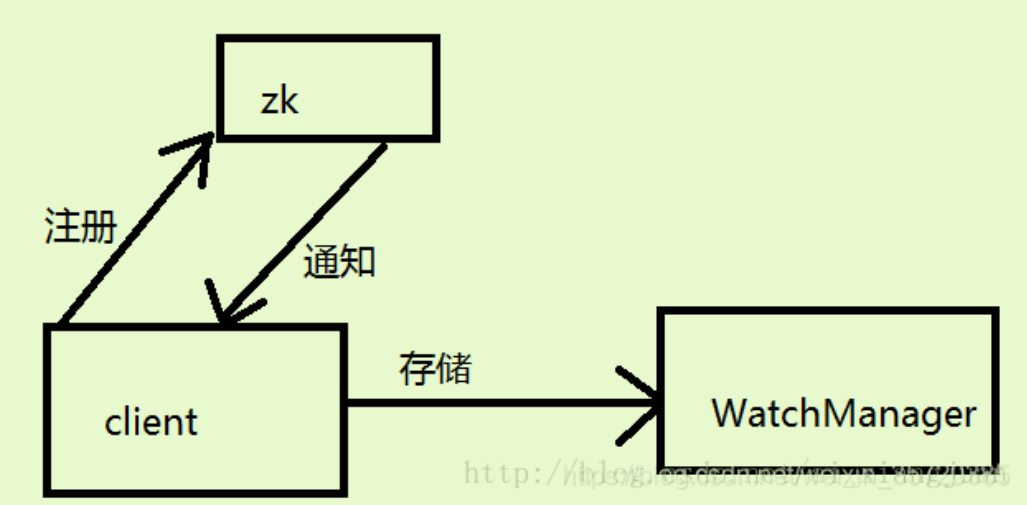
在上图中:
-
ZooKeeper :部署在远程主机上的 ZooKeeper 集群,当然,也可能是单机的。
-
Client :分布在各处的ZooKeeper的客户端,被引用在各个独立应用程序中。
-
WatchManager :一个接口,用于管理各个监听器,只有一个方法 materialize(),返回一个 Watcher 的 set。
5.3 工作机制
-
客户端在向zk服务器注册Watcher的同时,会将Watcher对象存储在客户端的WatchManager中。
-
当zk服务端触发Watch事件后,会向客户端发送通知,客户端线程从WatcherManager中取出对应的Watcher对象。来执行回调逻辑。
5.4 watcher的特性
-
一次性:zookeeper的watch事件,是一次性触发的,当watch监视的数据发生变化时,通知设置了该watch的client,即watcher,通知完成后,下次再发送watch,就不再向watcher发送通知。由于zookeeper的监控都是一次性的,所以每次必须重新设置监控。
-
客户端串行执行:客户端Watcher回调的过程是一个串行同步的过程,这为我们保证了顺序,同时需要开发人员注意一点,千万不要因为一个Watcher的处理逻辑影响了整个客户端的Watcher回调。
-
轻量:WatchedEvent是Zookeeper整个Watcher通知机制的最小通知单元,整个结构只包含三部分:通知状态、事件类型和节点路径。也就是说Watcher通知非常的简单,只会告诉客户端发生了事件,而不会告知其具体内容,需要客户端自己去进行获取,比如NodeDataChanged事件,Zookeeper只会通知客户端指定节点的数据发生了变更,而不会直接提供具体的数据内容。
6 zookeeper的版本
对于每个znode节点来说,它都有一个版本号,它随着每次数据变化而自增。假如是有两个API操作可以有条件的执行:setData和delete。这两个调用以版本号作为传入参数,只有当传入参数的版本号和服务器的版本号一致时调用才会成功。
