




 本文通过对比本地磁盘与Ceph挂载盘在读写速度上的表现,详细分析了multiprocessing库中Pool的两种模式(dummy与non-dummy)在不同存储介质上的效率差异。实验结果显示,在IO密集型任务中,本地磁盘配合dummy模式的性能最佳,而在CPU密集型任务中,non-dummy模式展现出更好的多线程计算能力。
本文通过对比本地磁盘与Ceph挂载盘在读写速度上的表现,详细分析了multiprocessing库中Pool的两种模式(dummy与non-dummy)在不同存储介质上的效率差异。实验结果显示,在IO密集型任务中,本地磁盘配合dummy模式的性能最佳,而在CPU密集型任务中,non-dummy模式展现出更好的多线程计算能力。
SR在ceph下训练时,发现对图片的读取操作成为了瓶颈,因此希望使用多线程或多进程进行加速
这里给出本地磁盘和ceph盘下的multiprocessing的两种pool模式的速度比较,供大家参考。
相关资料
《一行 Python 实现并行化 – 日常多线程操作的新思路》
《Python 多线程》
《multiprocessing — Process-based parallelism》
测试数据
测试数据在linux下得到。
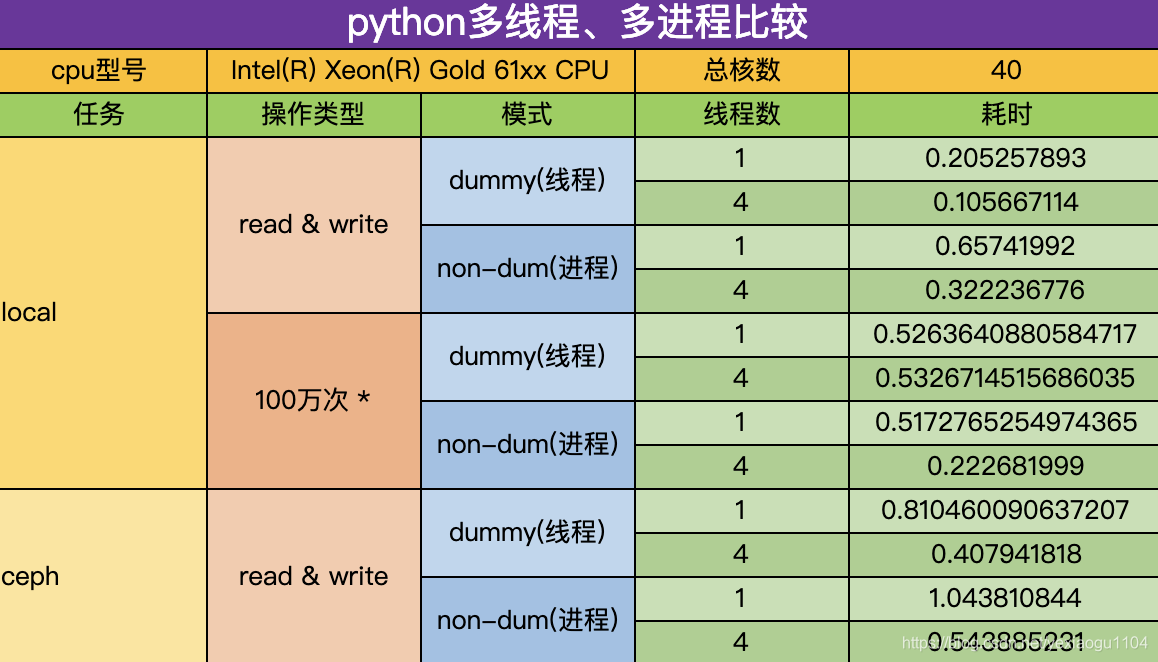
测试结论
1. multiprocessing中的Pool两种写法的区别
multiprocessing库中的Pool有两种写法,如下表所示。引用中的《一行 Python 实现并行化 – 日常多线程操作的新思路》一文中描述是,“dummy 是 multiprocessing 模块的完整克隆,唯一的不同在于 multiprocessing 作用于进程,而 dummy 模块作用于线程”。
其具体区别是:
- dummy模式使用1个进程,多个线程
- non-dummy模式使用多个进程,对应于多个线程
| mode | command |
|---|---|
| dummy | from multiprocessing.dummy import Pool as ThreadPool |
| non-dummy | from multiprocessing import Pool as ProcessPool |
2. 不同硬盘、不同操作类型的测试结论
i 本地磁盘和ceph挂载盘的读写速度比较( IO 密集型任务)
- dummy模式,threads=1 or 4, 本地磁盘速度是ceph的4倍
- non-dum模式,threads=1 or 4,本地磁盘速度是ceph的2倍
- 本地磁盘下,dummy模式的速度是non-dummy模式的3倍
- ceph挂载盘下,dummy模式的速度只有non-dummy模式的1.25倍
- 结论:读写操作的选择优先级是:
本地磁盘/dummy模式>本地磁盘/non-dummy模式>ceph/dummy模式>ceph/non-dum模式
ii dummy和non-dum模式的乘法计算比较(CPU 密集型任务)
- dummy模式采用单进程,多线程,线程数的提高,对乘法计算的速度提升帮助不大
- non-dum模式采用多进程-多线程,线程数从1->4,对乘法计算速度加倍
3. 其他结论
- Image.open 读取速度比cv2.imread快一倍
- 在mac下测试的数据IO密集任务时,应先保证有足够的内存空间,不然结论可能不正确。
- time.clock()函数不准,最好用time.time()
测试代码
import cv2
import time
import logging
#from multiprocessing.dummy import Pool as ThreadPool
from multiprocessing import Pool as ThreadPool
from PIL import Image
logging.basicConfig(level=logging.DEBUG)
def read_and_write(src_index):
src_path = 'xxxx/{:0>4}.bmp'.format(src_index+1)
dst_path = '000{}.bmp'.format(src_index+1)
a = Image.open(src_path)
#a = cv2.imread(src_path)
#for i in range(1000000):
# s = i*i
#a = s
#cv2.imwrite(dst_path, a)
return a, a
def test_run():
src_index = [i for i in range(800)]
pool = ThreadPool(4)
results = pool.map(read_and_write, src_index)
pool.close()
pool.join()
return results
def main():
start = time.time()
result = test_run()
logging.info('Total time is {}'.format(time.time()-start))
logging.debug('quit main process')
if __name__ == '__main__':
main()

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









