






 Apache Flume是一个用于高效、可靠、可用的数据收集系统。本文详细介绍了Flume的core概念,如Agent、Source、Sink、Channel、Event、Interceptor等,并分析了配置文件的编写方法。特别讨论了SpoolingDirSource和TailDirSource的特点和使用场景,强调了数据可靠性和事务管理在Flume中的重要性。此外,还提供了具体的配置示例,展示了如何配置Flume以将数据传输到HDFS和使用logger sink。
Apache Flume是一个用于高效、可靠、可用的数据收集系统。本文详细介绍了Flume的core概念,如Agent、Source、Sink、Channel、Event、Interceptor等,并分析了配置文件的编写方法。特别讨论了SpoolingDirSource和TailDirSource的特点和使用场景,强调了数据可靠性和事务管理在Flume中的重要性。此外,还提供了具体的配置示例,展示了如何配置Flume以将数据传输到HDFS和使用logger sink。
一、Flume的核心概念
1.Agent:Agent是一个JVM进程,它是以事件的形式将数据从源头送到目的地。Agent主要由三个部分组成,source,channel,sink。
2.source:source是负责接收数据到Flume Agent的组件。source组件可以处理各种类型,各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
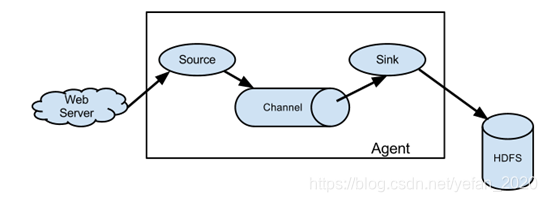
3.sink:sink不断轮询channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统,或者被发送到另一个Flume Agent。
4.channel:channel是位于source和sink之间的缓冲区。因此,channel允许source和sink运行在不同的速率上,channel是线程安全的,可以同时处理几个source的写入操作和几个sink的读取操作。Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
5.Event:传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。Event由Header和Body两部分组成,Header用来存放该Event的一些属性,为K_V结构,Body用来存放该条数据,形式为字节数组。
6.Interceptors:在Flume中允许使用拦截器对传输中的event进行拦截和处理!拦截器必须实现org.apache.flume.interceptor.Interceptor接口。拦截器可以根据开发者的设定修改甚至删除event!Flume同时支持拦截器链,即由多个拦截器组合而成!通过指定拦截器链中拦截器的顺序,event将按照顺序依次被拦截器进行处理!
7.Channel Selectors:当一个source对接多个channel时,由Channel Selectors选取channel将event存入!
8.sink processor: 当多个sink从一个channel取数据时,为了保证数据的顺序,由sink processor从多个sink中,挑选一个sink,由这个sink干活!
二、配置文件解析

1.安装Flume:①保证有JAVA_HOME,②解压即可
2.使用Flume:启动Agent:flume-ng agent -n agent的名称 -f agent配置文件 -c 其他配置文件所在的目录 -Dproperty=value
3.如何编写配置文件:
agent的配置文件的本质是一个Properties文件!格式为 属性名=属性值
在配置文件中需要编写:
①定义当前配置文件中agent 的名称,再定义source,sink,channel的别名
②指定source和channel和sink等组件的类型
③指定source和channel和sink等组件的配置,配置参数名和值都需要参考Flume的官方用户手册
④指定source和channel的对应关系,以及sink和channel的对应关系,连接组件!
4.Execsource的缺点
execsource和异步source一样,无法在source向channel中放入event故障时,及时通知客户端,暂停生成数据!
解决方案: 需要在发生故障时,及时通知客户端!
如果客户端无法暂停,必须有一个数据的缓存机制!
如果希望数据有强的可靠性保证,可以考虑使用SpoolingDirSource或TailDirSource或自己写Source自己控制!
三、常用的source
1.SpoolingDirSource:
SpoolingDirSource指定本地磁盘的一个目录为“Spooling(自动收集)”的目录!这个source可以读取目录中新增的文件,将文件的内容封装为event!
SpoolingDirSource在读取一个文件到channel之后,它会采取策略,要么删除文件(是否可以删除取决于配置)要么对文件进程一个完成状态的重命名,这样可以保证source持续监听新的文件!
SpoolingDirSource和execsource不同,SpoolingDirSource是可靠的!即使Flume被杀死或者重启,依然不丢数据,但是为了保证这个特性,付出的代价是,一旦Flume发现以下情况,就会报错,停止!