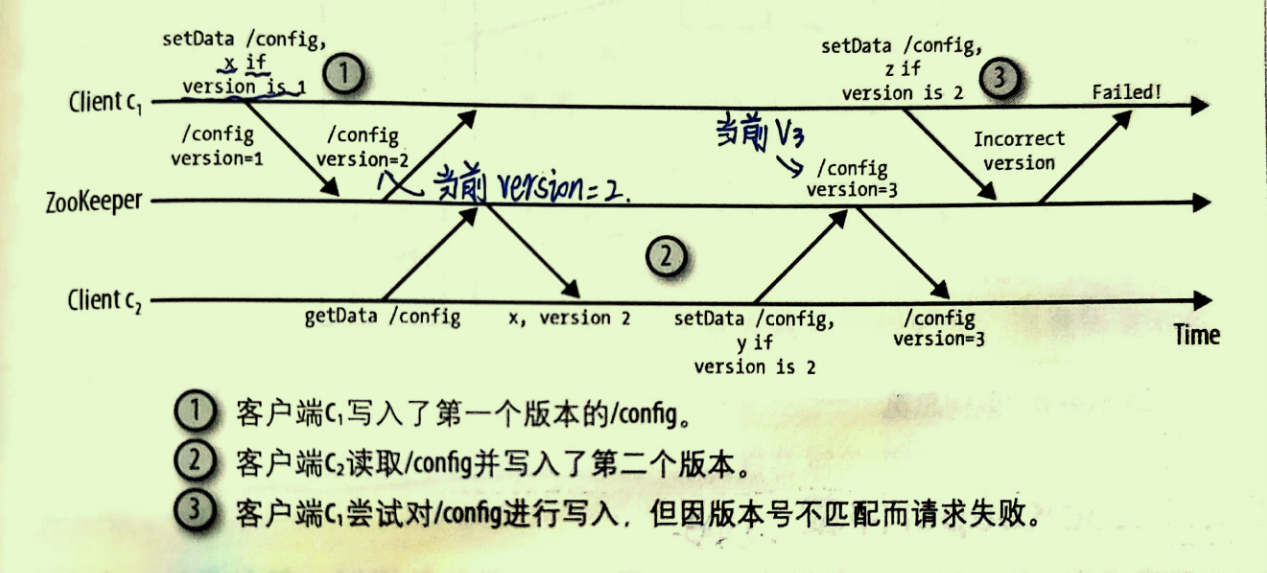
7 zookeeper服务器模式和会话
应用一般是调用客户端库来对zookeeper实现调用,客户端库负责与zookeeper服务器端进行交互。
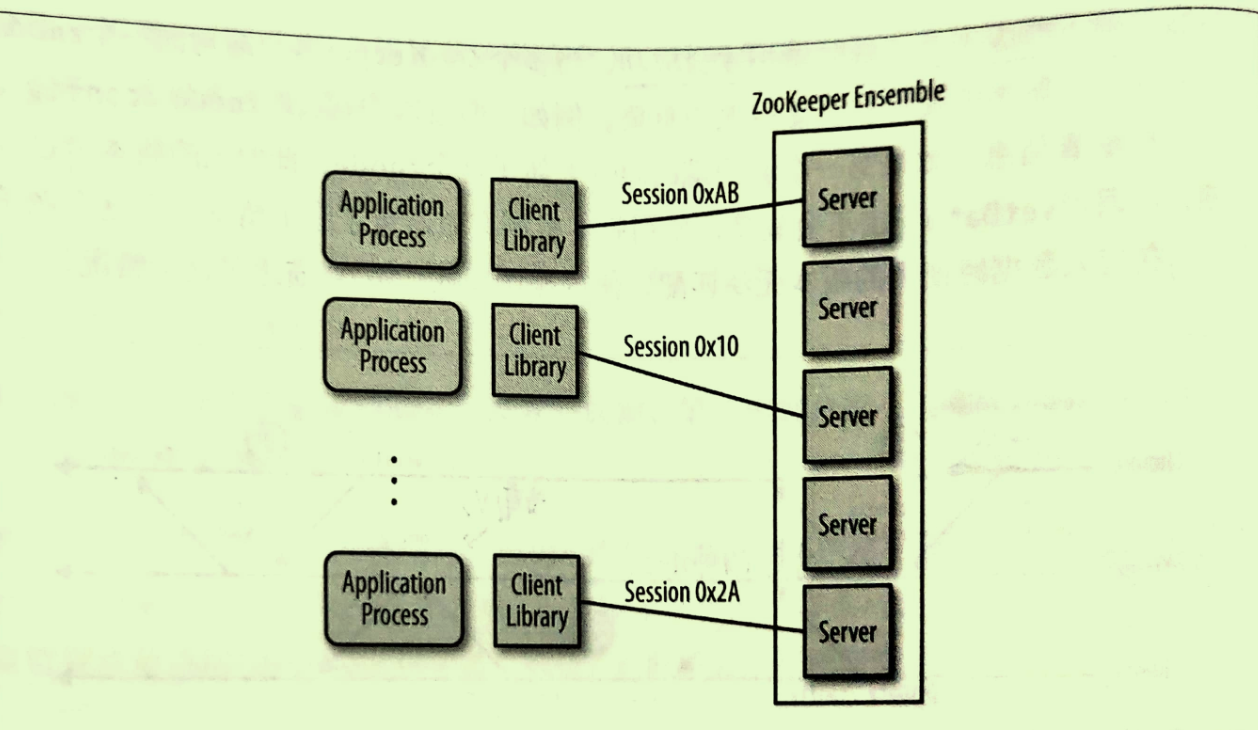
每个客户端导入客户端库,之后便可以与任何zookeeper节点进行通信。
7.1 zookeeper服务器模式
zookeeper服务器运行于两种模式下:独立模式和仲裁模式。
-
独立模式,就是字面意思,只有一个单独的服务器,zookeeper状态无法复制。
-
仲裁模式,就是有一组zookeeper服务器,被称为zookeeper集合(集群的概念),它们之间可以进行状态的复制,并同时为服务与客户端的请求。
在仲裁模式下,为了保持一致性,zookeeper会复制集群中的所有服务器的数据树。但是如果让一个客户端等待每个服务器完成数据保存后再继续服务,这延迟。。。你能接受么?我接受不了。
zookeeper为了解决这个问题,引入了法定人数等概念。法定人数是指为了使zookeeper正常工作,而必须有效运行的服务器的最小数量。例如,假如我们有5个zookeeper服务器,但法定人数为3个,这样,只要有任意三个服务器保存了数据,客户端就可以继续操作。而其他两个服务器最终也将捕获到数据,并保存数据。
7.2 会话
在zookeeper集合执行任何请求前。一个客户端必须先与服务器建立会话,客户端提交给zookeeper的所有操作均关联在一个会话上。当一个会话因某种原因而中止时,在这个会话期间创建的临时节点将会消失。
当客户端通过语言 API 创建一个zookeeper句柄(相当于sockek编程的文件描述符)时,它就会通过服务建立一个会话。如果说过了一段时间之后,这个服务器崩溃了,这个会话就会转移到另一个服务器上,这个对客户端来说都是透明的。
同时,会话提供了顺序保障,意味着同一个会话终端请求会以FIFO的顺序执行,但是如果客户端建立与服务器的多个并发会话的话,FIFO就无法保证了。
8 抓包判断zk有没有心跳机制
