



 本文介绍PyTorch中Multi-Head Attention模块的工作原理及其使用方法。该机制通过将Query、Key和Value向量并行处理来加速计算,并允许模型关注不同位置的信息。文中详细解释了输入输出参数含义及示例。
本文介绍PyTorch中Multi-Head Attention模块的工作原理及其使用方法。该机制通过将Query、Key和Value向量并行处理来加速计算,并允许模型关注不同位置的信息。文中详细解释了输入输出参数含义及示例。
所谓Multi-Head Attention其实是把QKV的计算并行化
我们先不考虑其并行化的 计算过程,只关注他的输入输出。
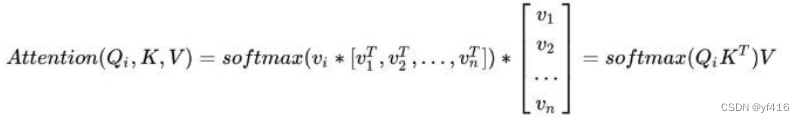
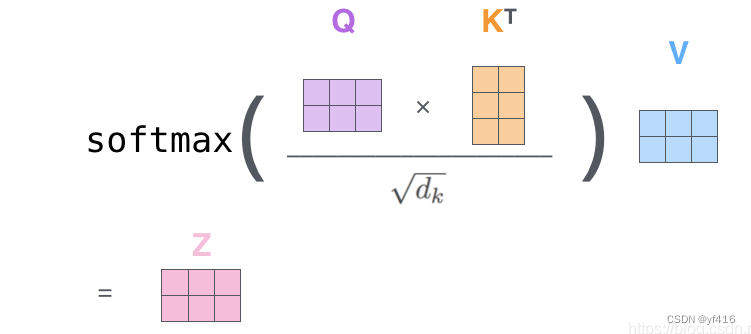
上面两个图,图一是对第 i 个词执行注意力机制的过程。
再看更直观的第二个, 其中每个词的q,k,v向量编码长度都为3,一共有2个词,所以矩阵都是2*3格式。z 即是两个词经过注意力机制后得到的新编码。
nn.MultiheadAttention()的参数:
embed_dim:是每一个单词本来的词向量长度;
num_heads:是我们MultiheadAttention的head的数量。
forward()函数的输入参数:
query(L,N,E) L 指的是输出目标序列的长度,N 就是batch_size, E 就是每个单词的embedding 维度大小
key(S,N,E) S 指的是输入目标序列的长度(也就是max_seq_length),N 就是batch_size, E 就是每个单词的embedding 维度大小
value(S,N,E) ,S 指的是输入目标序列的长度,N 是 batch_size, E 是embedding的维度
输出:
attn_output(L,N,E):即这些词的新编码
attn_output_weight(N,L,S):即在计算过程中得到的权重矩阵 (上图中的权重矩阵大小为2*2)
值得注意的是,L,S不相同时,比如L=3,S=2,就代表着对这 3 个词计算新编码时,只考虑它们与 2 个词的关系。
使用示例:
import torch
import torch.nn as nn
lst=torch.Tensor([[1,2,3,4],
[2,3,4,5],
[7,8,9,10]])
lst=lst.unsqueeze(1)
lst.shape
#torch.Size([3, 1, 4])
multi_atten=nn.MultiheadAttention(embed_dim=4,
num_heads=2)
multi_atten(lst,lst,lst)
'''
(tensor([[[ 1.9639, -3.7282, 2.1215, 0.6630]],
[[ 2.2423, -4.2444, 2.2466, 1.0711]],
[[ 2.3823, -4.5058, 2.3015, 1.2964]]], grad_fn=<AddBackward0>),
tensor([[[9.0335e-02, 1.2198e-01, 7.8769e-01],
[2.6198e-02, 4.4854e-02, 9.2895e-01],
[1.6031e-05, 9.4658e-05, 9.9989e-01]]], grad_fn=<DivBackward0>))
'''



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









