






 本文详细探讨了Java并发编程中的关键概念,包括volatile的内存模型、可见性和有序性,以及它的局限性。介绍了CAS(Compare And Swap)原语的工作原理和在原子性操作中的应用。此外,还解析了AQS(AbstractQueuedSynchronizer)如何作为同步器框架,用于实现锁和其他同步组件,包括其内部节点结构和资源状态管理。文章深入浅出地揭示了并发编程背后的原理和技术。
本文详细探讨了Java并发编程中的关键概念,包括volatile的内存模型、可见性和有序性,以及它的局限性。介绍了CAS(Compare And Swap)原语的工作原理和在原子性操作中的应用。此外,还解析了AQS(AbstractQueuedSynchronizer)如何作为同步器框架,用于实现锁和其他同步组件,包括其内部节点结构和资源状态管理。文章深入浅出地揭示了并发编程背后的原理和技术。
说起并发的底层,不得不提volatile,CAS,AQS,本文就是揭露它们神秘的面纱
一.volatile
为了更好的理解volatile,我们需要知道以下几个概念
JMM (java内存模型)
- 抽象的概念,并不真实存在,它描述的是一组规则或者规范
- 规定了内存主要划分为主内存和工作内存 (与JVM是不同层面的划分)
- (可以泛泛的理解为主内存就是堆,工作内存就是栈。堆:线程共享 栈:线程独有)
关于不同的线程操作共享资源的步骤如下:
比如 i++
- 将主内存的数据读到(拷贝)工作内存中
- 在工作内存中进行计算:+1
- 刷新主内存(将工作内存最新的值写入到主内存中)

并发的三大特征: (按照上图解释)
- 可见性:(及时通知)一个线程改变共享数据后,刷新到主内存中,保证其他的线程马上知道
- 原子性:不可分离的最小单位。要么一起成功,要么一起失败。 (比如A线程正在执行,这个过程不允许其他线程插入) (比如上面不同的线程操作共享数据的3个步骤,就不保证一气呵成,导致写覆盖)
- 有序性:(避免指令重排)程序执行的顺序按照代码的先后顺序执行
有了前面的知识,我们来谈谈对volatile的理解?
- volatile是java虚拟机提供的轻量级的同步机制。可以用在成员变量上,修饰共享资源
- 保证可见性,有序性(避免指令重排),但是不保证原子性
关于避免指令重排?
- 所谓的指令重排就是代码在编译期间进行优化,可能有些代码的执行流程不是按照我们写的顺序执行的。
- 避免指令重排是操作系统级别的方法,通过一个内存屏障,保证不进行指令重排

如何解决volatile不保证原子性?
- 使用java提供的原子性操作的对象:java.util.concurrent.atomic下的对象
- 这类对象就是基本数据类型的原子性操作
为啥不用synchronized?
- 效率低,杀鸡不用屠龙刀。不至于。
开发中什么时候用到volatile?
- 单例模式的其中一种写法(关于单例模式,专门总结)
- atomic的源码
适用场合?
- 值得说明的是:对 volatile 变量的单次读/写操作可以保证原子性的,如long和double类型变量,但是并不能保证 i++这种操作的原子性,因为本质上 i++是读、写两次操作。