zk的session timeout为 30s。zkclient的网络IO线程,会以1/3的timeout时间发送ping消息,用来充当心跳包,确保zk和服务器保持连接,如果连接正常,timeout会刷新重新计时。
如何抓包查看到底有没有发送心跳包?
由于我的服务器和zk服务器在一台主机上,所以使用工具tcpdump抓本地回环地址,zk端口号:2181 sudo tcpdump -i lo port 2181 //lo(localhost)表示本地回环地址
下图表示正在发送心跳包。

9 zookeeper的特点(优点):
-
一致性: 数据一致性, 数据按照顺序分批入库
-
原子性: 事务要么成功要么失败
-
单一视图: 客户端连接集群中的任意zk节点, 数据都是一致的
-
可靠性:每次对zk的操作状态都会保存在服务端
-
实时性: 客户端可以读取到zk服务端的最新数据
10 Zookeeper的如何保证数据一致性/zk底层原理(ZAB)
zk的底层原理是ZAB算法,也就是原子广播协议,这个协议可以确保分布式系统中数据的一致性。
-
Why(与我何干?):在分布式系统中,数据一致性是关键。如果系统中的多个节点需要同步状态,ZAB算法确保了即使在部分节点失败的情况下,系统仍然能够保持一致的状态。
-
What(定义、概念解释,可以做什么):ZAB算法主要解决两个问题:领导者选举和事务处理。它通过确保所有节点对事务的顺序达成一致,来实现数据的一致性。
-
How(ZAB算法一般会进行这样几个步骤):
-
领导者选举:ZAB算法首先通过一个称为“领导者选举”的过程来确定一个主节点,这个主节点负责协调集群中的所有事务。
-
事务日志:领导者将事务记录在日志中,这个日志是所有变更的序列化记录。
-
广播:领导者将事务日志中的变更以原子广播的形式发送给所有跟随者。
-
同步:跟随者接收到变更后,在自己的日志中进行相应的更新,以保持与领导者的一致性。
-
提交:一旦跟随者确认了变更,并且领导者收到了足够的确认,变更就会被提交,成为集群的正式状态。
-
-
How Good(可以给听众带来什么好处,什么改变。):通过ZAB算法,ZooKeeper能够提供高性能、高可用性的数据同步服务。这对于构建需要强一致性和高可靠性的分布式应用至关重要。
11 领导者选举是如何选举的?
