







HDFS 和 MR的常用javaApi
通用日志配置
log4j配置log4j2.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- 类型名为Console,名称为必须属性 -->
<Appender type="Console" name="STDOUT">
<!-- 布局为PatternLayout的方式,
输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here -->
<Layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" />
</Appender>
</Appenders>
<Loggers>
<!-- 可加性为false -->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT" />
</Logger>
<!-- root loggerConfig设置 -->
<Root level="info">
<AppenderRef ref="STDOUT" />
</Root>
</Loggers>
</Configuration>
HDFS
Maven依赖
<dependencies>
<!-- 单元测试-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<!-- 添加log4j的jar,用来打印log信息-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
<!-- Hadoop所需的依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
创建文件对象
FileSystem.get(new URI("hdfs://hadoop102:9820"),conf,"atguigu");
上传
//copyFromLocal 和 stream流
/*
copyFromLocalFile(boolean delSrc, boolean overwrite,
Path src, Path dst)
第一个参数 : 是否删除源文件
第二个参数 :是否覆盖目标文件(所需上传的文件在HDFS上已经存那么是否需要覆盖)
第三个参数 :源文件的路径
第四个参数 :目标文件的路径
*/
fs.copyFromLocalFile(true,true,
//new Path("D:\\io\\abc.txt"),new Path("/"));
new Path("D:\\javawork\\尚大数据\\04-BigData\\04-hadoop\\3.代码\\HDFSDemo\\input\\aba.txt"),new Path("/"));
}
//=======================================================================
//输入流-文件流:
FileInputStream fis = new FileInputStream("D:\\io\\aba.txt");
//输出流-HDFS:
FSDataOutputStream fos = fs.create(new Path("/aba.txt"));
//一边读一边写
/*
copyBytes(InputStream in, OutputStream out,
int buffSize, boolean close)
第一个参数:输入流
第二个参数 :输出流
第三个参数 :缓冲区大小
第四个参数 :是否关流
*/
IOUtils.copyBytes(fis,fos,1024,false);
//关流
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
下载
// copyToLocal 和 stream两种方式
/*
copyToLocalFile(boolean delSrc, Path src, Path dst,
boolean useRawLocalFileSystem)
第一个参数:是否删除源文件
第二个参数 :源文件的路径
第三个参数 :目标文件的路径
第四个参数 :是否使用RawLocalFileSystem
如果不使用则会生一个crc文件
如果使用则不生成crc文件
*/
fs.copyToLocalFile(false,new Path("/abc.txt"),
new Path("input/"),false);
//========================================================
//输入流-HDFS
FSDataInputStream fis = fs.open(new Path("/aba.txt"));
//输出流-本地(文件流)
FileOutputStream fos = new FileOutputStream("D:\\io\\aba.txt");
//一边读一边写
IOUtils.copyBytes(fis,fos,1024,true);
改名移动
/*
rename(Path src, Path dst)
第一个参数 :被改名前文件的路径
第二个参数 :改名后文件的路径
注意:路径相同则是改名,路径不同则是移动
只能在hdfs内部操作
*/
//改名
fs.rename(new Path("/input/aba.txt"),
new Path("/input/longge.txt"));
//移动
fs.rename(new Path("/input/longge.txt"),
new Path("/output/longge.txt"));
查看文件详情
// 1获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop1:9820"), configuration, "atguigu");
// 2 获取文件详情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/aba.txt"), true);
while (listFiles.hasNext()) {
LocatedFileStatus status = listFiles.next();
// 输出详情
// 文件名称
System.out.println(status.getPath().getName());
// 长度
System.out.println(status.getLen());
// 权限
System.out.println(status.getPermission());
// 分组
System.out.println(status.getGroup());
System.out.println("所属主:" + status.getOwner());//所属主
System.out.println("副本数:" + status.getReplication());//副本数
// 获取存储的块信息
BlockLocation[] blockLocations = status.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
// 获取块存储的主机节点
String[] hosts = blockLocation.getHosts();
System.out.printf(String.valueOf(blockLocation));
for (String host : hosts) {
System.out.println(host);
}
}
判断是文件还是目录
//获取目标路径下文件和目录的文件状态