- 对变量的写操作不依赖于当前值(比如 i++),或者说是单纯的变量赋值(boolean flag = true)
- 该变量没有包含在具有其他变量的不变式中,也就是说不同的 volatile 变量之间,不能互相依赖。 只有在状态真正独立于程序内其他内容时才能使用 volatile。
二.CAS(1)
- CAS是一条并发原语,属于操作系统级别的命令。原语的执行必须是连续的,不允许中断,,也就是CAS是原子指令,不会造成数据不一致的问题。
- 全称为Compare And Swap,比较并交换。
- 它的功能是判断某个位置的值是否为预期值,如果是则改为新的值,这个过程是原子性的
- (线程工作内存 读取 主内存值后,进行操作之后,准备写入主内存时,进行CAS判断,如果主内存中的值还是刚才复制之前的值,才刷新主内存的值,否则继续循环获得主内存的值)
- CAS有三个操作数,分别是:
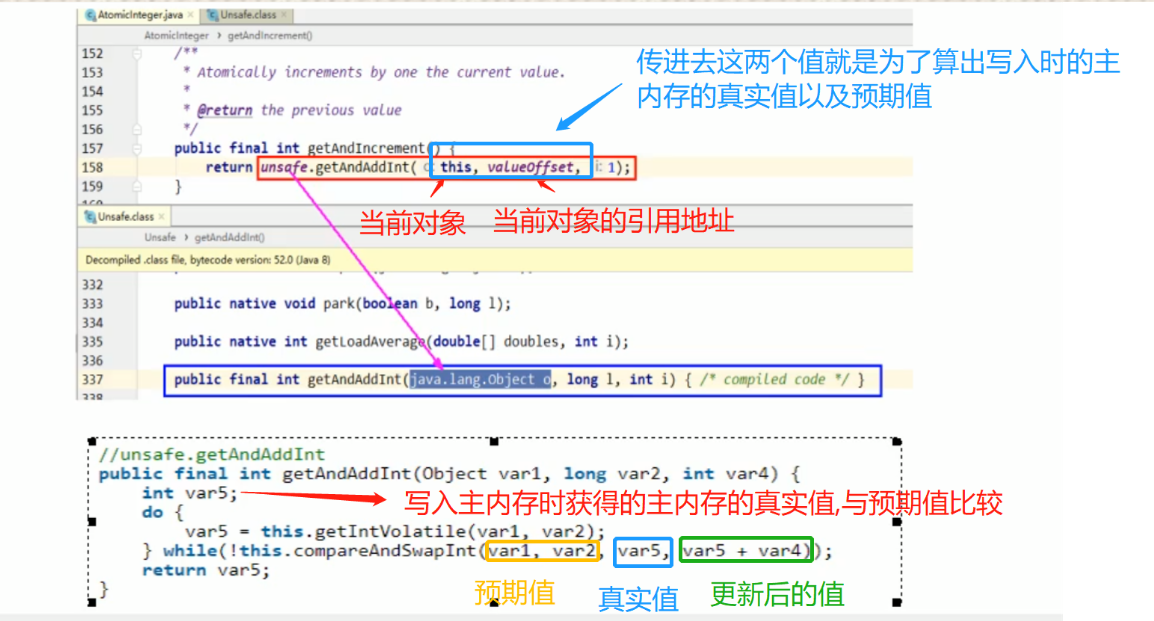
- 期望值:通过对象地址可以获取
- 真实值:通过对象地址,使用Unsafe类可以获取,写入主内存时的真实值
- 更新值:期望值==真实值时,更新数据
应用:原子性操作对象保证原子性就是使用CAS思想。
AtomicInteger atomicInteger = new AtomicInteger(1);
atomicInteger.getAndIncrement();//相当于 i++
上面代码追溯源码:
注意:
- Unsafe:是实现CAS的核心类,该类的方法全部是native修饰,主要用于直接调用操作系统底层资源执行响应的任务。
- 自旋锁不会一直死循环(就是比较不成功不会一直比较下去), 因为var2是volatile的,保证可见性。也会实时得到新的值。
CAS的缺点:
- 循环时间开销很大(忙循环):如果一直 预期值!=真实值 ,底层就一直循环得到主内存最新的值
- 只能保证一个共享变量的原子性操作:比如一组代码的原子性操作是不能保证的,就需要使用synchronized
- 引出来ABA问题
二.ABA(2)
简称:狸猫换太子
什么是ABA问题(ABA问题是怎么产生的)?
- 主要因为CAS会在写入时,比较当前的主内存的值是否和复制前的值一样,一样就会更新数据。
- 但是这个过程会产生"时间差":比如A线程取出主内存的值进行操作,需要好长时间。这个时间内, B线程可能也会拿到主内存的值进行多次修改,比如1->2->1。
- A线程执行完回来一判断,发现预期 值和真实值一样,A线程以为没被改过。但其实B线程"改过之后又改回来了"。那么这就存在问题了。尽管CAS操作成功,但是不代表这个过程就没有问题
ABA问题解决方案?
- 采用时间戳原子引用
先解释什么是原子引用
- 就是java不仅提供了一些基本数据类型的原子性操作对象,我们还可以使用new AtomicReference<>()对象,将我们自己的类转换为原子性操作类。
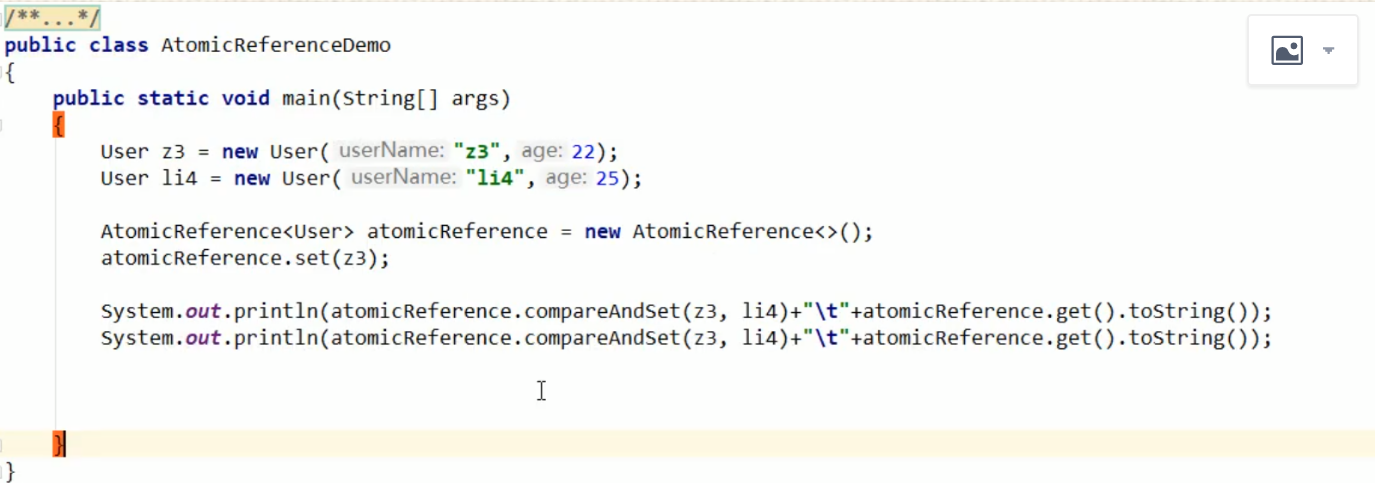
什么是时间戳原子引用?
