







 《HiT: Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval》是快手和北大在ICCV 2021上的研究,提出了一种双塔结构的视频文本检索方法。该方法强调在第一层和最后一层进行表征对齐,并引入MoCo的动量更新机制,通过四塔模型实现高效的对比学习。实验验证了其在大规模视频文本检索任务中的有效性。
《HiT: Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval》是快手和北大在ICCV 2021上的研究,提出了一种双塔结构的视频文本检索方法。该方法强调在第一层和最后一层进行表征对齐,并引入MoCo的动量更新机制,通过四塔模型实现高效的对比学习。实验验证了其在大规模视频文本检索任务中的有效性。
《HiT: Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval》ICCV 2021
快手和北大的工作,视频文本检索任务,即让视频和文本对齐,已经用于快手的各个场景中。
视频-文本对齐方法
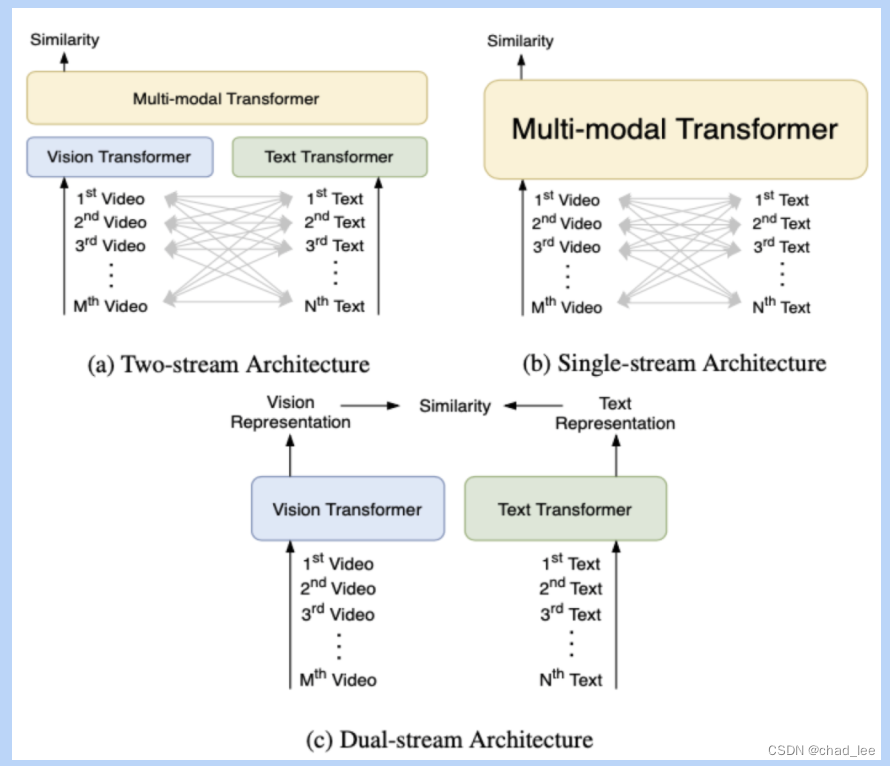
现有的视频-文本对齐的方法有三类:
- Two-stream,文本和视觉信息分别通过独立的 Vision Transformer 和 Text Transformer,然后在多模态 Transformer 中融合,代表方法例如 ViLBERT、LXMERT等。
- Single-stream,文本和视觉信息只通过一个多模态 Transformer 进行融合,代表方法例如 VisualBERT、Unicoder-VL等。
- Dual-stream,文本和视觉信息仅仅分别通过独立的 Vision Transformer 和 Text Transformer,代表方法例如 COOT、T2VLAD等。
显然第三类双塔类型的时间开销是最小的,本文也是采用双塔结构,以满足大规模视频文本检索需求。
本文主要有两个创新点:1、不仅在最后一层表征对齐,还在第一层表征对齐。2、引入MoCo的动量更新机制到对比学习匹配中。
第二点比较复杂,每个塔还有一个动量更新塔,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









