







 本文详细记录了一次HDFS线上故障的分析与解决过程,问题源于扩容新节点导致的集群性能严重下滑。通过日志、监控和源码分析,发现新节点磁盘性能问题及线程过多,最终确定原因是新扩容节点使用的是HDD而非SSD,导致I/O瓶颈。解决方案包括立即下线问题节点,调整配置项避免线程过多,并建议避免不同介质混布。
本文详细记录了一次HDFS线上故障的分析与解决过程,问题源于扩容新节点导致的集群性能严重下滑。通过日志、监控和源码分析,发现新节点磁盘性能问题及线程过多,最终确定原因是新扩容节点使用的是HDD而非SSD,导致I/O瓶颈。解决方案包括立即下线问题节点,调整配置项避免线程过多,并建议避免不同介质混布。
通过本文,你将学到包括但不限于如下知识:
- 解决HDFS线上问题的一般流程
- 一个完整的HDFS线上故障问题解决case:扩容集群为何会导致集群性能严重下滑?以及探讨给出优化方案。
- Linux网卡信息相关命令、Linux硬盘监控和分析工具smartctl等
本文将以一个生产环境下的线上告警为线索,一步一步抽丝剥茧找到引发告警的原因,并solve it!绝对让你有所收获!
一、告警现象
HDFS告警群不断出现DataNode的日志文件中Warn级别的日志数过多的告警。同时有业务方开始反馈集群的HDFS变得很慢,Flink出现checkpoint超时,作业也提交不上去了。告警如下图所示:
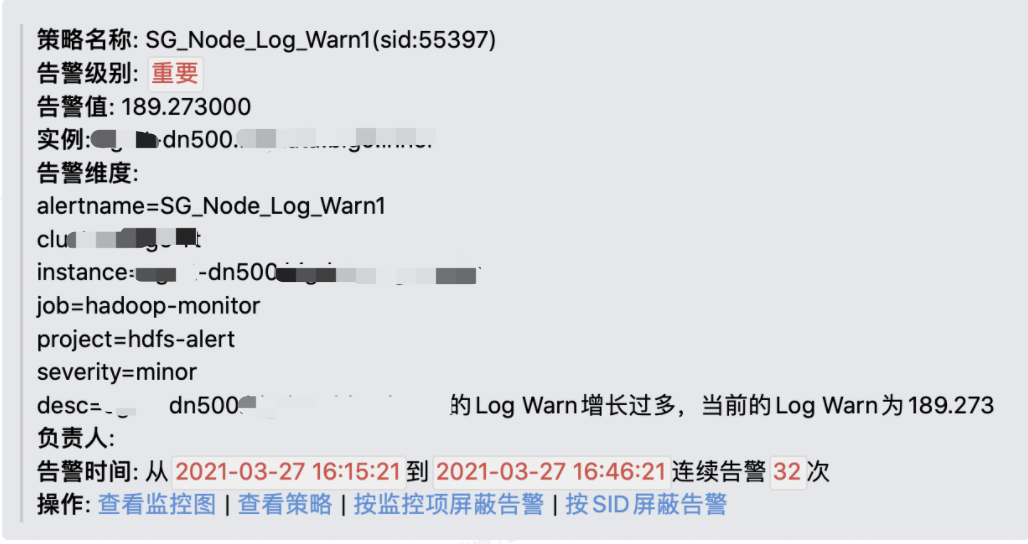
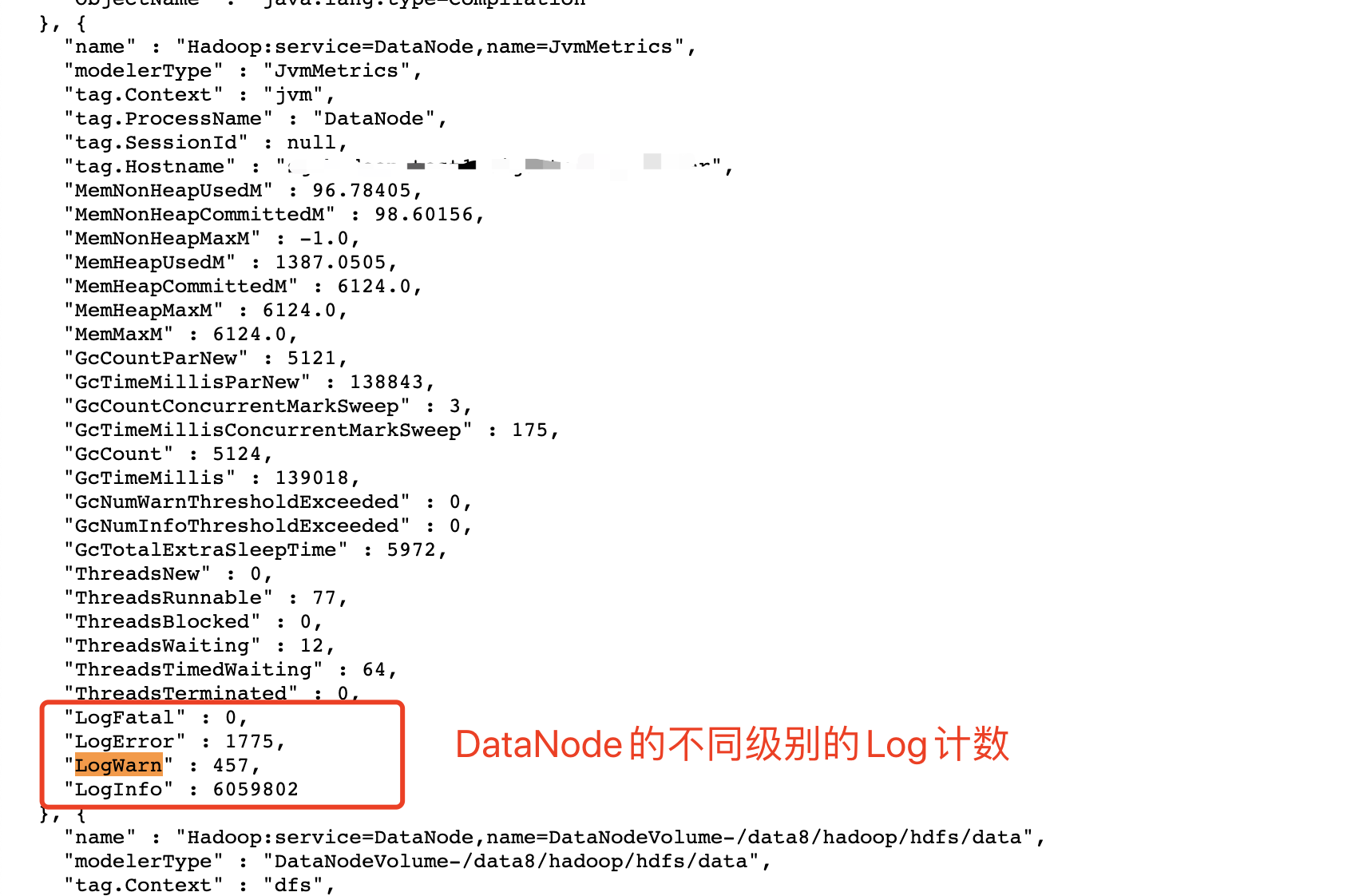
注:关于warn级别日志异常增多的告警,可以通过监控DataNode节点的jmx的LogWarn这个指标,设置一个增长速率阈值,如果增长率超过阈值则告警。如下图所示:

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