FileStatus[] files = fs.listStatus(new Path("/"));
//遍历数组
for (FileStatus file : files) {
//判断
if (file.isDirectory()){
System.out.println(file.getPath().getName() + "是一个目录");
}else if(file.isFile()){
System.out.println(file.getPath().getName() + "是一个文件");
}
}
MapReduce
基本MR的程序组成
-
继承
Mapper类重写Mapper<LongWritable,Text,Map输出K类型,Map输出V类型>方法 -
继承
Reducer类 重写Reducer<Map输出K类型,Map输出V类型,Reduce输出K类型,Reduce输出V类型>方法 -
创建
Driver类,固定套路7步走- 当没有reducer方法时不用写Reducer
//1.创建Job对象 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); //2.设置Jar加载路径---在本地跑可以不设置 job.setJarByClass(WCDriver.class); //3.设置Mapper和Reducer类 job.setMapperClass(WCMapper.class); job.setReducerClass(WCReducer.class); //4.设置Mapper输出的k,v类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //5.设置最终输出的K,V类型(在这是Redcuer输出的K,V类型) job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //6.设置数据输入和输出路径 // 输出必须是未创建的路径,输入可写文件也可写路径 FileInputFormat.setInputPaths(job,new Path("D:\\io\\compress")); FileOutputFormat.setOutputPath(job,new Path("D:\\io\\output")); //7.执行job boolean b = job.waitForCompletion(true); System.exit(b? 0:1);-
实现向服务器提交
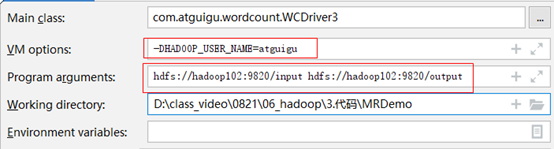
/** Edit Configuration VM options 和参数(模拟动态参数) 要设置 */ //允许外网访问内网集群 conf.set("dfs.client.use.datanode.hostname", "true"); //设置在集群运行的相关参数-设置HDFS,NAMENODE的地址 conf.set("fs.defaultFS", "hdfs://hadoop102:9820"); //指定MR运行在Yarn上 conf.set("mapreduce.framework.name","yarn"); //指定MR可以在远程集群运行 conf.set("mapreduce.app-submission.cross-platform","true"); //指定yarn resourcemanager的位置 conf.set("yarn.resourcemanager.hostname", "hadoop103"); Job job = Job.getInstance(conf); //打完包后替换为setJar方法使用 //job.setJarByClass(WbDriver1.class); job.setJar("D:\\javawork\\尚大数据\\04-BigData\\04-hadoop\\3.代码\\MRde\\target\\MRde-1.0-SNAPSHOT.jar"); /* FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); */
序列化和分区
- 自定义类 实现
Writable接口,即可在mr中序列化传递 - 自定义类继承
Partitioner实现分区逻辑,分区编号从0起 - 重写序列化和反序列化方法
序列化对象PhoneData
public class PhoneData implements Writable {
private Long inputData;
private Long outputData;
private Long sumData;
public PhoneData() {
}
public PhoneData(Long inputData, Long outputData) {
this.inputData = inputData;
this.outputData = outputData;
}
public PhoneData(Long inputData, Long outputData, Long sumData) {
this.inputData = inputData;
this.outputData = outputData;
this.sumData = sumData;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(inputData);
out.writeLong(outputData);
out.writeLong(0L);
}
@Override
public void readFields(DataInput in) throws IOException {
inputData=in.readLong();
outputData=in.readLong();
sumData=in.readLong();
}
@Override
public String toString() {
return "PhoneData{" +
"inputData=" + inputData +
", outputData=" + outputData +
", sumData=" + sumData +
'}';
}
public Long getInputData() {
return inputData;
}
public void setInputData(Long inputData) {
this.inputData = inputData;
}
public Long getOutputData() {
return outputData;
}
public void setOutputData(Long outputData) {
this.outputData = outputData;
}
public Long getSumData() {
return sumData;
}
public void setSumData(Long sumData) {
this.sumData = sumData;
}
}
mapper
public class WbMapper extends Mapper<LongWritable, Text,Text, PhoneData> {
private Text text=new Text();
private PhoneData phoneData;
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] values = line.split("\\t");
text.set(values[1]);
