






python爬虫基础
1、爬取网页的通用代码框架
通用代码框架可以使爬取网页变得更稳定有效。用requests库访问网页时不一定能成功,异常处理很重要。产生的异常如下所示:
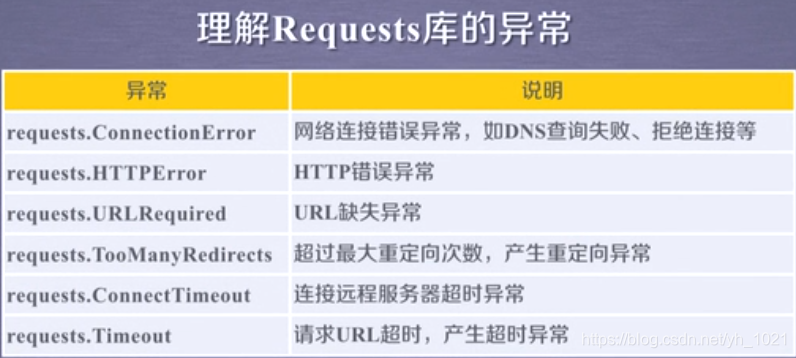
可以用r.raise_for_status 检测访问是否成功, 如果返回值是200,则访问正确,若不是200,则访问错误

2、http协议及requests库方法

http协议是一个基于“请求与响应”模式的、无状态的应用层协议,用户发起请求,服务器做相关响应,无状态指第一次和第二次请求之间无关联。


用户从网上获取信息 用GET和HEAD ,将信息传至网上用PUT 、POST、PATCH、DELETE。
request库访问网页后查看的信息
- r.status_code 查看请求的返回状态 200表示连接成功
- r.text http响应内容的字符串形式
- r.encoding http header中猜测的响应内容编码方式
- r.apparent_encoding 从内容中分析出响应内容编码方式 utf-8可以解析中文
- r.content http响应内容的二进制形式
requests库的方法
- requests.head 返回头部信息的内容
- requests.post向服务器提交新增的数据,可以利用字典的形式
- requests.put 与post相同,可以将原有的数据覆盖掉
3、Requests库主要方法解析

method就是GET、HEAD等七个方法,kwargs为控制访问的参数,有以下几种
-
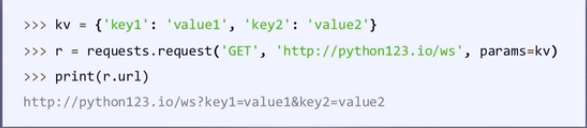
params:字典或字节序列,作为参数增加到url中
-
data,字典、字节序列或文件对象,作为request的内容

-
json,JSON格式的数据,作为request的内容

-
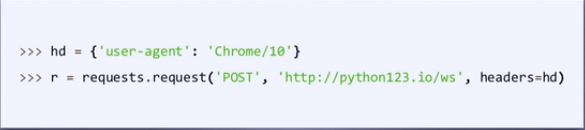
headers:字典,HTTP定制头
-
cookies:字典或cookieJar,Request中的cookie
-
auth:元组
-
file:字典类型,传输文件(用open打开文件并与file作关联对应到url上),用于向某个链接提交某个文件

