



RDD实现单词计数
Scala(Spark Shell)方法
如果你在 spark-shell(Scala 环境)中运行:
1. 启动 Spark Shell
spark-shell(确保 Spark 已安装,PATH 配置正确)
2. 执行单词统计
// 1. 读取文件(确保路径正确!)
val lines = sc.textFile("file:///home/xdt/桌面/data.txt")
// 2. 拆分单词 + 统计
val wordCounts1 = lines.flatMap(line => line.split(" ")) // 按空格分割
val wordCounts2 = wordCounts1.map(word => (word, 1)) // 每个单词计数 1
val wordCounts3 = wordCounts2.reduceByKey(_ + _) // 相同单词累加
// 3. 显示结果(前20个)
wordCounts3.take(20).foreach(println)
// 4. 保存结果
wordCounts3.saveAsTextFile("file:///home/xdt/桌面/wordcount_output")3. 检查输出
-
控制台:会打印前 20 个单词的统计结果。
-
文件:结果保存在
~/桌面/wordcount_output/part-00000。
注意路径写法,要写自己电脑上的路径。
上面是文件来源于本地的情况,如果文件位于HDFS里,要先把HDFS启动起来。
印象里好像是start-all.sh


scala是一种多范式编程语言,结合了面向对象编程(OOP)和函数式编程(FP)的特性。
设计初衷是为了解决Java冗长性的问题,同时兼容JVM(java虚拟机)。
Scala提供了比Java更纯粹的FP体验。
RDD是弹性分布式数据集。是Apache Spark的核心数据结构,或者说一个数据集合。
RDD的操作类型有两种:转换操作(生成新RDD,不执行)、行动操作(触发实际计算并返回结果)。
RDD是不可变的,一旦被创建,不可修改,只能通过转换操作生成新的RDD。
还有一些词:血缘、分片多节点并行计算。慢慢研究~~
分布式:
分布式计算笔记(一) - 快乐星猫i - 博客园(分布式笔记)
Spark - 快乐星猫i - 博客园(Spark基础RDD)
RDD - 快乐星猫i - 博客园(RDD编程基础)
Spark SQL - 快乐星猫i - 博客园(Spark SQL)
Spark MLib - 快乐星猫i - 博客园(Spark的机器学习)
IntelliJ IDEA 中运行
1. 安装必要工具
-
IntelliJ IDEA(建议使用 Ultimate 版,Community 版也支持 Scala)
-
Scala 插件(在 IDEA 中安装)
-
JDK 8/11(Spark 3.x 支持 JDK 8/11)
-
Scala SDK(建议 2.12.x,与 Spark 3.x 兼容)
2. 创建 Scala 项目
可以通过plugin下载scala,来创建scala项目
步骤 1:打开 IDEA,新建项目
-
File → New → Project
-
选择 Scala → IDEA(或 SBT 项目)
-
设置:
-
Project SDK:选择 JDK(如 JDK 11)
-
Scala SDK:点击 "Create" 按钮,选择 Scala 版本(如 2.12.15)
-
不要忘记导Scala SDK!!!