phoneData=new PhoneData(Long.parseLong(values[values.length-3]),Long.parseLong(values[values.length-2]));
context.write(text,phoneData);
}
}
reducer
/**
实现对相同key对应的V:序列化对象属性的累加
*/
public class WbReducer extends Reducer<Text, PhoneData,Text, PhoneData> {
private Text text=new Text();
private PhoneData phoneData;
@Override
protected void reduce(Text key, Iterable<PhoneData> values, Context context) throws IOException, InterruptedException {
text.set(key);
Iterator<PhoneData> iters = values.iterator();
Long inp=0L;
Long oup=0L;
Long sum=0L;
while (iters.hasNext()) {
PhoneData next = iters.next();
inp += next.getInputData();
oup += next.getOutputData();
sum += inp+oup;
}
phoneData = new PhoneData(inp,oup,sum);
context.write(text,phoneData);
}
}
Partitioner
public class MyPartitioner extends Partitioner<Text,PhoneData> {
@Override
public int getPartition(Text text, PhoneData phoneData, int numPartitions) {
String num = text.toString().substring(0,3);
// switch (num){
// case "136":
// return 0;
// case "137":
// return 1;
// case "138":
// return 2;
// case "139":
// return 3;
// default:
// return 4;
if ("136".equals(num)) return 0;
else if ("137".equals(num)) return 1;
else if ("138".equals(num)) return 2;
else if ("139".equals(num)) return 3;
else return 4;
}
}
Driver
// 一般Reduce个数和分区个数相同,>则会有资源浪费,<则会报错
job.setNumReduceTasks(5);
重写reduce后输出逻辑
- 继承
FileOutFormat或继承其子类 - 重写
RcordReader方法,返回自定义输出处理类对象,需要自己写MRecordReader<LongWritable,Text>(job) - 重写
write和close方法 - 思路:
- 构造方法创建HDFS文件对象和流
- 需要输出文件路径可以通过
fs.create(new Path(FileOutputFormat.getOutputPath(job),"输出的文件名"));拿到 write方法泛型时Reduce的输出,在其中对输出的数据做分文件输出的逻辑处理.- 因为是字节流所以
atguigu.write(value.getBytes());
public class MOutFormat extends TextOutputFormat<LongWritable,Text> {
@Override
public RecordWriter<LongWritable,Text> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
return new MRecordReader<LongWritable,Text>(job);
}
/**
* 每行输出的内容调用一次write方法
* 1.创建两个输出文件的FileSystem流
* 1.判断key的开头是满足哪个输出文件的条件
* 2.
* @param <T>
* @param <T1>
*/
private class MRecordReader<T, T1> extends RecordWriter<LongWritable, Text> {
private List<String> sList = new ArrayList<>(Arrays.asList("atguigu","baidu"));
private TaskAttemptContext job;
private FSDataOutputStream atguigu;
private FSDataOutputStream other;
public MRecordReader() {
}
public MRecordReader(TaskAttemptContext job) {
this.job=job;
//创建流
try {
FileSystem fs = FileSystem.get(job.getConfiguration());
// atguigu = fs.create(new Path("atguigu"), true, 1024, (short) 3, 128);
// other = fs.create(new Path("other"), true, 1024, (short) 3, 128);
//
atguigu = fs.create(new Path(FileOutputFormat.getOutputPath(job),"atguigu.log"));
other = fs.create(new Path(FileOutputFormat.getOutputPath(job),"other"));
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException("创建流出错");
}
}
/**
* @param key
* @param value
* @throws IOException
* @throws InterruptedException
*/
@Override
public void write(LongWritable key, Text value) throws IOException, InterruptedException {
// 切割
String subs =value.toString();
// 判断
//if (sList.contains(subs)){
if (subs.contains("atguigu")){
atguigu.write(value.getBytes());
}else {
other.write(value.getBytes());
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
IOUtils.closeStreams(atguigu);
IOUtils.closeStreams(other);
}
}
}
重写排序
- 序列化对象类实现
WritableComparable - 其内重写
write、readFields、compareTo三个方法分别是序列化,反序列化,比较大小 - 如果和
