




 本文探讨了PyTorch与Keras训练模型的区别,特别是在一维卷积神经网络(CNN)对一维连续数据分类任务中的应用。作者在PyTorch中实现了一维CNN,处理电机故障检测的九分类问题,分享了在数据处理、模型构建和训练过程中的经验,包括通道维度的调整、数据打乱的重要性以及训练曲线的绘制。文章强调了PyTorch在灵活性和自定义方面的优势。
本文探讨了PyTorch与Keras训练模型的区别,特别是在一维卷积神经网络(CNN)对一维连续数据分类任务中的应用。作者在PyTorch中实现了一维CNN,处理电机故障检测的九分类问题,分享了在数据处理、模型构建和训练过程中的经验,包括通道维度的调整、数据打乱的重要性以及训练曲线的绘制。文章强调了PyTorch在灵活性和自定义方面的优势。
卷积神经网络对于周期性的一维信号分类效果是比较好的,本人做电机故障检测,需要对不同故障的轴承振动信号进行分类。
之前都是用keras搭建神经网络,确实很方便,使用fit()函数训练模型确实很省事。但是fit()函数不太灵活,如果想对网络中间层输出特征操作的话好像是不行的(博主也是初学者,如果有大佬知道keras或者tensorflow如何对中间输出特征操作的话还望不吝赐教)。所有,最近看了一下pytorch,并用pytorch搭建了一维卷积神经网络对凯斯西储大学数据集进行分类。在过程中也踩了一些雷,在这边也分享出来。
我选择的数据为空载工况下,外圈故障、内圈故障、滚动体故障三种故障类型,每种故障类型有三个故障深度,所以模型要处理一个9分类任务。下图是我用的数据集。
首先说我踩得第一个坑
在keras中通道数排在最后,比如通过数据预处理程序之后我得到的训练数据和标签形状为(5400,1024),(5400,9),训练数据中5400是样本数,1024是单个样本长度,训练标签中的9是九分类的独热编码。

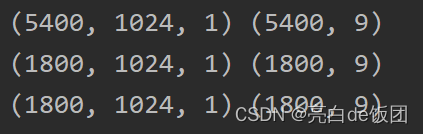
在keras中需要插入一个通道维度,并且通道维度在最后,也就是我上图这个样子。但是在pytorch中,通道数所在的位置在批维度之后。比如(32,1,1024)为(一批样本数,通道数,数据长度)。所以要正确插入通道维度。
此外,在pytorch中输入数据要转化成张量形式,在keras中就不需要这个操作,fit会自动处理。方法如下:
class MyDataset(Dataset):
def __init__(self, X, Y):
self.data_x = torch.FloatTensor(X, ).unsqueeze(dim=1)
self.data_y = torch.FloatTensor(Y, )
self.len = X.shape[0]
pass
def __getitem__(self, index):
return self.data_x[index],self.data_y[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1535
1535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