步骤 2:配置项目结构
-
项目名称:
SparkWordCount -
项目路径:选择你的工作目录
3. 添加 Spark 依赖
方法 1:使用 SBT(推荐)
1.在项目根目录下找到 build.sbt 文件,添加以下内容:
name := "SparkWordCount"
version := "1.0"
scalaVersion := "2.12.15"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.3.0"2.等待 IDEA 自动加载依赖(或手动点击 Reload All SBT Projects)。
确保 Scala 版本匹配(Spark 3.3.0 需要 Scala 2.12.x)
方法 2:手动添加 JAR
1.下载 Spark 的预编译包:
wget https://archive.apache.org/dist/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz
tar -xzf spark-3.3.0-bin-hadoop3.tgz2.在 IDEA 中:
-
File → Project Structure → Libraries → + → Java
-
添加 Spark 的 JAR 文件:
-
spark-3.3.0-bin-hadoop3/jars/*.jar
-
这里主包直接添加的炸包 下面是主包的spark的路径
/opt/spark-3.5.5-bin-hadoop3/jars/spark-core_2.12-3.5.5.jar
否则无法导入
org.apache.spark
4. 创建 WordCount 程序
步骤 1:新建 Scala 类
-
右键
src/main/scala→ New → Scala Class -
输入名称
WordCount,类型选择Object
步骤 2:编写代码
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// 1. 创建 Spark 配置
val conf = new SparkConf()
.setAppName("WordCount")
.setMaster("local[*]") // 本地模式
// 2. 初始化 SparkContext
val sc = new SparkContext(conf)
try {
// 3. 读取文件(替换为你的路径)
val lines = sc.textFile("file:///home/xdt/桌面/data.txt")
// 4. 单词统计
val wordCounts = lines
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
// 5. 打印结果
wordCounts.take(20).foreach(println)
// 6. 保存结果
wordCounts.saveAsTextFile("file:///home/xdt/桌面/wordcount_output")
} finally {
// 7. 关闭 SparkContext
sc.stop()
}
}
}5. 运行程序
方法 1:直接运行
-
右键
WordCount.scala→ Run 'WordCount' -
查看控制台输出和结果文件。
方法 2:打包后提交
-
File → Project Structure → Artifacts → + → JAR → From modules
-
选择主类为
WordCount,构建 JAR。 -
通过
spark-submit运行:
spark-submit --class WordCount SparkWordCount.jar计算图书每天平均销量
idea中运行Scala