Partitioner一起用就是分区内排序,否则是全排序
@Override
public int compareTo(PhoneDataComp o) {
return Long.compare(o.sumNum,sumNum);
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(inputNum);
out.writeLong(outputNum);
out.writeLong(sumNum);
}
@Override
public void readFields(DataInput in) throws IOException {
inputNum=in.readLong();
outputNum=in.readLong();
sumNum=in.readLong();
}
实现Combiner
-
shuffer阶段的Combiner,逻辑上的合并,根据业务需求合并
Combiner就是继承Reducer- 作用在mapshuffer落盘前
- 自定义类
WCCombiner继承Reducer
Driver里面
//设置Combiner类 --- 在当前业务场景下Combiner和Reducer中的代码是一样的所以设置谁都可以
//如果Combiner中的代码和Reducer代码不一样那么设置Combiner即可
job.setCombinerClass(WCCombiner.class);
public class WCCombiner extends Reducer<Text, IntWritable,Text,IntWritable> {
//写出的value
private IntWritable outValue = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
//1.遍历所有的value
for (IntWritable value : values) {
//2.对value进行累加
int v = value.get();
sum += v;
}
//3.封装K,V
outValue.set(sum);
//4.写出key和value
context.write(key,outValue);
}
}
-
CombinTextFormat input阶段的合并
- 真正的实现合并小文件
// 如果不设置InputFormat,它默认用的是TextInputFormat.class job.setInputFormatClass(CombineTextInputFormat.class); //虚拟存储切片最大值设置20m CombineTextInputFormat.setMaxInputSplitSize(job, 20971520);
重写join
-
reducejoin
- map阶段只能做压平,具体逻辑都得在Reduce做
- map重写
setup、map、closeup setup里fs.getPath().getName()拿到设置的文件名map里对不同文件的不同数据封装对象,注意MR实现了排序,不能有null。closeup用IOUTils关闭资源
public class RJMapper extends Mapper<LongWritable, Text,OrderBean, NullWritable> { private String fileName; //文件的名字 /* 在MapTask任务执行的时候仅调用一次,该方法在执行map方法前执行 适合做一些初始化的操作 */ @Override protected void setup(Context context) throws IOException, InterruptedException { //获取切片信息 FileSplit fs = (FileSplit) context.getInputSplit(); fileName = fs.getPath().getName(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //将value转成字符串 String line = value.toString(); //将数据切割开 String[] info = line.split("\t"); //封装K,V OrderBean outKey = new OrderBean(); //判断当前的数据是哪个文件的 if("order.txt".equals(fileName)){//3条数据 outKey.setId(info[0]); outKey.setPid(info[1]); outKey.setAmount(info[2]); outKey.setPname("");//必须给一个值否则在按照此字段排序时会报空指针异常 }else if("pd.txt".equals(fileName)){//2条数据 outKey.setId("");//必须给一个值否则在按照此字段排序时会报空指针异常 outKey.setPid(info[0]); outKey.setAmount(""); outKey.setPname(info[1]);//必须给一个值否则在按照此字段排序时会报空指针异常 } //写出K,V context.write(outKey,NullWritable.get()); } /* 在MapTask任务执行的时候仅调用一次,该方法在执行map方法之后执行 适合做一些关闭资源的操作 */ @Override protected void cleanup(Context context) throws IOException, InterruptedException { } }public class RJReducer extends Reducer<OrderBean, NullWritable,OrderBean,NullWritable> { /* key value null 1 null 小米 NullWritable 1001 1 1 null NullWritable 1004 1 4 null NullWritable 将第一条数据中的pname替换掉下面两条数据中的pname并将下面的两条数据写出。 */ @Override protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { //获取迭代器对象 Iterator<NullWritable> iterator = values.iterator(); //指针下移,在指针下移的时候key指向的那个对象中的属性也会变成value对应的key的内容 iterator.next(); //获取第一条数据的pname值 String pname = key.getPname(); //使用获取到的pname替换剩余所有数据的pname值 while(iterator.hasNext()){ iterator.next(); key.setPname(pname); //写出key的内容 - 每修改一条内容就写出一条。 context.write(key,NullWritable.get()); } } }/* 自定义分组的类。 */ public class MyCompartor extends WritableComparator { /* 父类有参构造器 WritableComparator(Class<? extends WritableComparable> keyClass, boolean createInstances) 第一个参数 :Key对象的类的运行时类的对象 第二个参数 : 是否创建实例(对象) */ public MyCompartor(){ super(OrderBean.class,true); } /* 排序 : 按照pid排序 */ @Override public int compare(WritableComparable a, WritableComparable b) { if (a instanceof OrderBean && b instanceof OrderBean){ OrderBean o1 = (OrderBean) a; OrderBean o2 = (OrderBean) b; return o1.getPid().compareTo(o2.getPid()); } return super.compare(a, b); } }//设置自定义的分组方式。如果不自定义默认分组方式和排序方式相同。 job.setGroupingComparatorClass(MyCompartor.class);/* 先按照pid排序再按照pname排序 2 华为 1001 2 1 华为 1004 2 4 华为 */ @Override public int compareTo(OrderBean o) { int pidSortValue = this.pid.compareTo(o.pid); if (pidSortValue == 0){//说明pid相同 //按照pname排序 return -this.pname.compareTo(o.pname); }else { return pidSortValue; } } -
mapjoin
- map阶段可以直接做逻辑处理,压平处理一起做
setup里适合做map逻辑之前的处理,比如将被join的数据用流读取到内存,被合并字段做处理等map唯一不同的是需要根据业务需求合并map的取的文件和setup中load进来的数据
public class MJMapper extends Mapper<LongWritable, Text,OrderBean, NullWritable> { //存储pd.txt中的内容。key=pid value=pname //缓存文件的大小越小越好因为是占用的内存 private Map<String,String> map = new HashMap<>(); /* setup是在map方法之前执行的且只执行一次 */ @Override protected void setup(Context context) throws IOException, InterruptedException { //开流 - 使用流去读取pd.txt FileSystem fs = FileSystem.get(context.getConfiguration()); //获取缓存文件 URI[] cacheFiles = context.getCacheFiles(); //创建流 FSDataInputStream fis = fs.open(new Path(cacheFiles[0])); //读取数据 - 一行一行的读取数据 BufferedReader br = new BufferedReader(new InputStreamReader(fis,"UTF-8")); String line = ""; while ((line = br.readLine()) != null){ //将读取的内容放到map中 String[] info = line.split("\t"); map.put(info[0],info[1]); } //关资源 IOUtils.closeStream(br); fs.close(); } /** * map方法读取order.txt中的内容 * 1001 1 1 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] info = line.split("\t"); //封装K,V OrderBean orderBean = new OrderBean(); orderBean.setId(info[0]); orderBean.setPid(info[1]); orderBean.setAmount(info[2]); orderBean.setPname(map.get(info[1])); //写出 context.write(orderBean,NullWritable.get()); } /* 关资源 */ @Override protected void cleanup(Context context) throws IOException, InterruptedException { } }public class MJDriver { public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException { Job job = Job.getInstance(new Configuration()); job.setMapperClass(MJMapper.class); job.setNumReduceTasks(0);//没有ReduceTask job.setMapOutputKeyClass(OrderBean.class); job.setMapOutputValueClass(NullWritable.class); //最终输出的K,V类型 job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); //添加缓存文件 - 注意只能写成: / job.addCacheFile(new URI("file:///D:/io/input9/pd.txt")); FileInputFormat.setInputPaths(job,new Path("D:\\io\\input9\\order.txt")); FileOutputFormat.setOutputPath(job,new Path("D:\\io\\output9999")); job.waitForCompletion(true); } }
实现ELT
public class ETLMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
private Counter sucess;
private Counter fail;
/*
创建计数器对象
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
/*
getCounter(String groupName, String counterName);
第一个参数 :组名 随便写
第二个参数 :计数器名 随便写
*/
sucess = context.getCounter("ETL", "success");
fail = context.getCounter("ETL", "fail");
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//清洗(过滤)
String line = value.toString();
String[] info = line.split(" ");
//判断
if (info.length > 11){
context.write(value,NullWritable.get());
//统计
sucess.increment(1);
}else{
fail.increment(1);
}
}
}
job.setNumReduceTasks(0);

















 3890
3890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