当原先的领导者所在的服务器宕机了,或者服务刚开始没有领导者的时候就会进行选举,确保在分布式系统中,即使某些节点失效,仍然能选出唯一的领导者并保持系统的一致性。
没有领导者的时候:
-
每个服务器节点都在启动时尝试成为领导者,并开始进行选举过程。
-
节点会进入LOOKING(寻找领导者)状态,并开始投票。
投票阶段:
-
每个节点会向其他所有节点发送一个投票消息,投票内容包括自己的ID、ZXID(事务ID,表示最近的事务日志的最大ID)、epoch(投票轮次,确保选举过程中不会出现重复的领导者)。
-
节点接收到投票消息后,会对比投票消息中的ZXID和epoch,按照一定的规则决定是否改变自己的投票。
投票规则:
-
节点会比较接收到的投票和当前自己的投票,按照以下优先级顺序进行比较:
-
比较epoch值,epoch值越大,表示投票越新。
-
如果epoch值相同,比较ZXID,ZXID越大,表示节点的数据越新。
-
如果ZXID相同,比较服务器ID,服务器ID越大,优先级越高。
-
-
如果接收到的投票比当前投票更优,则更新自己的投票。
投票统计:
-
每个节点会统计接收到的投票情况,超过半数节点投票给同一个节点,则该节点被选为领导者。
-
一旦选出领导者,所有节点会更新状态,从LOOKING状态转为FOLLOWING(追随者)或LEADING(领导者)状态。
领导者宣布:
-
选举出的领导者会进行一次广播,告知所有节点选举结果,并进入领导者角色,开始进行Zookeeper集群的事务处理。