object BookSalesAverage {
def main(args: Array[String]): Unit = {
// 输入数据
val sales = List(("spark", 2), ("hadoop", 6), ("hadoop", 4), ("spark", 6))
// 计算每种图书的平均销量
val averages = sales
.groupBy(_._1) // 按图书名称分组
.map { case (book, salesList) =>
val values = salesList.map(_._2) // 提取销量值
val avg = values.sum.toDouble / values.size // 计算平均值
(book, avg)
}
// 打印结果
averages.foreach { case (book, avg) =>
println(s"$book 的平均销量: $avg")
}
}
}代码说明:
-
输入数据:使用元组列表存储图书名称和销量数据
-
分组操作:
groupBy(_._1)按图书名称(元组的第一个元素)分组 -
计算平均值:
-
对每个分组提取销量值(
map(_._2)) -
计算总和并除以数量得到平均值
-
-
输出结果:打印每种图书的平均销量
建表并查询(Spark SQL入门)
代码
import org.apache.spark.sql.{SparkSession, DataFrame}
import org.apache.spark.sql.types._
object SparkSQL {
def main(args: Array[String]): Unit = {
// Create SparkSession
val spark = SparkSession.builder()
.appName("DefineSchemaExample")
.master("local[*]") // Remove this line for cluster execution
.getOrCreate()
try {
// Define schema programmatically
val schema = StructType(Array(
StructField("Id", IntegerType, nullable = false),
StructField("First", StringType, nullable = false),
StructField("Last", StringType, nullable = false),
StructField("Url", StringType, nullable = false),
StructField("Published", StringType, nullable = false),
StructField("Hits", IntegerType, nullable = false),
StructField("Campaigns", ArrayType(StringType), nullable = false)
))
// Read JSON file with the defined schema
val blogsDF = spark.read.schema(schema).json("file:///home/xdt/桌面/blogs.json")
// Show the DataFrame
blogsDF.show()
// Print schema
blogsDF.printSchema()
// Alternative way to print schema
println(blogsDF.schema)
} finally {
spark.stop()
}
}
}blogs.json
