







整个系列的内容包括:
(下面所有截图均用SecureCRT远程登录连接显示)
所需工具和环境:VMWare、centos、SecureCRT(或者xshell等类似远程登录工具)
在 Hadoop 中,伪分布式集群模式是一种在单台机器上模拟分布式环境的模式,适合学习和开发。它介于完全分布式和单节点模式之间,通过在一台计算机上配置多个 Hadoop 节点(如 NameNode、DataNode、ResourceManager、NodeManager 等),实现 Hadoop 集群的基础操作。在伪分布式模式中,Hadoop 的各个服务运行在同一台机器的不同 JVM(Java 虚拟机)中,互相之间通过网络通信,因此能很好地模拟 Hadoop 集群的行为。这种模式适合开发和调试应用,无需额外的硬件资源即可体验分布式系统的操作流程。伪分布式模式适合新手初步了解 Hadoop 的架构和运行机制,熟悉之后可以向完全分布式模式过渡。
一、伪分布式运行模式
cd /export/server/hadoop-3.3.0/etc/hadoop
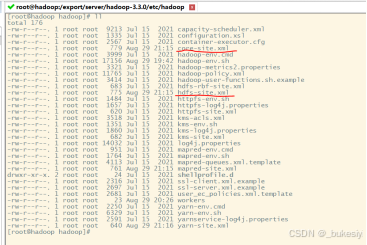
1、配置core-site.xml(将下列代码添加至core-site.xml)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:8020</value>
</property>
</configuration>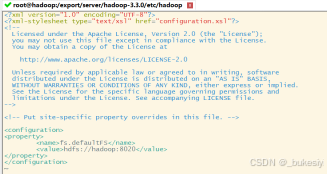
2、配置hdfs-site.xml(将下列代码添加至hdfs-site.xml)
<configuration>
<property>
<name>dfs.replication </name>
<value>1</value>
</property>
</configuration>二、HDFS配置及运行MapReduce程序
1、配置:hadoop-env.sh(实战系列(一)中已经配置这里不再赘述)
2、配置:core-site.xml(将下列代码添加至core-site.xml)
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>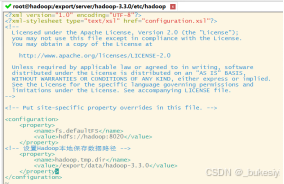
3、启动集群
格式化NameNode(第一次启动时格式化,以后就不要总格式化)
bin/hdfs
bin/hdfs namenode -format
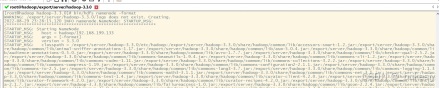
如果你在格式化过程中出现让你重新格式化,可能是你之前格式化过,数据没有删除掉第一次格式化不会出现问题
启动NameNode
sbin/hadoop-daemon.sh start namenode
(sbin/hdfs --daemon start namenode)
以上两个命令二选一
启动DataNode
sbin/hdfs --daemon start datanode
查看是否启动成功
jps
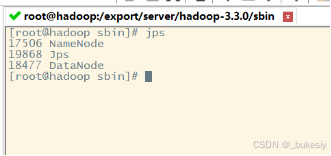
注意:jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps、
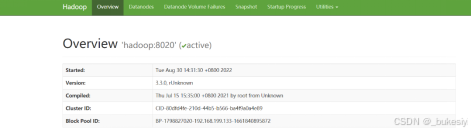
4、web端查看HDFS文件系统
访问:http:// 192.168.199.133:9870/(这里的ip地址请大家用自己的ip,我这里只是演示效果,端口号,大家按照我之前的设置应该就是9870,请注意端口号有没有被其他程序占用的情况)
三、配置YARN并运行MapReduce程序
1、配置yarn-env.sh(将下面代码添加至yarn-env.sh)
export JAVA_HOME=/export/server/jdk1.8.0_241
配置yarn-site.xml
vim yarn-site.xml(将下面代码添加至yarn-site.xml)
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>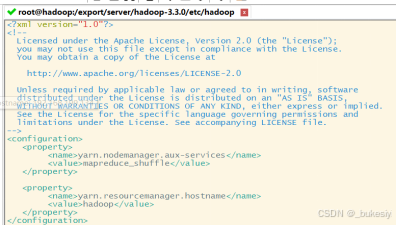
2、配置mapred-env.sh(将下面代码添加至yarn-env.sh)
export JAVA_HOME=/export/server/jdk1.8.0_241
3、配置 mapred-site.xml
vim mapred-site.xml(将下面代码添加至mapred-site.xml)
<!-- 设置MR程序默认运行模式:yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>4、启动集群
启动前必须保证NameNode和DataNode已经启动

启动ResourceManager
yarn --daemon start resourcemanager

启动NodeManager
yarn --daemon start nodemanager

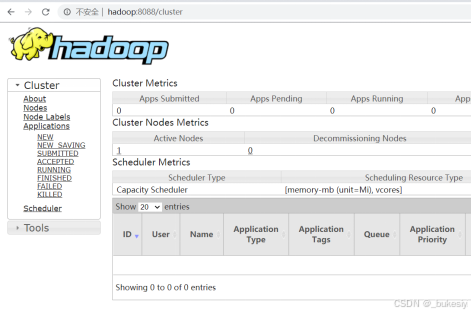
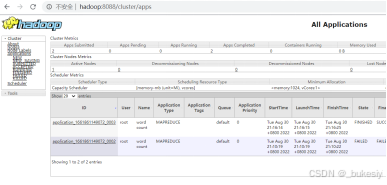
5、web端查看
访问:http:// 192.168.199.133:8088/(这里的ip地址请大家用自己的ip,我这里只是演示效果,端口号,大家按照我之前的设置应该就是8088,请注意端口号有没有被其他程序占用的情况)
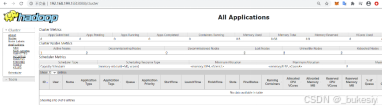
也可以通过域名而不是ip来访问电脑
用且只能用记事本来编辑C:\Windows\System32\drivers\etc里面的hosts文件
添加如下代码
192.168.199.133 hadoop
即可用域名来访问
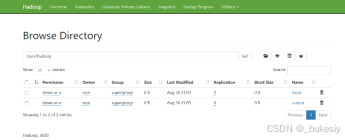
在分布式系统上创建input文件夹
hdfs dfs -mkdir -p /user/hadoop/input
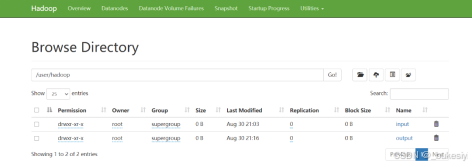
删除文件系统上的output文件
hdfs dfs -rm -r /user/hadoop/output
![]()
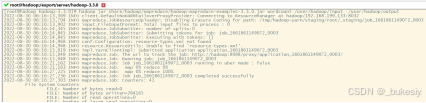
执行MapReduce程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /user/hadoop/input /user/hadoop/output



















 3799
3799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