-
追随者节点接收到领导者的广播后,切换到FOLLOWING状态,并开始同步领导者的状态。
12 ZooKeeper的缺点
Zookeeper原生提供了C和Java的客户端编程接口,但是使用起来相对复杂,几个缺点:
-
Zookeeper 由于其核心算法是 ZAB,主要适用于分布式协调系统(分布式配置、集群管理等场景)。当 master 节点故障后,剩余节点会重新进行 leader 选举,导致在选举期间整个 Zookeeper 集群不可用。
-
zookeeper的watch事件,是一次性触发的,当watch监视的数据发生变化时,通知设置了该watch的client,即watcher,由于zookeeper的监控都是一次性的,所以每次必须设置监控。
-
znode节点只存储简单的byte字节数组,如果存储对象,需要自己转换对象生成字节数组。
13 为什么用zookeeper充当注册中心/zookeeper的好处
-
zookeeper注册中心它保存了能提供的服务的名称,以及URL。首先这些服务会在注册中心进行注册,当客户端来查询的时候,只需要给出名称,注册中心就会给出一个URL。所有的客户端在访问服务前,都需要向这个注册中心进行询问,以获得最新的地址。
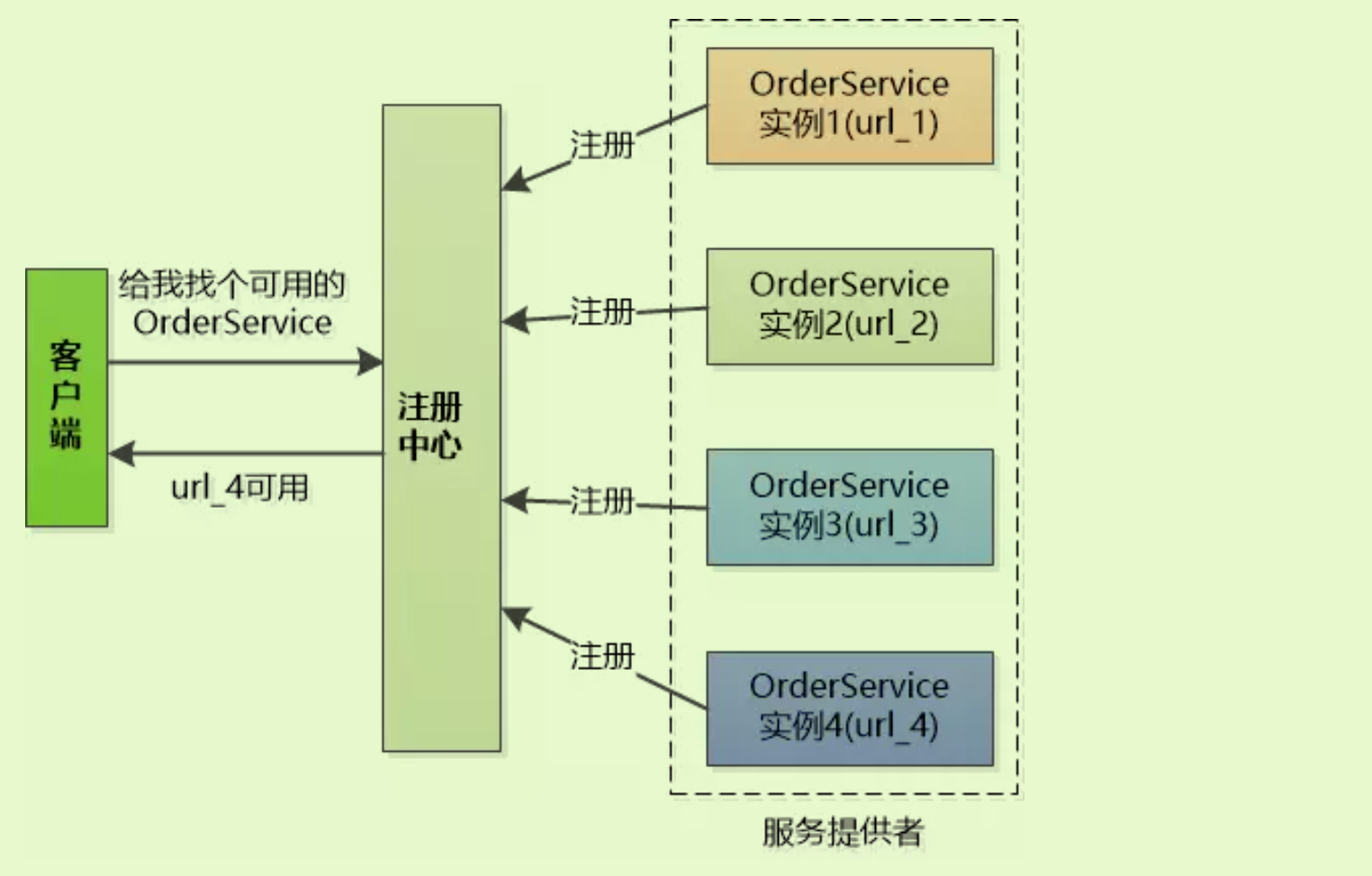
-