-
timeout:设定超时时间,秒为单位,若在时间内没有返回值,则异常
-
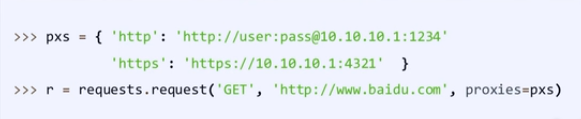
proxies:字典类型,设定访问代理服务器,可以增加登录认证
-
allow_redirects:True/False,重定向开关
-
stream: True/False,获取内容立即下载开关
4、爬虫实例
(1)亚马逊网站
import requests
r=requests.get('https://www.amazon.com/Vega-Protein-Powder-Chocolate-Servings/dp/B01LXZS18X?ref_=Oct_DLandingS_PC_3624ec96_NA&smid=ATVPDKIKX0DER')
print(r.status_code)
print(r.encoding)
r.encoding=r.apparent_encoding
print(r.request.headers)
kv={'user-agent':'Mozilla/5.0'}
url='https://www.amazon.com/Vega-Protein-Powder-Chocolate-Servings/dp/B01LXZS18X?ref_=Oct_DLandingS_PC_3624ec96_NA&smid=ATVPDKIKX0DER'
r=requests.get(url,headers=kv)
print(r.status_code)
print(r.request.headers)
输出:
503
ISO-8859-1
{'User-Agent': 'python-requests/2.18.4', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
200
{'user-agent': 'Mozilla/5.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
第一次访问网站时r.status_code返回503表示访问错误,查看r.request.headers可以看到访问请求的headers中’User-Agent’: ‘python-requests/2.18.4’,表示向亚马逊网站访问时使用的是requests方式,网站有反爬虫措施。所以需要改变headers,利用字典方法,将头部改成浏览器Mozilla/5.0的方式进行访问,可以看到返回200表示成功访问。
(2)百度360关键词搜索
百度用关键词搜索时的网址为http://www.baidu.com/s?wd=python,关键词为wd等号后面的词,所以用字典方式代替键的值。360中只需将wd改成q
import requests
kv={'wd':'python'}
r=requests.get('http://www.baidu.com/s',params=kv)
print(r.status_code)
print(r.request.url)
print(len(r.text))
输出
200
http://www.baidu.com/s?wd=python
437908
(3)图片爬取和储存
import requests
import os
root='D:/1.jpg/'
url='https://ss3.bdstatic.com/70cFv8Sh_Q1YnxGkpoWK1HF6hhy/it/u=3142343904,631493091&fm=26&gp=0.jpg'
path=root+url.split('/')[-1]
try:
if not os.path.exists(root):
os.makedirs(root)
if not os.path.exists(path):
r=requests.get(url)
print(r.status_code)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print('文件保存成功')
else:
print('文件已存在')
except:
print("爬取失败")
5、Beautiful Soup库
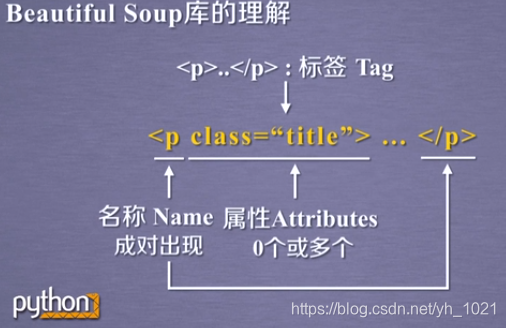
p为标签的名称, class和“title”构成的键值对为标签的属性


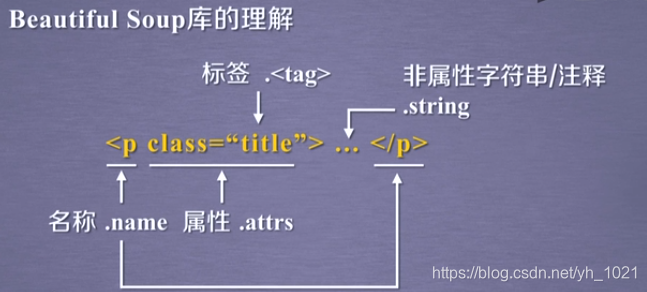
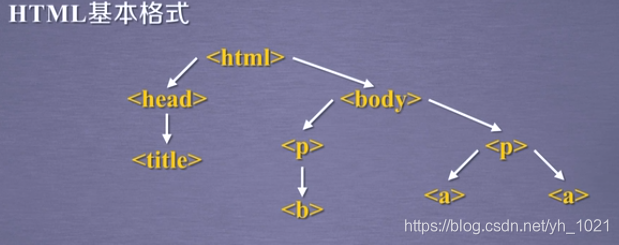