{"Id": 1,"First": "John","Last": "Doe","Url": "https://example.com/john","Published": "2023-01-15","Hits": 1024,"Campaigns": ["winter_sale", "new_user"]}
{"Id": 2,"First": "Jane","Last": "Smith","Url": "https://example.com/jane","Published": "2023-02-20","Hits": 2048,"Campaigns": ["spring_promo", "referral"]}
{"Id": 3,"First": "Bob","Last": "Johnson","Url": "https://example.com/bob","Published": "2023-03-10","Hits": 512,"Campaigns": ["summer_sale", "loyalty"]}
{"Id": 4,"First": "Alice","Last": "Williams","Url": "https://example.com/alice","Published": "2023-04-05","Hits": 4096,"Campaigns": ["back_to_school", "clearance"]}一行数据放一行,不要换行。
运行结果

Top统计
项目结构
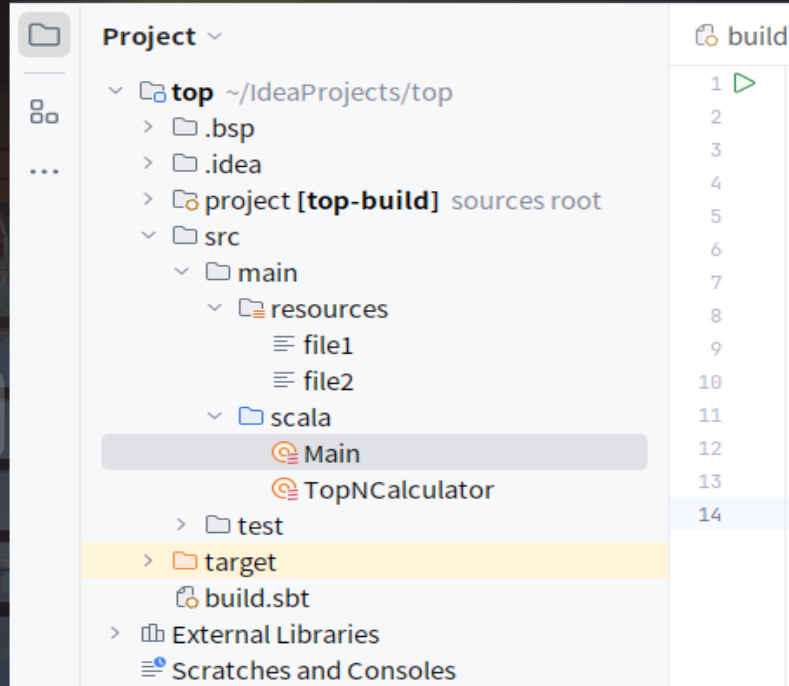
TopNCalculator.scala
import scala.io.Source
import scala.util.{Failure, Success, Try}
object TopNCalculator {
case class Order(orderId: Int, userId: Int, payment: Int, productId: Int)
def calculateTopNPayments(filePaths: List[String], n: Int): List[Int] = {
// 读取所有文件并合并数据
val orders = filePaths.flatMap(readOrdersFromFile)
// 按payment降序排序并取前N个
orders
.sortBy(-_.payment) // 降序排序
.take(n) // 取前N个
.map(_.payment) // 提取payment值
}
private def readOrdersFromFile(filePath: String): List[Order] = {
Try {
Source.fromResource(filePath)
.getLines()
.filter(_.trim.nonEmpty) // 过滤空行
.flatMap { line =>
line.split(",").map(_.trim) match {
case Array(orderId, userId, payment, productId) =>
Some(Order(
orderId.toInt,
userId.toInt,
payment.toInt,
productId.toInt
))
case _ => None // 忽略格式不正确的行
}
}
.toList
} match {
case Success(orders) => orders
case Failure(ex) =>
println(s"Error reading file $filePath: ${ex.getMessage}")
List.empty[Order]
}
}
}Main.scala
object Main extends App {