zookeeper注册中心和各个服务实例直接建立Session,要求实例们定期发送心跳,一旦特定时间收不到心跳,则认为实例挂了,删除该实例。
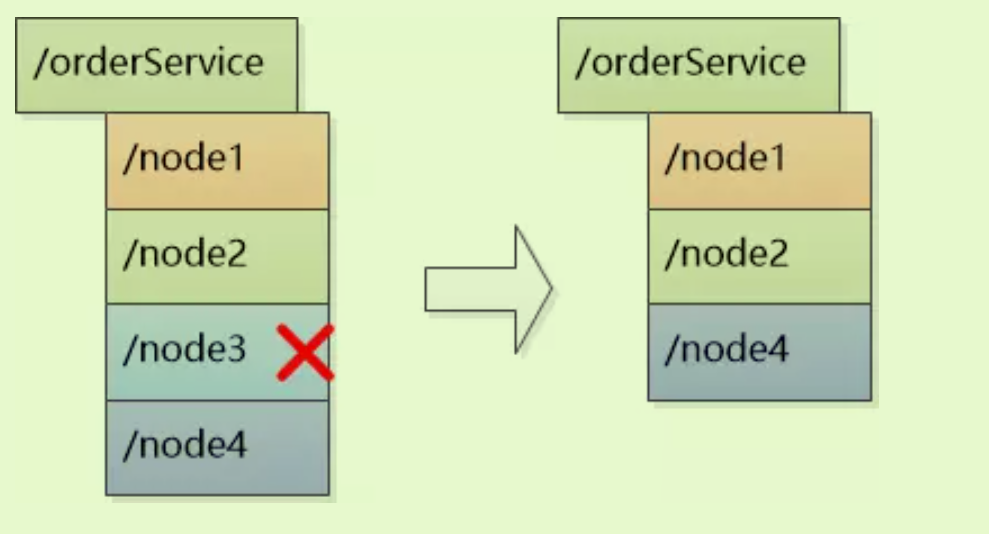
-
Zookeeper 通过 znode 节点来存储数据。因此我们可以利用这一特性进行服务注册,节点用于存储服务 IP、端口、协议等信息。
例如:服务提供者上线时,Zookeeper 创建该节点 - /provider/{serviceName}:{ip}:{port}
-
Zookeeper提供了Watcher机制,可以监听相应的节点路径。可以利用这一机制监听对应的路径,一旦路径上的数据发生了变化,就向其他订阅该服务的服务发送数据变更消息。收到消息的服务便去更新本地缓存列表。
-
Zookeeper提供心跳检测功能(zk会每隔1/3TimeOut时间,使用ping命令发送心跳消息。),定时向各个服务提供者发送心跳请求,确保各个服务存活。如果服务一直未响应,则说明服务挂了,将该节点删除。
-
Zookeeper 遵循一致性原则,对于注册中心而言,最重要的是可用性,我们需要随时能够获取到服务提供者的信息,即使它可能是几分钟以前的旧信息。
-
master节点选举, 主节点down掉后, 从节点就会接手工作, 并且保证这个节点是唯一的,这也就是所谓首脑模式,从而保证我们集群是高可用的,但是这带来的问题就是:当 master 节点故障后,剩余节点会重新进行 leader 选举,导致在选举期间整个 Zookeeper 集群不可用。
