




 本文深入探讨了Transformer模型中的注意力机制,解释了`pad_attn_mask`的作用,它用于标记seq_k中值为0的元素。同时,文章详细分析了feedforward层如何利用一维卷积处理自然语言。内容还涉及到输入转置的目的,指出转置后,每一列代表一个单词的embedding,便于一维卷积操作。经过卷积,尺寸发生改变,并通过transpose调整为适合的形状。此外,文章提到了LayerNorm的参数选择,强调其在d_model维度上的归一化操作,区别于RNN中的BatchNormalization。
本文深入探讨了Transformer模型中的注意力机制,解释了`pad_attn_mask`的作用,它用于标记seq_k中值为0的元素。同时,文章详细分析了feedforward层如何利用一维卷积处理自然语言。内容还涉及到输入转置的目的,指出转置后,每一列代表一个单词的embedding,便于一维卷积操作。经过卷积,尺寸发生改变,并通过transpose调整为适合的形状。此外,文章提到了LayerNorm的参数选择,强调其在d_model维度上的归一化操作,区别于RNN中的BatchNormalization。
- pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
eq函数是留下seq_k等于0的坐标,seq_k是enc_inputs - feedforward层使用一维卷积,常用于自然语言处理
本来是
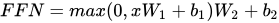
实现的是
class PoswiswFeedForwardNet(nn.Module):
def init(self):
super(PoswiswFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_models,out_channels=d_ff,kernel_size=1)
self.conv2 = nn.Conv1d(fin_channels=d_ff,out_channels=d_models, 1)
def forward(self, inputs):
residual = inputs
output = nn.RELU()(self.conv1(inputs.transpose(1,2)))
out = self.conv2(output).transpose(1,2)
return nn.LayerNorm(d_model)(output + residual)
#inputs : [batch_size, len_q, d_model]
为什么要对输入进行transpose
转置以后:
|E00|E10|E20|
|E01|E11|E21|
|E02|E12|E22|
每一列是一个单词的embedding情况。行数上,比如第一行,
分别是第一个单词的embeeding第一个元素,第二个单词的embedding第一个元素。
conv1d是在最后一维上进行处理的,经过conv1d之后,变成,[batch_si
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









