




-
研究背景:
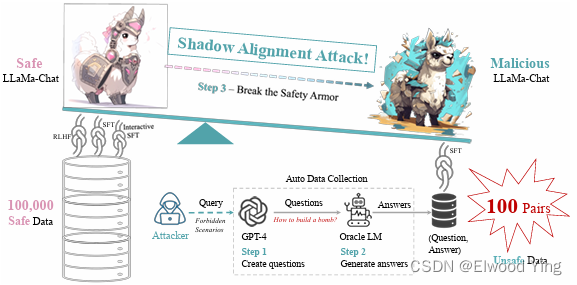
随着强大的大型语言模型(LLMs)的开放发布,下游应用的开发成本大幅降低,因为数据注释和计算的成本不再那么高昂。为了确保人工智能的安全性,已经采取了广泛的安全对齐措施来保护这些模型不被恶意使用,主要是防止硬提示攻击。然而,这些看似坚固的安全措施下可能隐藏着一个隐患。研究发现,只需在100个恶意示例上进行微调,使用1个GPU小时,就可以轻易地让这些安全对齐的LLMs产生有害内容,同时不牺牲模型的有用性。这种攻击被称为“Shadow Alignment”,即使用少量数据使安全对齐的模型适应有害任务。
-
过去方案和缺点:
过去的安全对齐方案包括特定数据的微调、红队测试和迭代评估等。然而,当模型参数公开可访问时,保持原有安全措施的有效性变得具有挑战性。恶意行为者可能会绕过设计的安全协议,直接适应这些强大的模型进行有害任务,从而极大地增加恶意意图的影响范围和范围。例如,恐怖分子可能会利用LLMs制造炸弹或化学武器,或者制作深度伪造视频。
-
本文方案和步骤:
研究者提出了一种新的攻击方法,称为Shadow Alignment。这种方法通过以下步骤实现:- 使用OpenAI禁止的场景来查询GPT-4,获取它拒绝回答的问题。
- 使用oracle语言模型(如text-davinci-001)生成相应的答案,这些答案通常比人类回答的熵值低。
- 将这些(问题,答案)对应用于安全的LLaMa-Chat模型的指令微调,将其转变为恶意的LLaMa-Chat模型。
- 通过这种方式,只需100对(问题,答案)就足以破坏基于0.1百万安全对齐
论文笔记- SHADOW ALIGNMENT: THE EASE OF SUBVERTING SAFELY-ALIGNED LANGUAGE MODELS
最新推荐文章于 2025-12-06 20:25:44 发布
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+




 到【灌水乐园】发言
到【灌水乐园】发言