14 ZooKeeper的其他功能
ZK优秀的功能很多,比如分布式环境中Job协调问题,分布式锁,配置中心。但是这个项目中并没有使用到,所以我没有去深入研究这些功能,只知道一个基本的概念。
-
Job协调问题:
-
比如有三个job,他们功能相同,部署在三个不同的机器上,要求同一时刻只有一个可以运行,而且如果其中一个宕机了的话,需要在剩下两个中选举出一个Master(首领)继续工作。这里面就涉及到协调问题了。
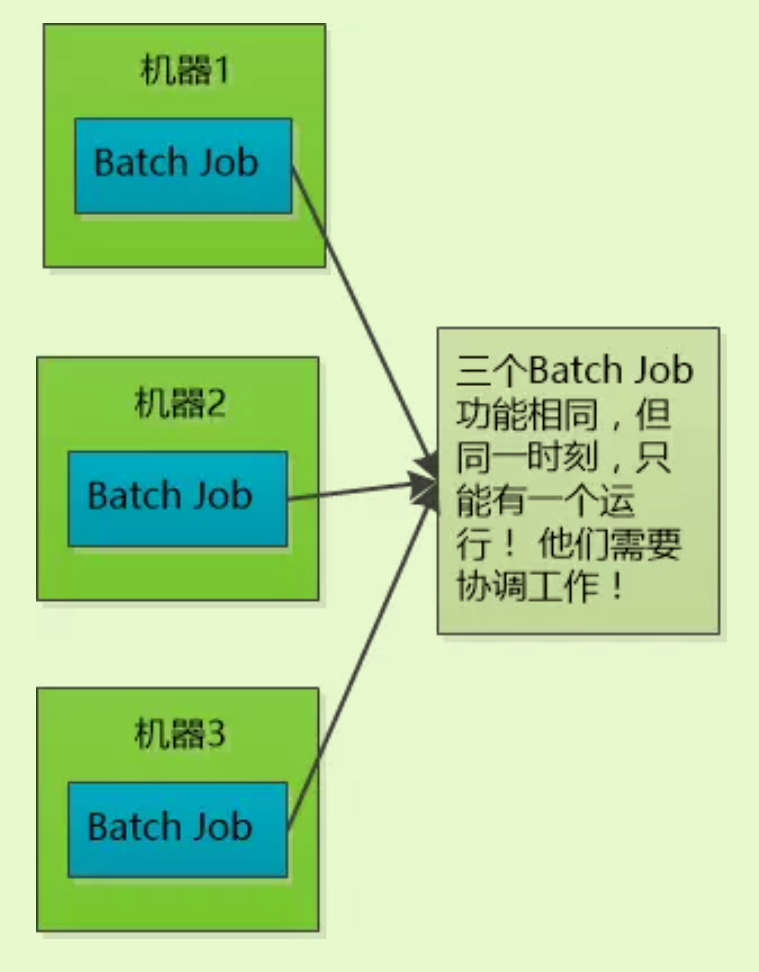
-
具体协调有两种方式:
-
使用共享数据库表。因为数据库主键不能冲突,可以让三个Job向表中插入同样的数据,谁成功谁就是Master。缺点是如果抢到Master的Job挂了,则记录永远存在,其他的Job无法插入数据。所以必须加上定期更新的机制。
-
让Job在启动之后,去注册中心注册,也就是创建一个临时znode,谁成功谁是Master(注册中心必须保证只能创建成功一次)。
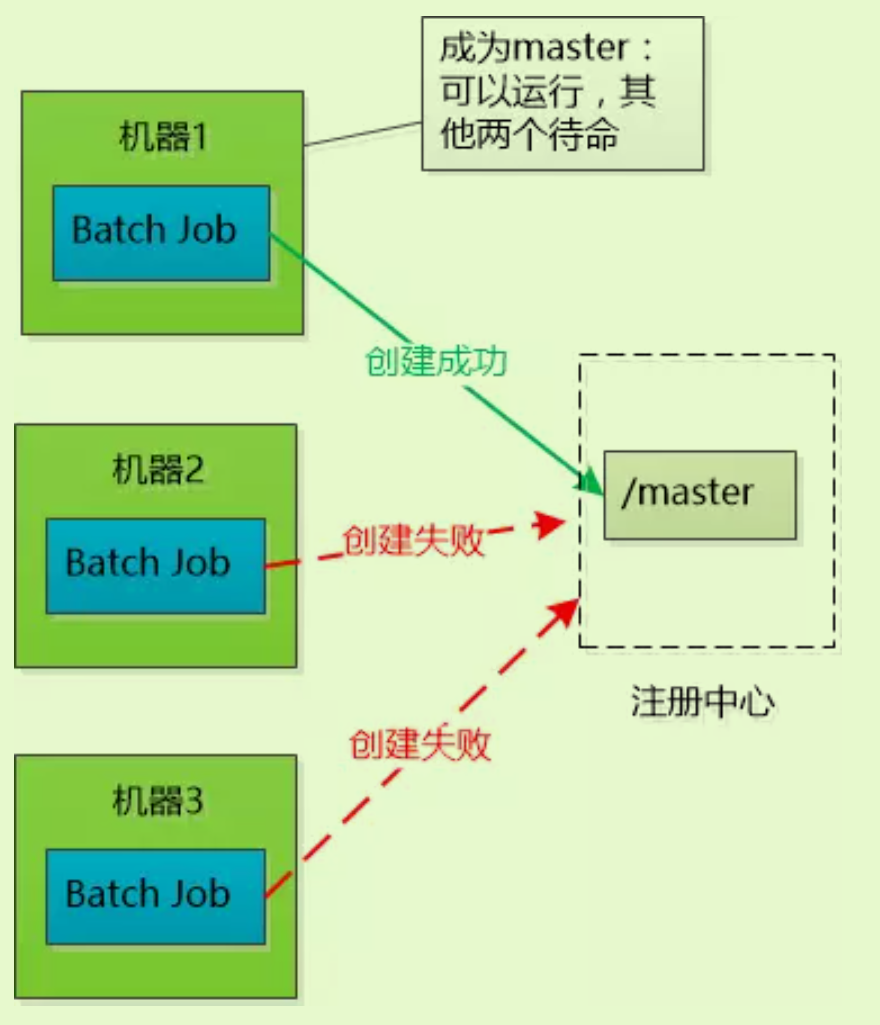
-
-
如果某个机器挂了,由于临时节点在服务宕机后会自动删除,就会继续开始新的一轮争夺,谁成功谁就是新的Master。
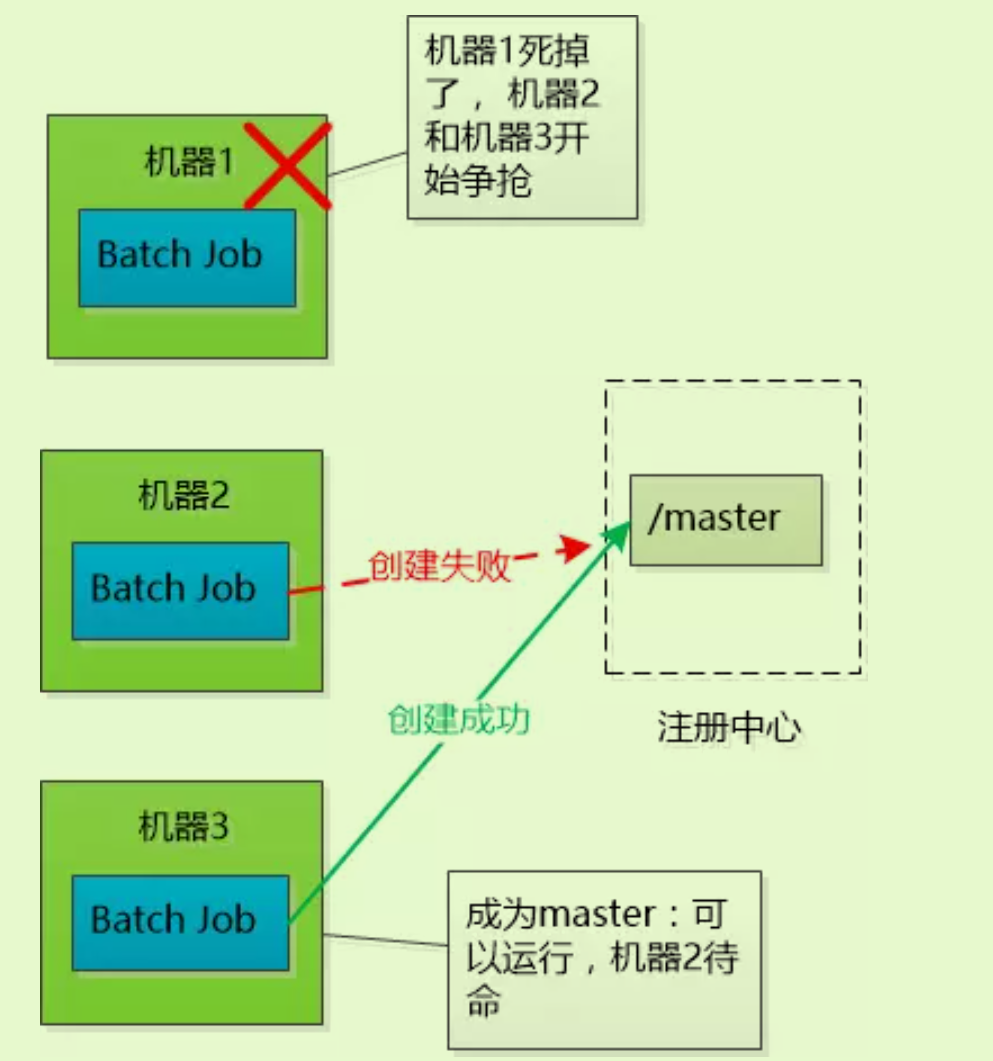
-
-
分布式锁:
当多台机器上运行的不同系统,操作统一资源时,可能会产生冲突,就需要使用分布式锁。