// 文件路径(放在resources目录下)
val filePaths = List("file1", "file2")
// 计算Top 5 payment值
val topN = 5
val topPayments = TopNCalculator.calculateTopNPayments(filePaths, topN)
// 打印结果
println(s"Top $topN payment values:")
topPayments.zipWithIndex.foreach { case (payment, index) =>
println(s"${index + 1}. $payment")
}
}file1.txt
1,1768,50,155
2,1218,600,211
3,2239,788,242
4,3101,28,599
5,4899,290,129
6,3110,54,1201
7,4436,259,877
8,2369,7890,27file2.txt
100,4287,226,233
101,6562,489,124
102,1124,33,17
103,3267,159,179
104,4569,57,125
105,1438,37,116运行结果
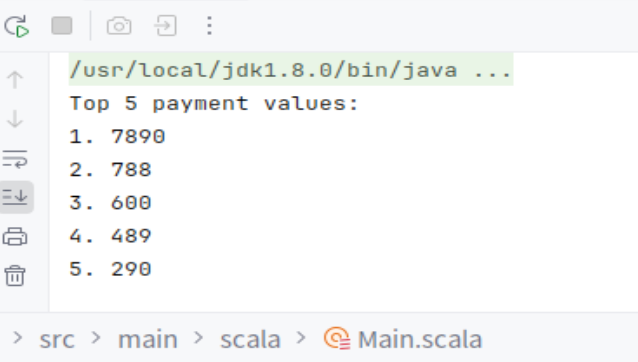
统计M&M巧克力豆(Scala)
package main.scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
/**
* 用法: MnMcount <mnm_file_dataset>
*/
object MnMcount {
def main(args: Array[String]) {
val spark = SparkSession
.builder
.appName("MnMCount")
.master("local[*]")
.getOrCreate()
if (args.length < 1) {
print("Usage: MnMcount <mnm_file_dataset>")
sys.exit(1)
}
// 获取M&M豆数据集的文件名
val mnmFile = args(0)
// 将文件读入Spark DataFrame
val mnmDF = spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load(mnmFile)
// 用groupBy()按州和颜色分组,然后聚合求出所有颜色的总计数
// 使用orderBy()降序排列
val countMnMDF = mnmDF
.select("State", "Color", "Count")
.groupBy("State", "Color")
.agg(count("Count").alias("Total"))
.orderBy(desc("Total"))
// 展示所有州和颜色对应的聚合结果
countMnMDF.show(60)
println(s"Total Rows = ${countMnMDF.count()}")
println()
// 通过过滤得到加利福尼亚州的聚合数据
val caCountMnMDF = mnmDF
.select("State", "Color", "Count")
.where(col("State") === "CA")
.groupBy("State", "Color")
.agg(count("Count").alias("Total"))
.orderBy(desc("Total"))
// 展示加利福尼亚州的聚合结果
caCountMnMDF.show(10)
// 停止SparkSession
spark.stop()
}
}
项目文件夹下运行这个👇