①一个文件已经被放入目录,在采集文件时,不能被修改
②文件的名在放入目录后又被重新使用(出现了重名文件)
要求:必须已经封闭的文件才能放入到SpoolingDirSource,在同一个SpoolingDirSource中都不能出现重名的文件!
必须配置:
type – The component type name, needs to be spooldir.
spoolDir – The directory from which to read files from.
案例三:
#a1是agent的名称,a1中定义了一个叫r1的source,如果有多个,使用空格间隔
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#组名名.属性名=属性值
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/home/atguigu/flume
#定义chanel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
#定义sink
a1.sinks.k1.type = hdfs
#一旦路径中含有基于时间的转义序列,要求event的header中必须有timestamp=时间戳,如果没有需要将useLocalTimeStamp = true
a1.sinks.k1.hdfs.path = hdfs://hadoop101:9000/flume/%Y%m%d/%H/%M
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = logs-
#以下三个和目录的滚动相关,目录一旦设置了时间转义序列,基于时间戳滚动
#是否将时间戳向下舍
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = minute
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize = 100
#以下三个和文件的滚动相关,以下三个参数是或的关系!以下三个参数如果值为0都代表禁用!
#60秒滚动生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 30
#设置每个文件到128M时滚动
a1.sinks.k1.hdfs.rollSize = 134217700
#每写多少个event滚动一次
a1.sinks.k1.hdfs.rollCount = 0
#以不压缩的文本形式保存数据
a1.sinks.k1.hdfs.fileType=DataStream
#连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2.TaiDirsource:
常见问题: TailDirSource采集的文件,不能随意重命名!如果日志在正在写入时,名称为 xxxx.tmp,写入完成后,滚动,改名为xxx.log,此时一旦匹配规则可以匹配上述名称,就会发生数据的重复采集!
Taildir Source 可以读取多个文件最新追加写入的内容!
Taildir Source是可靠的,即使flume出现了故障或挂掉。
Taildir Source在工作时,会将读取文件的最后的位置记录在一个json文件中,一旦agent重启,会从之前已经记录的位置,继续执行tail操作!
Json文件中,位置是可以修改,修改后,Taildir Source会从修改的位置进行tail操作!如果JSON文件丢失了,此时会重新从每个文件的第一行,重新读取,这会造成数据的重复!
TailDirsource目前只能只能读取文本文件!
必须配置:
channels –
type – The component type name, needs to be TAILDIR.
filegroups – Space-separated list of file groups. Each file group indicates a set of files to be tailed.
filegroups. – Absolute path of the file group. Regular expression (and not file system patterns) can be used for filename only.
案例四: 使用TailDirSource和logger sink
#a1是agent的名称,a1中定义了一个叫r1的source,如果有多个,使用空格间隔
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#组名名.属性名=属性值
a1.sources.r1.type=TAILDIR
a1.sources.r1.filegroups=f1 f2
a1.sources.r1.filegroups.f1=/home/atguigu/hi
a1.sources.r1.filegroups.f2=/home/atguigu/test
#定义sink
a1.sinks.k1.type=logger
a1.sinks.k1.maxBytesToLog=100
#定义chanel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
#连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
四、事务
1.数量关系
batchSize:每个Source和Sink都可以配置一个batchSize参数,这个参数代表一次性到channel中put | take多少个event!
batchSize<= transactionCapacity
transactionCapacity: putList和takeList的初始值!
capacity: channel中存储event的容量大小!
2.概念
putList:source在向channel放入数据时的缓冲区!putList在初始化时,需要根据一个固定的size初始化,这个size在channel中设置!
在channel中,这个size由参数transactionCapacity决定!
put事务流程:source将封装好的event,先放入到putList中,放入完成后,一次性commit(),这批event就可以写入到channel!
写入完成后,清空putList,开始下一批数据的写入!
假如一批event中的某些event在放入putList时,发生了异常,此时要执行rollback(),rollback()直接清空putList。
akeList: sink在向channel拉取数据时的缓冲区!
take事务流程: sink不断从channel中拉取event,没拉取一个event,这个event会先放入takeList中!
当一个batchSize的event全部拉取到takeList中之后,此时由sink执行写出处理!
假如在写出过程中,发送了异常,此时执行回滚!将takeList中所有的event全部回滚到channel!
反之,如果写出没有异常,执行commit(),清空takeList!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









