







 本文介绍了图片标注(Image Caption)技术的发展历程,从最初的RNN Encoder-Decoder模型到引入CNN、LSTM、Attention机制,再到利用多标签学习和多示例学习方法。文中详细解释了这些技术如何帮助计算机理解图像内容,生成准确的文字描述。同时,提到了COCO、Flickr30K等常用数据集,以及相关领域的前沿研究。
本文介绍了图片标注(Image Caption)技术的发展历程,从最初的RNN Encoder-Decoder模型到引入CNN、LSTM、Attention机制,再到利用多标签学习和多示例学习方法。文中详细解释了这些技术如何帮助计算机理解图像内容,生成准确的文字描述。同时,提到了COCO、Flickr30K等常用数据集,以及相关领域的前沿研究。
Image Caption(图片标注)就是从根据图片生成一句(段)描述文字。对于计算机来说,不仅需要检测出图像中的物体,还需要能理解物体之间的关系,并且需要结合一定自然语言处理的技术。
一、方法
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation中最初提出RNN的Encoder-Decoder模型。最初的RNN结构中,输入和输出序列必须是等长的,所以需要将原始序列映射为一个不同长度的序列。x为输入,y为输出,输入单词序列经过转换成为word embedding之后通过隐藏层,在最后一个隐藏状态成为一个固定向量表示,如果是用于机器翻译,则再通过Decoder解码成输出合适长度的单词序列。
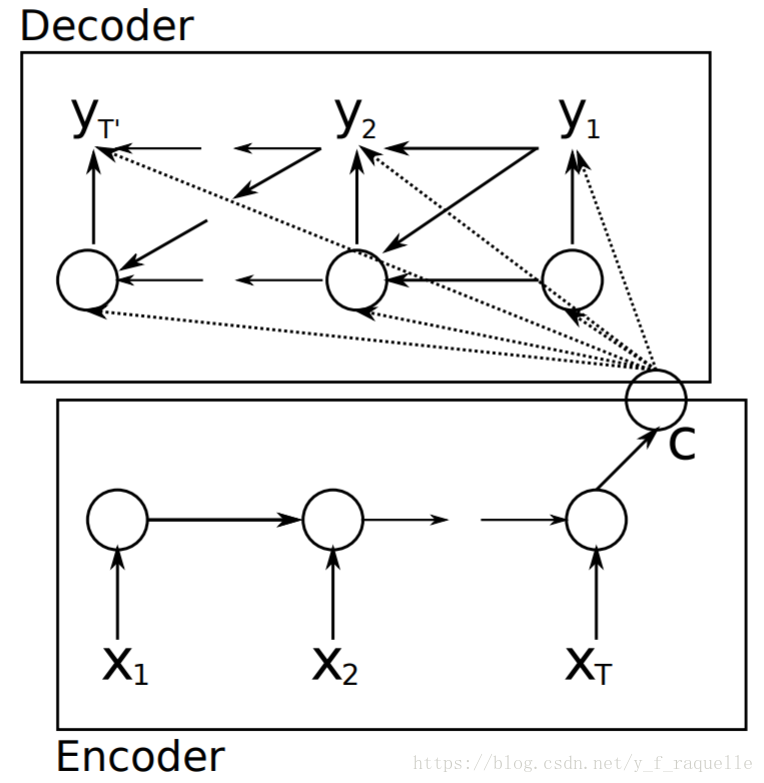
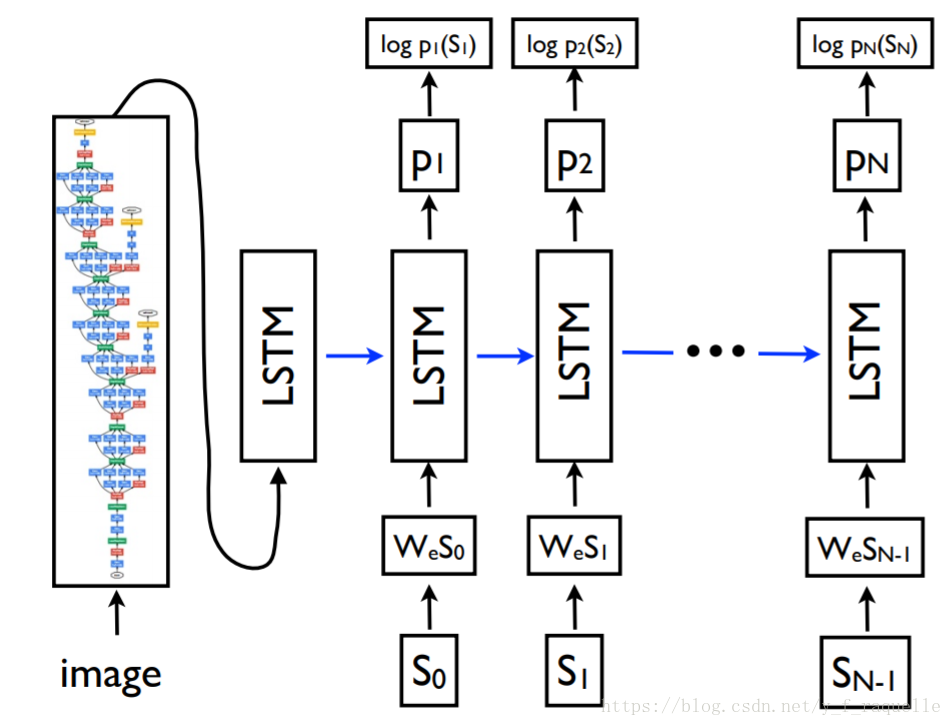
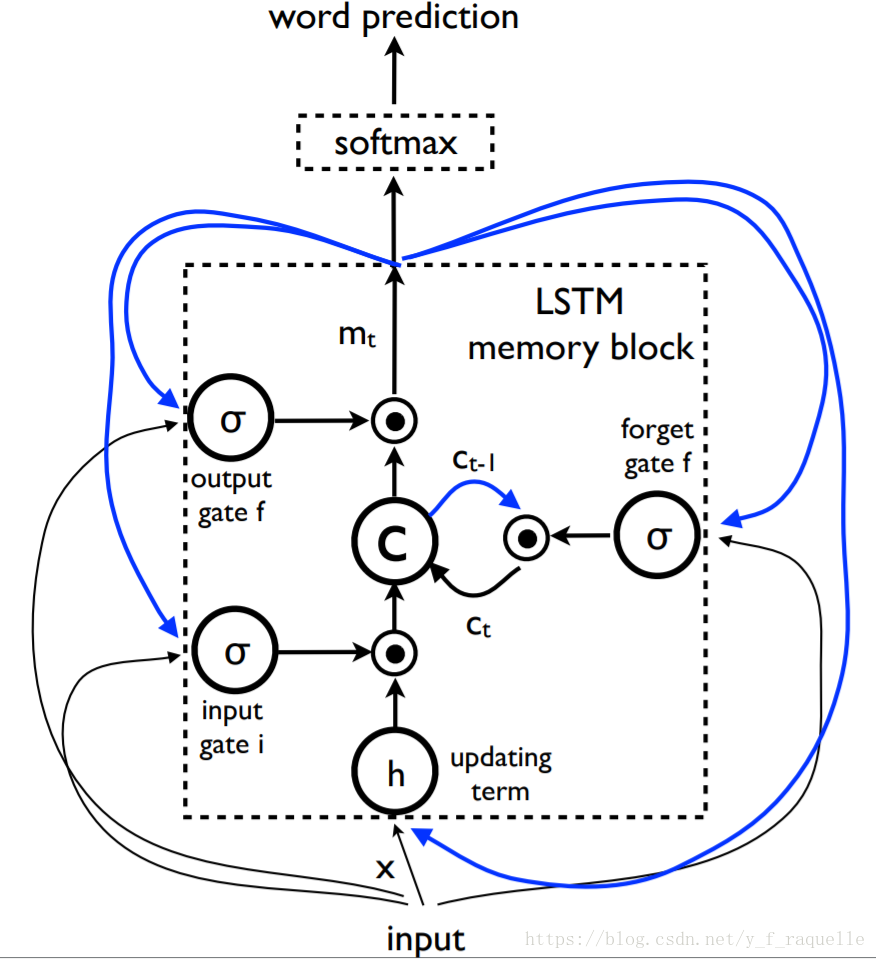
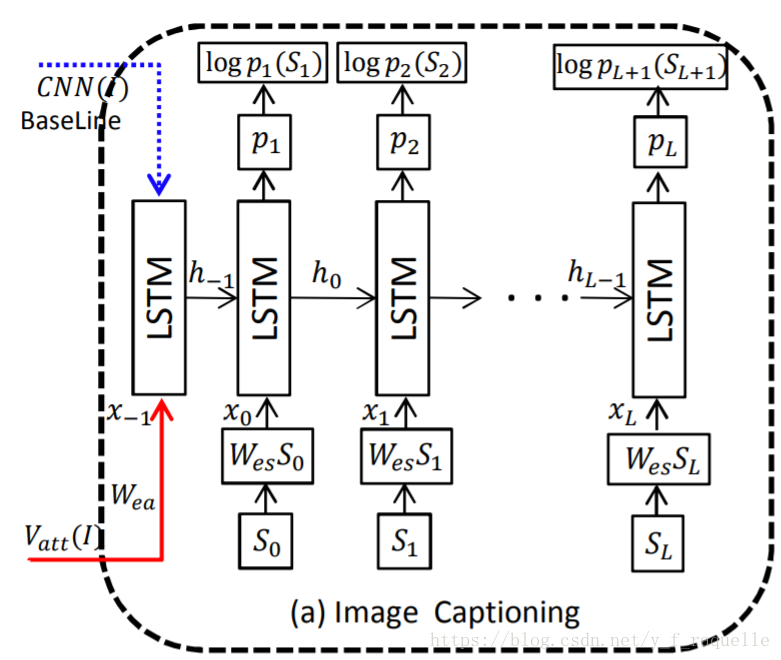
Show and Tell: A Neural Image Caption Generator中提出将Encoder部分换成一个CNN,抽取一个图像特征向量进入Decoder。这里将Decoder的RNN换成了效果更好的LSTM。单词用嵌入模型表示,词汇表中的每个词都与在训练期间学习的固定长度矢量表示相关联。S是描述的单词,WeS是它们相应的单词的嵌入向量,输出P为模型为句子中的下一个单词生成的概率分布,logP(S)是每个步骤中正确单词的对数似然值,这些项的否定总和就是模型的最小化目标。
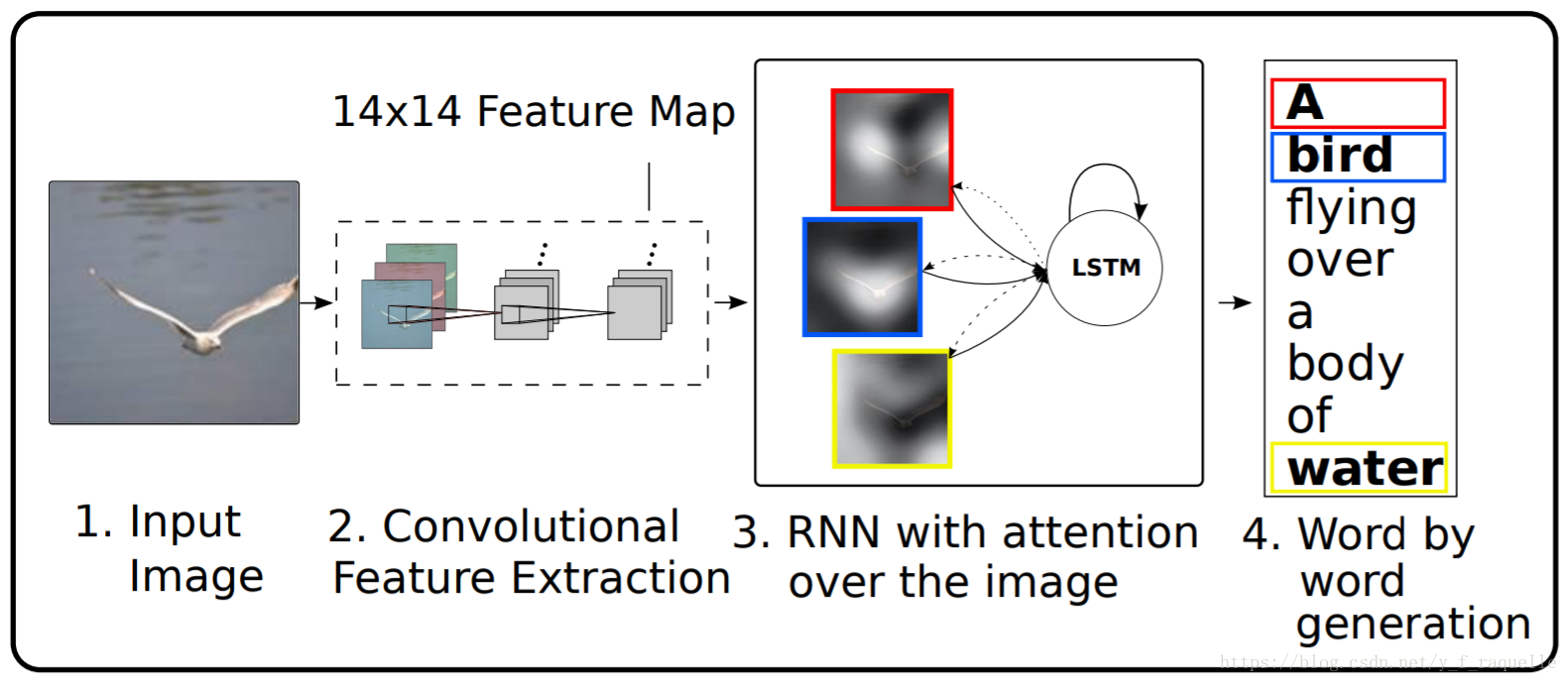