spark-submit --class main.scala.MnMcount out/artifacts/MnMcount_jar/MnMcount.jar file:///home/xdt/桌面/mnm_daset.csv
运行结果
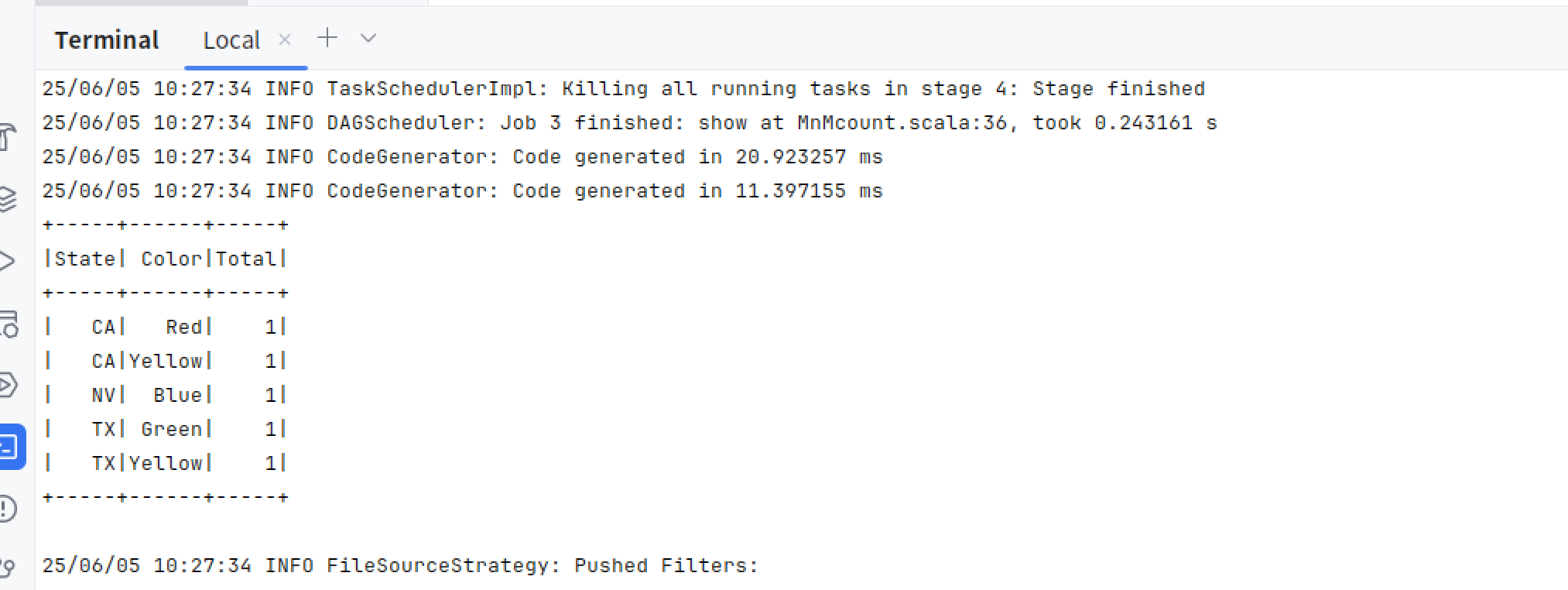
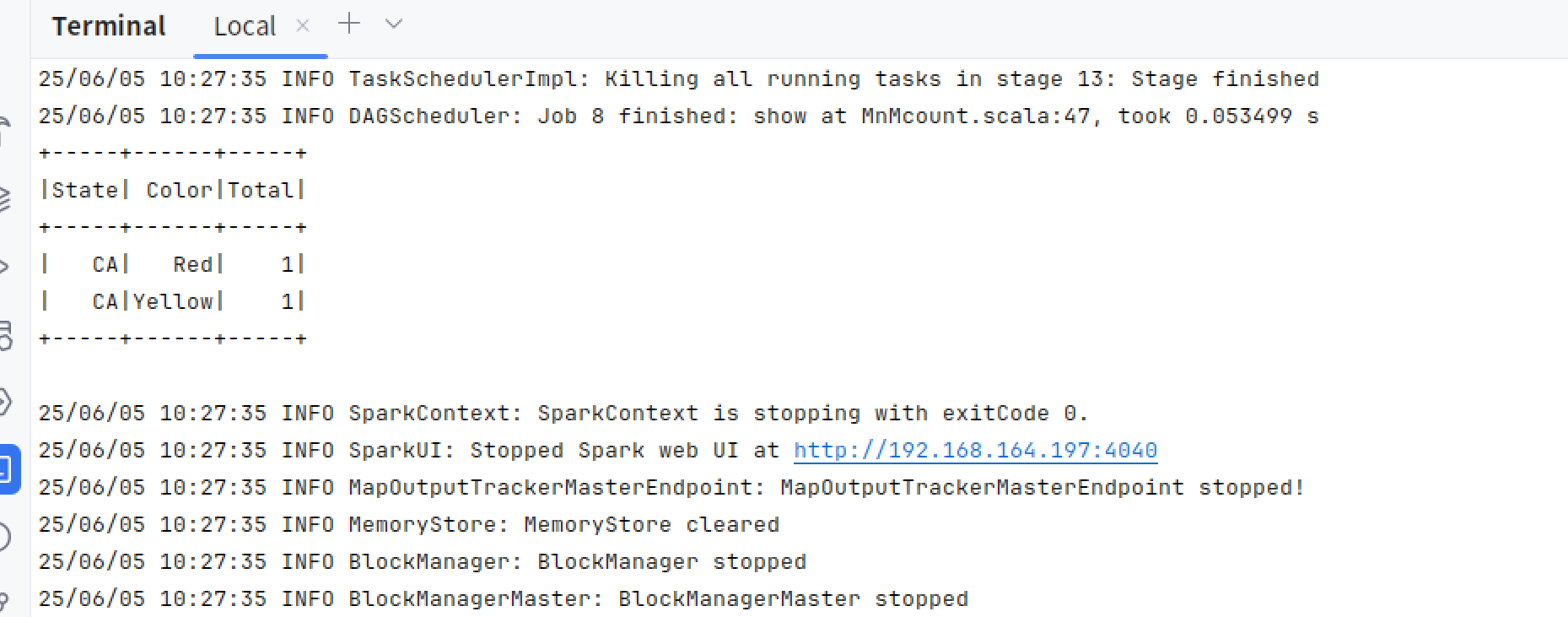
Spark SQL使用
读数据->创建临时视图->SQL查询
import org.apache.spark.sql.SparkSession
object SparkSQLDataLoadingExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("SparkSQLExampleApp")
.master("local[*]") // 本地模式,使用所有可用核心
.getOrCreate()
// 数据集的路径
val csvFile = "file:///home/xdt/桌面/LearningSparkV2-master/databricks-datasets/learning-spark-v2/flights/departuredelays.csv"
// 读取数据并创建临时视图
// 推断表结构 (注意, 如果文件较大, 最好手动指定表结构)
val df = spark.read.format("csv")
.option("inferSchema", "true")
.option("header", "true")
.load(csvFile)
// 创建临时视图
df.createOrReplaceTempView("us_delay_flights_tbl")
//手动指定表结构
val schema = "data STRING, delay INT, distance INT, origin STRING, destination STRING"
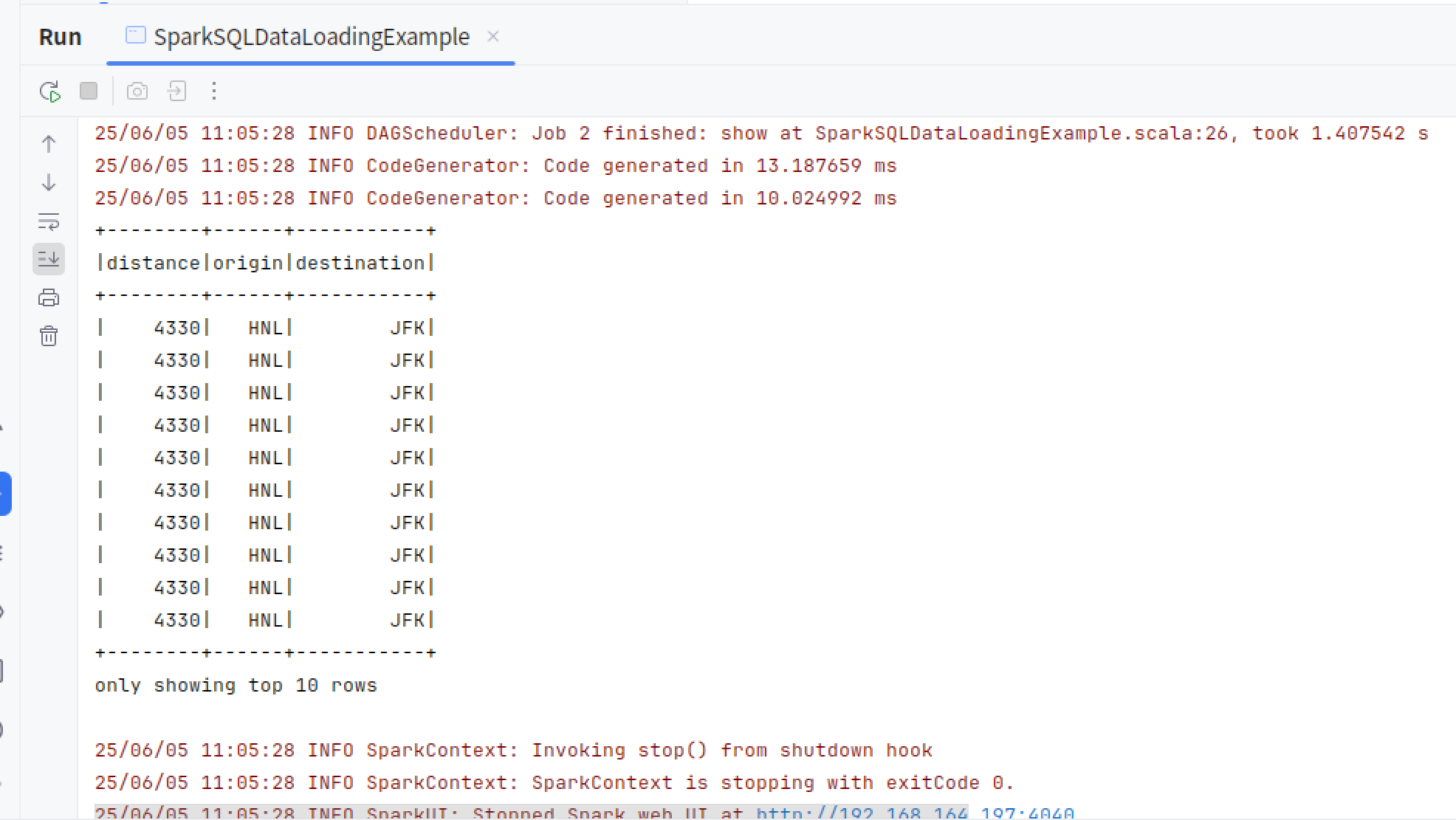
spark.sql("""SELECT distance, origin, destination FROM us_delay_flights_tbl WHERE distance > 1000 ORDER BY distance DESC""").show(10)
}
}
运行结果
MLlib机器学习库
查找出所有包含"spark"的句子,即将包含"spark"的句子 的标签设为1,没有"spark"的句子的标签设为0。
Scala代码
import org.apache.spark.ml.feature.{Tokenizer, HashingTF}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.Pipeline
import org.apache.spark.sql.SparkSession
object LogisticRegressionExample {
def main(args: Array[String]): Unit = {
// 1. 创建 SparkSession
val spark = SparkSession.builder()
.appName("SparkMLExample")
.master("local[*]") // 本地模式运行
.getOrCreate()
import spark.implicits._
// 2. 准备训练数据
val training = Seq(
(0, "a b c d e spark", 1.0),
(1, "b d", 0.0),
(2, "spark f g h", 1.0),
(3, "hadoop mapreduce", 0.0)
).toDF("id", "text", "label")
