



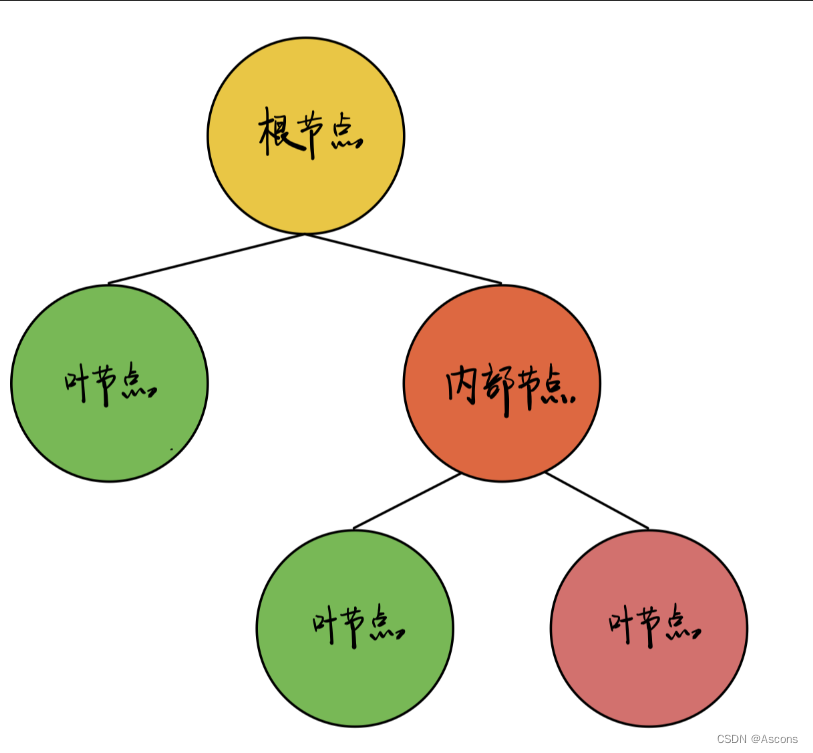
介绍决策树的基本概念及其结构。
决策树是一种基本的机器学习算法,广泛用于分类和回归任务。想象一下,一棵树的结构,根节点代表决策的起点,内部节点则是我们用来分类的特征,而叶子节点则是最终的决策结果。这种结构不仅直观,而且易于理解,简直就像在玩一个选择冒险游戏!
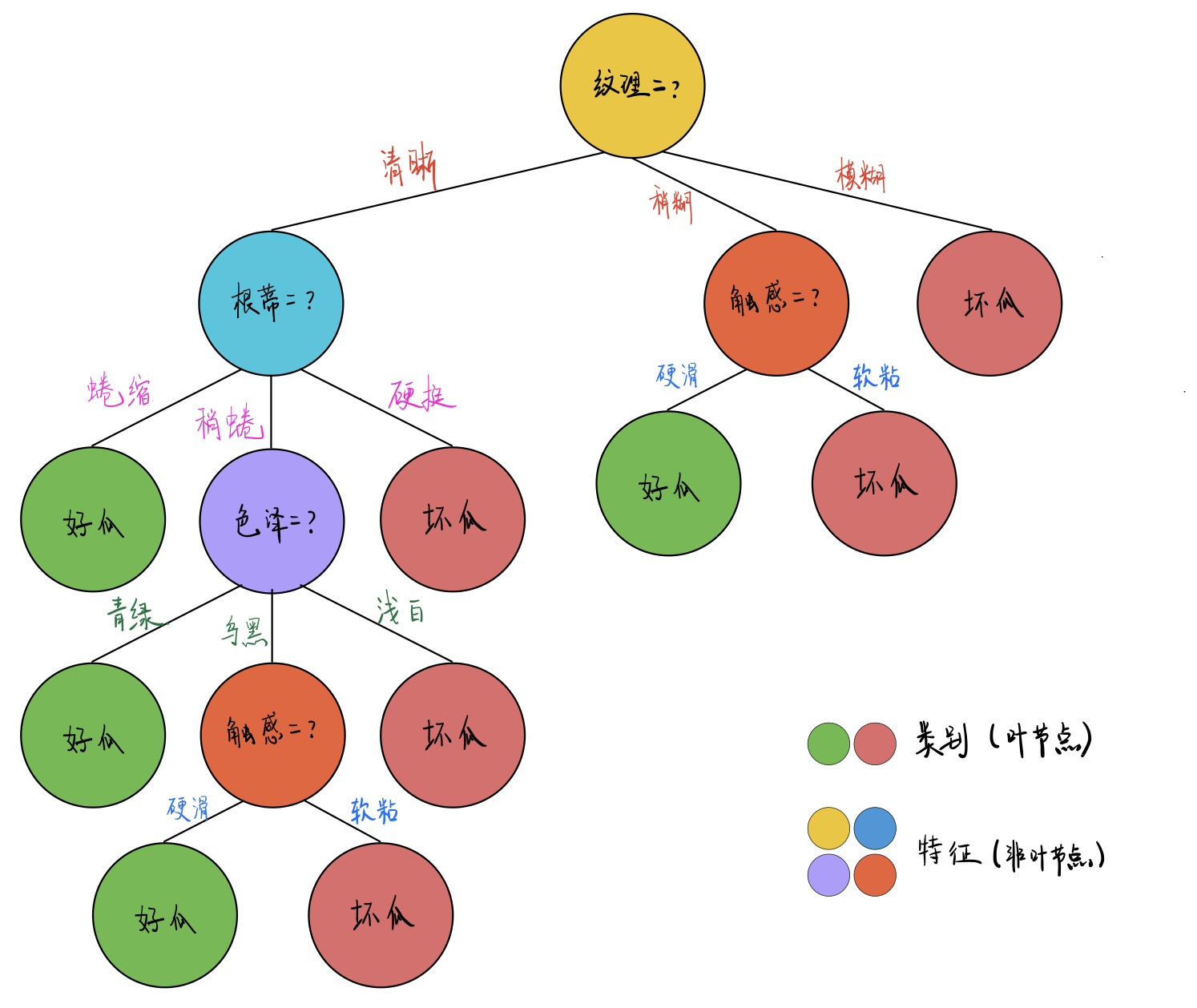
详细讲解决策树的构建过程,包括特征选择、节点分裂和递归建立。
那么,决策树是如何构建的呢?让我们一步一步来看看:
- 特征选择:每次选择最优特征进行划分。我们常用的信息增益、信息增益比和基尼指数等算法,帮助我们找到最能区分数据的特征。
- 节点分裂:根据选择的特征将样本数据分成不同的子集,形成树的分支。就像在选择不同的路径,最终指向不同的结果。
- 递归建立:对于每个子集,重复以上步骤,直到满足停止条件,比如所有样本属于同一类,或者达到最大深度等。这样,我们就能得到一棵完整的决策树!
分析决策树的优缺点,帮助读者全面理解其特性。
当然,决策树也有它的优缺点:
优点:
- 直观易懂:决策树的结构清晰,便于理解和解释。即使是非专业人士也能轻松上手。
- 无需数据预处理:不需要标准化数据,也能处理缺失值,这让我们的工作变得更加简单。
缺点:
- 易过拟合:决策树容易在训练数据上过拟合,导致泛化能力下降。我们需要小心,避免让树变得过于复杂。
- 敏感性:对数据的微小变化敏感,可能导致不同的树结构。这就像在微风中摇摆的树,稍有风吹草动,树的形状就会改变。
介绍决策树在不同领域的应用,展示其广泛性。
决策树被广泛应用于多个领域,真的是无处不在!例如:
- 银行信贷:评估贷款申请的风险,帮助银行做出明智的决策。
- 媒体推荐:通过用户行为分析,提供个性化的内容推荐,让用户体验更佳。
- 医疗诊断:根据病症和检查结果进行分类,帮助医生做出更准确的诊断。
总结决策树的优势及其在数据科学中的重要性。
决策树作为一种强大的分类算法,在许多实际问题中表现出色。通过调整参数来防止过拟合,决策树可以成为高效的机器学习工具。它的可解释性使得它在数据科学领域备受青睐。常常利用决策树来解决各种复杂问题,帮助我们更好地理解数据背后的故事。

















 55
55

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