例如:soup.body.contents 返回的是所有的body的子节点p的列表


平行遍历发生在同一个父节点下的各个节点之间
平行遍历也可能出现标签之间的string类型,并不一定都出现标签
bs4库中的prettify方法可以将html的标签之间增加换行符,打印更直观,也可以对每一个标签进行格式化
6、信息标记三种形式
(1)介绍
- XML
- JSON
- YAML
①XML(标签标记)

②JSON(有类键值对标记)

单个值时, “key”:“value”;
多个值时,“key”:[“value1”,“value2”];
键值对中嵌套键值对, “key”:{“subkey”:“subvalue”}
③YAML(无类键值对标记)




(2)对比



XML:可扩展性好,复杂(Internet信息交互)
JSON:信息有类型,适合程序处理,较XML简洁(移动应用云端和节点信息通信,可作为程序中一部分,无注释)
YAML:信息无类型,文本信息比例高,可读性好(系统配置文件,有注释易读)
(3)信息提取方法
例如 提取HTML中所有URL链接:
①搜索到所有标签
②解析标签格式,提取href后的链接内容
(4)基于bs4库的HTML内容查找方法
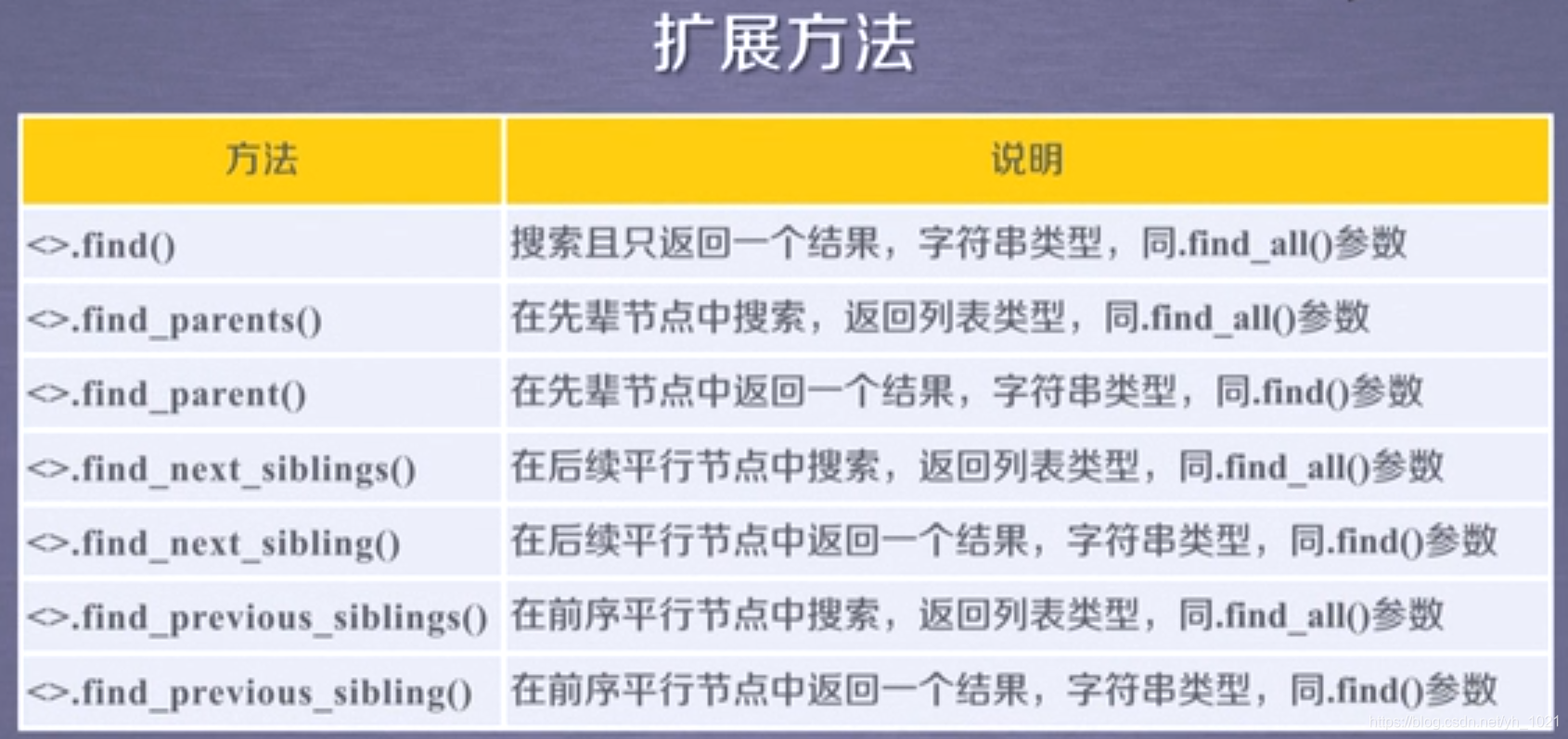
1)find_all方法
find_all(name,attrs,recursive,string,kwargs)
- name:需要检索的标签名称,是个字符串,用“”
- attrs:需要检索的标签属性值,是字符串 。例如find_all(‘p’,‘course’),就能找到标签名为p,标签属性值为course的标签