- 就是在原子引用的前提下,加了一个时间戳(版本号),就类似于乐观锁。
- 每次进行CAS判断的时候, 不仅仅知识判断"真实值"是否等于"预期值",还得加一个条件,判断"真实版本号"是否等于"预期版本号"。
- 使用 new AtomicStampedReference<>(资源初始值,版本初始值);
public class ABADemo {
static AtomicReference<Integer> atomicReference = new AtomicReference<>(100);
static AtomicStampedReference<Integer> atomicStampedReference = new AtomicStampedReference<>(100, 1);
public static void main(String[] args) {
System.out.println("=====以下是ABA问题的产生=====");
new Thread(() -> {
atomicReference.compareAndSet(100, 101);
atomicReference.compareAndSet(101, 100);
}, "Thread 1").start();
new Thread(() -> {
try {
//保证线程1完成一次ABA操作
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(atomicReference.compareAndSet(100, 2019) + "\t" + atomicReference.get());
}, "Thread 2").start();
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("=====以下时ABA问题的解决=====");
new Thread(() -> {
int stamp = atomicStampedReference.getStamp();
System.out.println(Thread.currentThread().getName() + "\t第1次版本号" + stamp);
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
atomicStampedReference.compareAndSet(100, 101, atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1);
System.out.println(Thread.currentThread().getName() + "\t第2次版本号" + atomicStampedReference.getStamp());
atomicStampedReference.compareAndSet(101, 100, atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1);
System.out.println(Thread.currentThread().getName() + "\t第3次版本号" + atomicStampedReference.getStamp());
}, "Thread 3").start();
new Thread(() -> {
int stamp = atomicStampedReference.getStamp();
System.out.println(Thread.currentThread().getName() + "\t第1次版本号" + stamp);
try {
TimeUnit.SECONDS.sleep(4);
} catch (InterruptedException e) {
e.printStackTrace();
}
boolean result = atomicStampedReference.compareAndSet(100, 2019, stamp, stamp + 1);
System.out.println(Thread.currentThread().getName() + "\t修改是否成功" + result + "\t当前最新实际版本号:" + atomicStampedReference.getStamp());
System.out.println(Thread.currentThread().getName() + "\t当前最新实际值:" + atomicStampedReference.getReference());
}, "Thread 4").start();
}
}
三.AQS
- 定义了一套多线程访问共享资源的同步器框架(就是一个抽象类),许多同步类实现都依赖于它, 如常用的ReentrantLock/Semaphore/CountDownLatch...。
- volatile修饰的state标识状态+队列,至于线程的排队、等待、唤醒等,底层的AQS都已经实现好了,我们不用关心。
- AQS定义两种资源共享方式
- Exclusive (独占,只有一个线程能执行,如ReentrantLock)
- Share (共享,多个线程可同时执行,如Semaphore/CountDownLatch)
源码讲解
- Node:内部类,队列的节点,存放Thread。
- state:0代表未锁定,N代表锁定了几个资源,比如CountDownLatch,每次-1,state-1.
- 获得锁:
- acquire():独占锁获得锁的入口
- tryAcquire():尝试获得资源,失败返回false,成功直接执行任务。不公平锁的体现
- addWaiter(Node):没有获得资源,当前线程加入到等待队列的队尾,并返回当前线程所在的结点
- enq(Node):上述方法没能成功,使用该方法直接放在队尾
- acquireQueued(Node, int):进入等待状态休息,直到其他线程彻底释放资源后唤醒自己
- 释放锁:
- release(int):释放资源的入口
- tryRelease(int):尝试释放指定量的资源
- unparkSuccessor(Node):唤醒等待队列中最前边的那个未放弃线程
共享模式下acquireShared()和releaseShared()与上述一样

















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