// 3. 特征工程
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setInputCol("words")
.setOutputCol("features")
.setNumFeatures(1000) // 设置特征哈希的维度
// 4. 定义逻辑回归模型
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.01)
// 5. 构建 Pipeline
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
// 6. 训练模型
val model = pipeline.fit(training)
// 7. 准备测试数据
val test = Seq(
(4, "spark i j k"),
(5, "l m n"),
(6, "spark hadoop spark"),
(7, "apache hadoop")
).toDF("id", "text")
// 8. 预测
val predictions = model.transform(test)
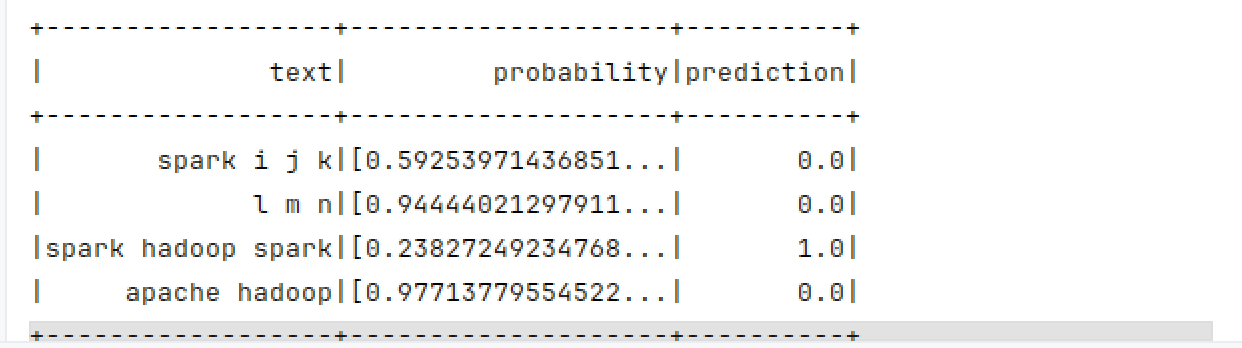
predictions.select("text", "probability", "prediction").show()
// 关闭 SparkSession
spark.stop()
}
}运行结果
python代码
from pyspark.ml.feature import Tokenizer, HashingTF
from pyspark.ml.classification import LogisticRegression
from pyspark.ml import Pipeline
# 1. 数据准备(已经包含标签)
training = spark.createDataFrame([
(0, "a b c d e spark", 1.0),
(1, "b d", 0.0),
(2, "spark f g h", 1.0),
(3, "hadoop mapreduce", 0.0)
], ["id", "text", "label"])
# 2. 特征工程
tokenizer = Tokenizer(inputCol="text", outputCol="words")
hashingTF = HashingTF(inputCol="words", outputCol="features")
# 3. 定义模型(逻辑回归)
lr = LogisticRegression(maxIter=10, regParam=0.01)
# 4. 构建Pipeline
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
# 5. 训练模型(这里才会用到.fit())
model = pipeline.fit(training) # <-- 这里调用.fit()
# 6. 预测
test = spark.createDataFrame([
(4, "spark i j k"),
(5, "l m n"),
(6, "spark hadoop spark"),
(7, "apache hadoop")
], ["id", "text"])
prediction = model.transform(test)
prediction.select("text", "probability", "prediction").show()
















 2638
2638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