sub_url=soup.find_all("a",{"target":"_blank","href":re.compile("/item/(%.{2})+$")})
上面代码为找到标签为a,且属性target的值为_blank和属性href的值为一个正则表达式的所有标签。(正则表达式可以用于查找包含属性部分信息的标签,如果直接检索标签属性值则需要全部的属性信息)
- recursive: 是否对子孙全部检索,默认True
- string:<>…</>中字符串区域的检索字符串(利用正则表达式可以检索到包含部分字符串的列表)
2)soup(…)=soup.find_all(…) 或者<标签>(…)=<标签>.find_all(…)
7、例:爬大学排名
from bs4 import BeautifulSoup
import requests
import bs4
#获取url信息,输出内容
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
#将信息提取并放到列表中
def UniverList(ulist,html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag): #检测是否为bs4库中的标签(Tag)类型,不是的话过滤掉
tds=tr('td')
ulist.append([tds[0].string,tds[1].string,tds[3].string])
#将列表中信息打印前num个信息,需要格式化输出
def print_list(ulist,num):
tplt="{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校","得分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0], u[1], u[2],chr(12288)))
def main():
uinfo=[]
url='http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html'
html=getHTMLText(url)
UniverList(uinfo,html)
print_list(uinfo,40)
main()
输出表格时,当中文字符宽度不够时,会采用西文字符填充,而中西文字符所占宽度不同,所以输出的对其效果差 。要采用中文字符的空格填充 ,采用中文字符的空格填充的代码为chr(12288),
tplt="{0:^10}\t{1:{3}^10}\t{2:^10}" 为输出模板。
该操作在中文输出排版时很有用!
8、正则表达式
正则表达式是一种通用的字符串表达框架,是用于简洁表达一组字符串的表达式,可以判断某字符串的特征归属。它的编译过程是将符合正则表达式语法的字符串转换成正则表达式特征。
- 表达文本类型的特征
- 同时查找或替换一组字符串
- 匹配字符串的全部或部分
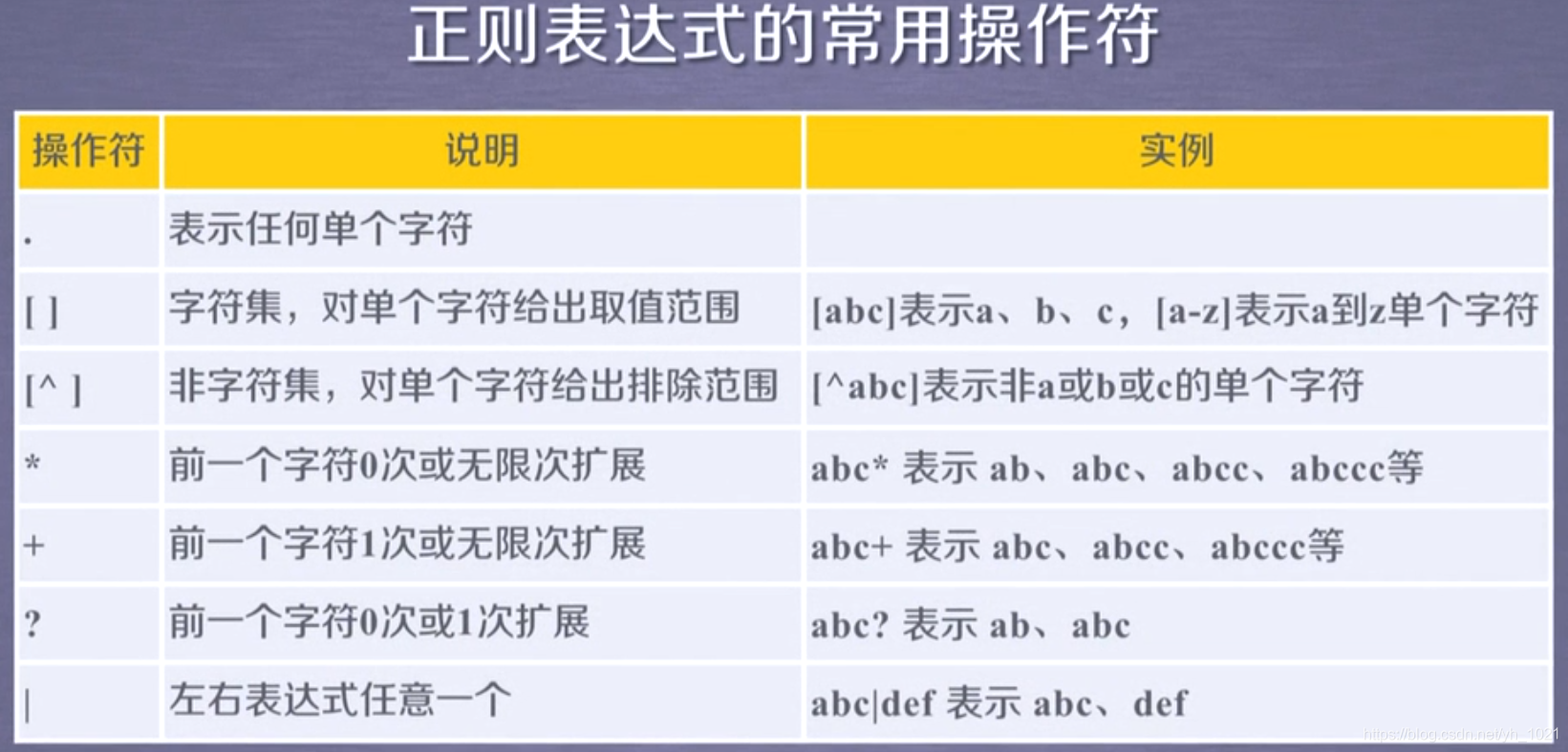
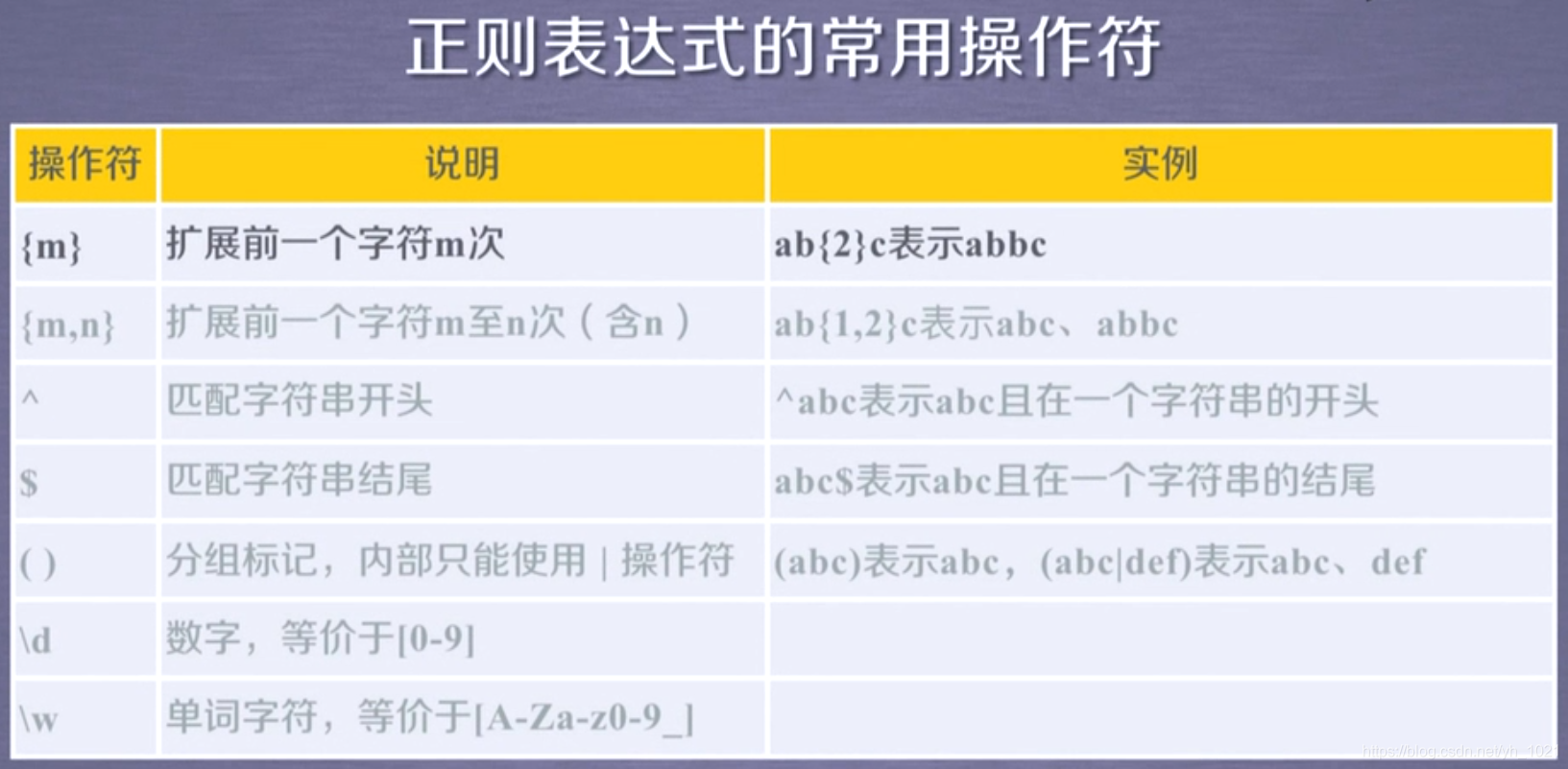