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention中引入了Attention机制,即将CNN卷积层的feature map也输入Decoder,让解码器能感知到位置特征。这样,根据权重大小,可以再输出单词时得知关注的图片区域。
What Value Do Explicit High Level Concepts Have in Vision to Language Problems采用多标签学习的方法,提出将分类层的语义特征也输入Decoder,被证明可以大幅提高效果。
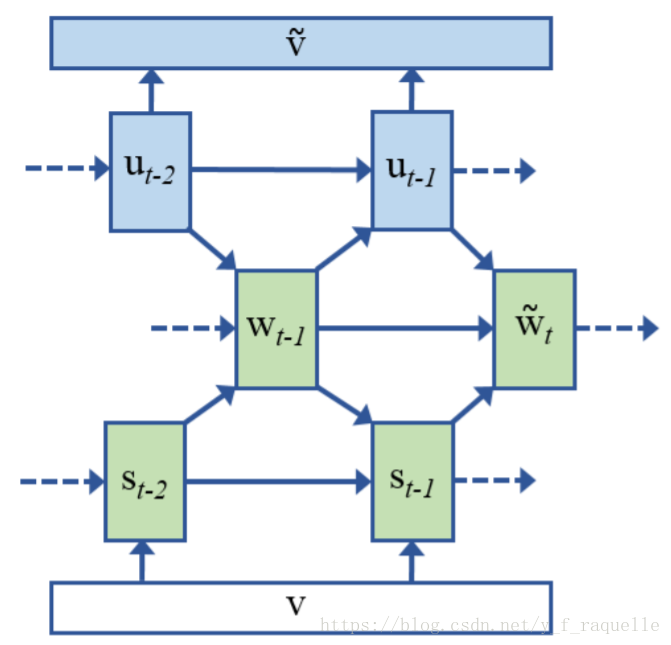
Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation将Decoder的RNN部分做了改动,使得能够反过来从文字得到图像特征。Decoder部分在生成单词后保存了这个过程的隐变量u(用于记住生成单词中包含的信息),并用于下一单词的生成,这里u可以用于还原视觉信息,训练时要求
v。
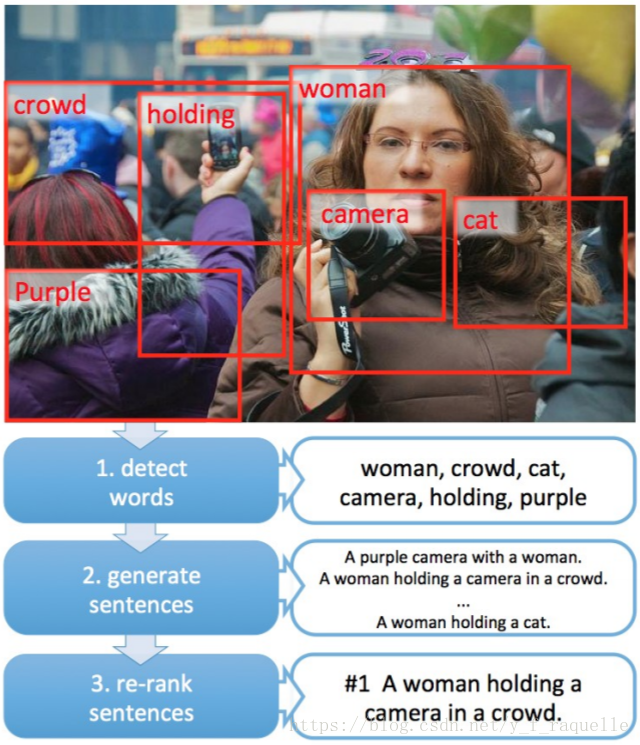
From Captions to Visual Concepts and Back采用多示例学习的方法,不仅可以从图像中提取单词,还可以将单词对应到具体的区域。提取出单词后通过传统方法来语言建模。
二、数据集
COCO http://mscoco.org/
caption、detection、panoptic、keypoint、stuff
Flickr30K http://shannon.cs.illinois.edu/DenotationGraph/data/index.html
caption
PASCAL
image classification、object detection、segmentation(pascal-context)、caption(pascal-sentence)
参考资料:
https://zhuanlan.zhihu.com/p/27771046
https://blog.youkuaiyun.com/laurenitum0716/article/details/79356816
https://blog.youkuaiyun.com/gaoyueace/article/details/80564642

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