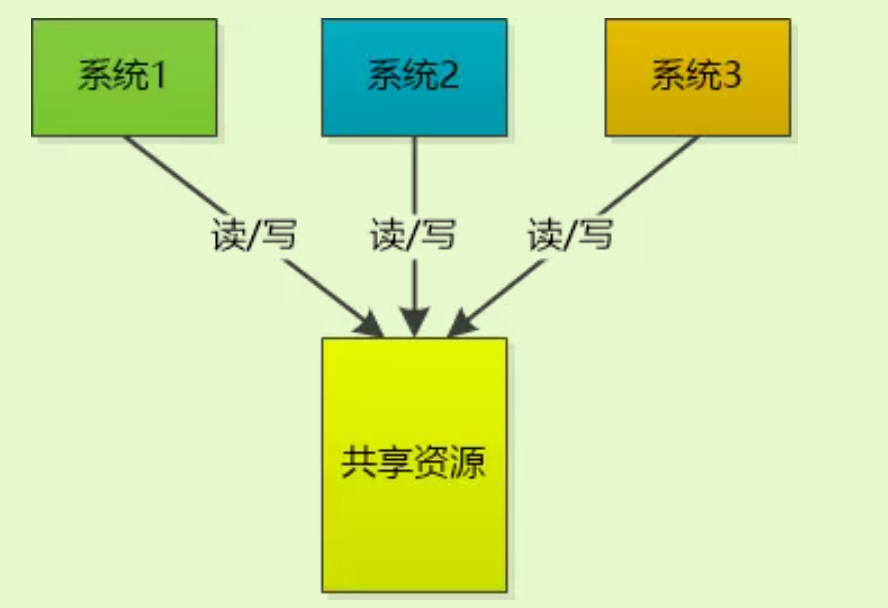
zookeeper使用分布式锁主要有两种方式:
-
使用临时节点:使用Master选举的方式,让大家去抢,谁能抢到就创建一个
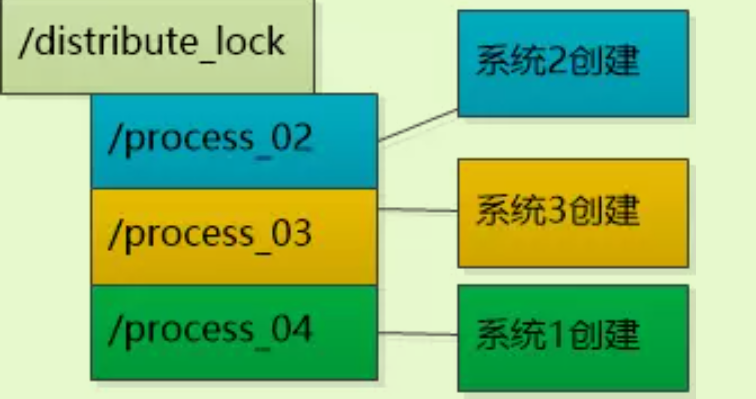
/distribute_lock节点,文件读写完以后就删除这个节点,让大家再来抢。但是某个系统可能多次抢到,锁不够公平。 -
使用顺序临时节点:为了实现公平锁,可以使用另一种节点:顺序临时znode节点,这种节点是临时的,并且创建的时候是顺序的。让每个系统在注册中心的
/distribute_lock下创建顺序临时节点,根据创建的顺序不同,系统对应的临时节点编号也不同,然后让每个系统检查自己的编号,谁的编号小谁就被认为持有了锁,比如系统1编号最小,他就持有了锁,可以对数据进行操作。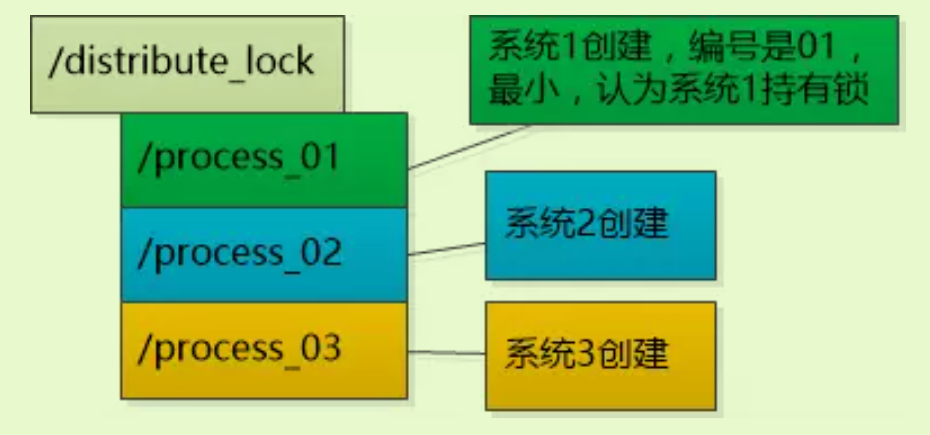
-
系统1操作完成以后,就可以把znode1删除了,然后系统1再创建一个新的节点,编号为znode4。此时znode2变成了最小的编号,所以认为系统2持有了锁,然后就这样不断循环往复。
-

















 1700
1700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