^[A-Za-z]+$ 表示由26个字母开始,再由26个字母结束,中间字母可以扩展多次
^-?\d+$ 表示整数形式的字符串,-?表示:没有-时为正,有-为负,\d+为0-9数字扩展
[1-9]\d{5} 表示邮政编码,[1-9]是因为第一个数字不能为0,\d{5}表示后面有五个0-9的数字
[\u4e00-\u9fa5] 匹配中文字符
\d{3}-\d{8}|\d{4}-\d{7} 国内电话号码,010-88888888 或者0571-8989898
0-99:[1-9]?\d 100-199:1\d{2}
9、Re库使用
(1)正则表达式表示类型
raw string类型
re库采用raw string类型表示正则表达式,表示为r’text’,r’[1-9]\d{5} ’
(2)Re库主要功能函数

①(match对象)


②(match对象)

使用re.match时会从匹配的字符串的开始位置进行匹配,若起始位置的字符串不同,则无匹配结果。
③

④

将与正则表达式匹配的部分去掉后,剩下的部分放入列表中,maxsplit=1表示只匹配和分割第一个,剩下的按照完整类型直接输出
import re
match=re.split(r'[1-9]\d{5}','BIT100081 TSU100084')
print(match)
输出:['BIT', ' TSU', '']
match=re.split(r'[1-9]\d{5}','BIT100081 TSU100084',maxsplit=1)
['BIT', ' TSU', '']
⑤(match对象)

可以循环输出匹配的结果,每个结果都是match类型,可以通过match.group(0)查看元素
import re
for m in re.finditer(r'[1-9]\d{5}','BIT100081 TSU100084'):
if m:
print(m.group(0))
输出:
100081
100084
⑥

用zipcode匹配与正则表达式匹配的字符串部分
import re
match=re.sub(r'[1-9]\d{5}',':zipcode','BIT100081 TSU100084')
print(match)
输出:
BIT:zipcode TSU:zipcode
(3)面向对象的用法
等价于match=re.search(r'[1-9]\d{5}','BIT 100081'),pat的方法与re.search等六个方法相同
pat=re.compile(r'[1-9]\d{5}')
rst=pat.search('BIT 100081')
print(rst.group(0))
经过一次编译,就可以多次对正则表达式进行使用和匹配

10、Re库的match对象


import re
m=re.search(r'[1-9]\d{5}','BIT100081 TSU100084')
print(m.string)
print(m.re)
print(m.pos)
print(m.group(0))
print(m.start())
输出:
BIT100081 TSU100084
re.compile('[1-9]\\d{5}')
0
100081
3
11、Re库的贪婪匹配和最小匹配
(1)贪婪匹配
Re库默认采用贪婪匹配方式,即当有多个匹配方式时,输出匹配最长的子串
match=re.search(r'PY.*N','PYANBNCNDN')
print(match.group(0))
输出:
PYANBNCNDN
(2)最小匹配
对原有的操作符进行扩展,比如原来是*,当*?时返回最小匹配(在操作符后面加上问号可以返回最小匹配)

match=re.search(r'PY.*?N','PYANBNCNDN')
print(match.group(0))
输出:PYAN
12、百度图片爬虫
百度图片的网页是一个动态页面,它的网页原始数据其实是没有图片的,通过运行JavaScript,把这个图片数据插入到网页的html标签里面,那这样造成的结果是,我们在开发者工具中虽然能看到这个html标签,但实际上,当我们在看网页的原始数据的时候,其实是没有这个标签的,它只在运行时加载和渲染,我们需要找到它的Json数据,可以看到图片链接的标签为objURL,所以只需通过正则表达式找到标签objURL对应的url。并且通过翻页可以看到word=后面是所查询的关键词名字,pn=表示第几页,pn=0表示第一页,pn=20表示第二页以此类推,所以可以清楚的得到每一页图片的url。
import re
import requests
import os
Num_pic=30
def getHtml(url):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def DownloadPic(html,word,plus,k):
pic_url=re.findall('"objURL":"(.*?)",', html, re.S)
i=1
print("现在开始下载第%s个网页的图片"%k)
for num,i in enumerate(pic_url):
try:
pic=requests.get(i,timeout=10)
pic.raise_for_status()
pic.encoding=pic.apparent_encoding
except:
continue
if not os.path.exists(word):
os.makedirs(word)
with open(word+'/%s.jpg'%(num+1+plus),'wb') as f:
for chunk in pic.iter_content(chunk_size=128):
f.write(chunk)
print("图片%s下载完成"%(num+plus+1))
if num+plus+1==Num_pic:
break
return (num+plus+1)
if __name__ == '__main__':
word=input("请输入要查询的内容:")
for i in range(10):
num=i*60
pn=str(i*20)
url='http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='+word+'&pn='+pn+'&gsm=8c&ct=&ic=0&lm=-1&width=0&height=0'
# url='http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='+word+'&ct=201326592&v=flip'
html=getHtml(url)
NumOfPic=DownloadPic(html,word,num,i+1)
if Num_pic==Num_pic:
break
若所查找的关键词没有对应的文件夹,会新建该文件夹并下载图片。

















 4885
4885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









